A gentle introduction to XML Schema
and XML document grammars
Universitetet i Bergen
HIT-senteret
C. M. Sperberg-McQueen
26 October 2001
Abstract
In the historical development of markup languages, few innovations
have been more important than the introduction of the notion of
document grammars for constraining documents and defining document
types. Document grammars provide a simple, easily understood method
of specifying rules for the validity of XML documents. By helping
keep data clean, they make it easier to write simpler, more reliable
software.
Both SGML (ISO 8870) and XML 1.0 define a specialized notation (the
DTD) for defining document grammars; more recently a number of
alternative languages have been proposed. The W3C XML Schema language
replicates the essential functionality of DTDs, and adds a number of
features: the use of XML instance syntax rather than an ad hoc
notation, clear relationships between schemas and namespaces, a
systematic distinction between element types and data types, and a
single-inheritance form of type derivation.
This presentation will outline some of the fundamental features of
document grammars for XML, and at the same time introduce the basics
of the W3C XML Schema 1.0 language. Some fundamental design issues of
schema languages will be discussed, together with the choices made by
the W3C group in defining XML Schema.
- I.1. Overview
- II.1. Some models of text
- II.2. Tree-shaped models
- II.3. Models of marked-up text
- II.4. Pseudo-grammars
- II.5. Document grammars (DGs)
- II.6. The uses of DGs
- III.1. DTDs as DGs
- III.2. Example: limericks
- III.3. ... and canzone
- III.4. A document grammar
- III.5. A DTD
- III.6. A limerick
- III.7. Walther
- III.8. Note on the poem DTD
- III.9. Removing non-terminals
- III.10. The canzone minus explicit Aufgesang
- IV.1. Overview
- IV.2. XML Schema
- IV.3. The canzone schema v.1
- IV.4. Declaring elements
- IV.5. Declaring elements
- IV.6. Repeated elements
- IV.7. Character data
- V.1. Overview
- V.2. Supporting programming-language and dbms paradigms
- V.3. The tag/type distinction
- V.4. The tag/type distinction
- V.5. The tag/type distinction
- V.6. Top-level named types
- V.7. Top-level complex types
- V.8. Anonymous types
- V.9. Simple datatypes
- V.10. Built-in primitive datatypes
- V.11. Built-in derived datatypes
- V.12. Hierarchy of simple types
- V.13. What is an atomic type?
- V.14. What is an atomic type? (2)
- V.15. What is an atomic type? (3)
- V.16. Non-atomic simple types
- VI.1. Overview
- VI.2. An example
- VI.3. Annotation language
- VI.4. A DTD
- VI.5. A schema for annotation
- VI.6. The type feature
- VI.7. The type featureSet
- VI.8. The word element
- VII.1. Overview
- VII.2. Some design problems
- VII.3. Inheritance
- VII.4. Inheritance in TEI
- VII.5. Inheritance Type derivation
- VII.6. Schema layers
- VII.7. Schemas and namespaces
- VII.8. Modularization
- VII.9. Linking document and schema
- VII.10. Post-schema-validation infoset (PSVI)
I. Overview
I.1. Overview
- the idea of document grammars
- DTDs as document grammars (example)
- XML Schema: replicating DTDs
- XML Schema: types
- another example
- design issues and research questions
II. The idea of document grammars
II.1. Some models of text
- Rectangular:
text ::= record record ::= CHAR* // or CHAR{80}(Card images) - Linear
text ::= CHAR*
(Stream editors)
II.2. Tree-shaped models
- Unlabeled tree:
text ::= node* node ::= node* | CHAR*
(Engelbart's NL/Augment) - Fixed-depth, fixed-label tree:
text ::= page* page ::= line* line ::= CHAR*
(Tustep)
II.3. Models of marked-up text
- ODTAO:
text ::= (CHAR | COMMAND)*
(Many, many programs.) This only looks regular. - Virtual variables:
command ::= '<' CHAR value '>'
(COCOA, OCP, Tact)
II.4. Pseudo-grammars
- Pseudo-grammars:
command ::= '\begin{' NAME '}' | '\end{' NAME '}'command ::= ':' NAME '.'? | ':e'' NAME '.'?command ::= '<' NAME attributes '>' | '</'' NAME '>'(Scribe, GML, LaTeX)
II.5. Document grammars (DGs)
Origin pragmatic, not theoretical.
Later aligned (partially) with language theory.
Formal specification of rules → automated validation.
(Cf. Algol vs. Fortran.)
Document type definition (DTD) is
“the set of rules ...”. N.B.
DTD ≠ “set of effective formal declarations”.
II.6. The uses of DGs
Document grammars may have several uses:
- in the struggle against dirty data
- as documentation of a contract between data provider and data consumer
- as documentation of the content of data flows
- as specification of client/server protocols
III. An example: DTDs as document grammars
III.1. DTDs as DGs
DTDs resemble Backus-Naur Form grammars, but:
- They describe ‘bracketed’ languages* ...
- ... so ‘non-terminals’ are visible*.
- SGML allows inclusion and exclusion exceptions (Rizzi: NP-complete parsing problem for non-bracketed L).
- They are not purely grammatical (notations, entities).
- Determinism rule (LL(1) requirement).
III.2. Example: limericks
Consider two kinds of poem. The limerick:
There was a young lady named Bright
whose speed was much faster than light.
She set out one day,
in a relative way,
and returned on the previous night.
III.3. ... and canzone
Under der linden an der heide,
dâ unser zweier bette was,
dâ muget ir vinden schône beide
gebrochen bluomen unde gras.
vor dem walde in einem tal,
tandaradei,
schône sanc diu nahtegal.
III.4. A document grammar
Limericks and canzone:
poem ::= limerick | canzone
limerick ::= trimeter trimeter dimeter
dimeter trimeter
trimeter ::= CHAR+
dimeter ::= CHAR+
canzone ::= aufgesang abgesang
aufgesang ::= stollen stollen
stollen ::= line+
abgesang ::= line+
III.5. A DTD
Limericks and canzone:
<!ELEMENT poem (limerick | canzone) >
<!ELEMENT limerick (trimeter, trimeter,
dimeter, dimeter,
trimeter)>
<!ELEMENT trimeter (#PCDATA)>
<!ELEMENT dimeter (#PCDATA)>
<!ELEMENT canzone (aufgesang, abgesang) >
<!ELEMENT aufgesang (stollen, stollen) >
<!ELEMENT stollen (l+) >
<!ELEMENT abgesang (l+) >
<!ELEMENT l (#PCDATA) >
III.6. A limerick
<poem>
<limerick>
<trimeter>
There was a young lady named Bright
</trimeter>
<trimeter>
whose speed was much faster than light.
</trimeter>
<dimeter>She set out one day,</dimeter>
<dimeter>in a relative way,</dimeter>
<trimeter>
and returned on the previous night.
</trimeter>
</limerick>
</poem>
III.7. Walther
<poem>
<canzone>
<aufgesang>
<stollen>
<l>unter den linden an der heide</l>
<l>da unser zweier bette was</l>
</stollen>
<stollen>
<l>da mugt ir vinden schone beide</l>
<l>gebrochen bluomen unde gras</l>
</stollen>
</aufgesang>
<abgesang>
<l>kuste er mich? wol tusentstunt</l>
<l>tandaradei</l>
<l>seht wie rot mir ist der munt</l>
</abgesang>
</canzone>
</poem>
III.8. Note on the poem DTD
- All the non-terminals show up as tags.
- The trimeter and dimeter lines should scan with 2 and 3 dactyls; this rule is not expressed.
- The two Stollen must have same number of lines; this rule is not expressed.
- The Abgesang must have more lines than a Stollen, fewer than Aufgesang; this rule is not expressed.
- No grammar detects the errors in the previous example.
III.9. Removing non-terminals
<!ENTITY % aufgesang "stollen, stollen" > <!ENTITY % lines "l+" > <!ELEMENT canzone (%aufgesang;, abgesang) > <!ELEMENT stollen (%lines;) > <!ELEMENT abgesang (%lines;) > <!ELEMENT l (#PCDATA) >
This allows the DTD to record our understanding.
But can anyone use that understanding?
III.10. The canzone minus explicit Aufgesang
<canzone>
<stollen>
<l>unter den linden an der heide</l>
<l>da unser zweier bette was</l>
</stollen>
<stollen>
<l>da mugt ir vinden schone beide</l>
<l>gebrochen bluomen unde gras</l>
</stollen>
<abgesang>
<l>kuste er mich? wol tusentstunt</l>
<l>tandaradei</l>
<l>seht wie rot mir ist der munt</l>
</abgesang>
</canzone>
IV. XML Schema and DTD functionality
IV.1. Overview
- the idea of document grammars
- DTDs as document grammars (example)
- XML Schema: replicating DTDs
- XML Schema: types
- another example
- design issues and research questions
IV.2. XML Schema
- DTD++ (inheritance, real data types)
- DTD-- (no entities)
- instance syntax
- supporting programming-language and database-oriented types
- design problems
IV.3. The canzone schema v.1
In version 1 of this schema, we imitate the DTD slavishly.
At the outer level is a schema element:
<xsd:schema xmlns:xsd =
"http://www.w3.org/2001/XMLSchema"
>
<!--* element and type declarations
* go here ... *-->
</xsd:schema>
N.B. the schema does not identify
a document-root element / start symbol.
IV.4. Declaring elements
<xsd:element name="canzone">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="aufgesang"/>
<xsd:element ref="abgesang"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="aufgesang">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="stollen"/>
<xsd:element ref="stollen"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
IV.5. Declaring elements
- Note difference between element declaration (outer) and element reference (inner).
- Implicit occurrence information: min = max = 1.
IV.6. Repeated elements
<xsd:element name="abgesang">
<xsd:complexType>
<xsd:sequence minOccurs="1"
maxOccurs="unbounded">
<xsd:element ref="l"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="stollen">
<xsd:complexType>
<xsd:sequence minOccurs="1"
maxOccurs="unbounded">
<xsd:element ref="l"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
IV.7. Character data
<xsd:element name="l"> <xsd:complexType mixed="true"> <xsd:sequence> </xsd:sequence> </xsd:complexType> </xsd:element>or
<xsd:element name="l" type="xsd:string"/>
V. Supporting PL/DBMS type notions
V.1. Overview
- the idea of document grammars
- DTDs as document grammars (example)
- XML Schema: replicating DTDs
- XML Schema: types
- another example
- design issues and research questions
V.2. Supporting programming-language and dbms paradigms
- tag/type distinction
- named and anonymous datatypes
- simple datatypes
V.3. The tag/type distinction
In programming languages we write:
struct date {
int day;
int month;
int year;
char mon_name[4];
};
(Kernighan and Richie, The C Programming Language,
chapter 6, Structures.)
Distinguish the name used to access the field
from its type.
V.4. The tag/type distinction
Similarly, in conventional DTDs we write:
<!ELEMENT p - O (%paraContent;) > <!ELEMENT foreign - O (%paraContent;) > <!ELEMENT emph - O (%paraContent;) > <!ELEMENT hi - O (%paraContent;) > <!ELEMENT list - O (head, item*) > <!ELEMENT item - O (%paraSequence;) > <!ELEMENT note - O (%paraSequence;) >
Distinguish the element type name from
the name of the standard content-model.
V.5. The tag/type distinction
In XML Schema we sometimes write:
<xsd:element name="l" type="xsd:string"/>Can we do that for every element type?
N.B. four kinds of type
- element type (vs. element, element instance)
- data type
- simple type (lexical form has no markup)
- complex type (has element children)
V.6. Top-level named types
Named types can be used to capture commonalities:
<xsd:complexType name="lines">
<xsd:sequence minOccurs="1"
maxOccurs="unbounded">
<xsd:element ref="l"/>
</xsd:sequence>
</xsd:complexType>
<xsd:element name="abgesang" type="lines">
<xsd:element name="stollen" type="lines">
V.7. Top-level complex types
... or just to provide a name for a type:
<xsd:complexType name="canzoneform">
<xsd:sequence>
<xsd:element ref="aufgesang"/>
<xsd:element ref="abgesang"/>
</xsd:sequence></xsd:complexType>
<xsd:complexType name="aufgesang">
<xsd:sequence>
<xsd:element ref="stollen"/>
<xsd:element ref="stollen"/>
</xsd:sequence></xsd:complexType>
<xsd:element name="canzone"
type="canzoneform"/>
<xsd:element name="aufgesang"
type="aufgesang">
V.8. Anonymous types
We can hide things using
anonymous local types:
<xsd:element name="canzone">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="aufgesang">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="stollen" type="lines"/>
<xsd:element name="stollen" type="lines"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="abgesang" type="lines"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
Note nested declarations and definitions.V.9. Simple datatypes
- built-in
- primitive
- derived
- user-defined
V.10. Built-in primitive datatypes
- string
- boolean
- number, float, double
- duration, dateTime, time, date, gYearMonth, gYear, gMonthDay, gDay, gMonth
- hexBinary, base64Binary
- anyURI
- QName
- NOTATION
V.11. Built-in derived datatypes
- normalizedString, token, language
- IDREFS, ENTITIES, NMTOKEN, NMTOKENS, Name, NCName, ID, IDREF, ENTITY
- integer, nonPositiveInteger, negativeInteger, long, int, short, byte, nonNegativeInteger, unsignedLong, unsignedInt, unsignedShort, unsignedByte, positiveInteger
V.12. Hierarchy of simple types
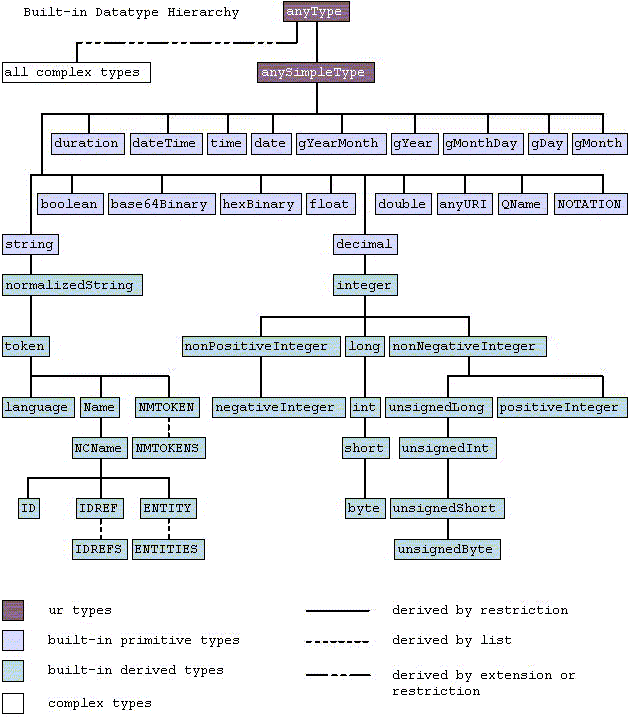
V.13. What is an atomic type?
Extensional:
- a set of values V
- a set of lexical forms L
- a mapping from L to V
V.14. What is an atomic type? (2)
Intensional:
- a base mapping L → V
- a set of fundamental facets:
- equality (identity)
- order (partial, total, none)
- boundedness
- cardinality
- numeric
V.15. What is an atomic type? (3)
Intension, cont'd
- a set of constraining facets:
- length, minLength, maxLength
- pattern (constrains lexical space)
- enumeration
- whiteSpace
- maxInclusive, maxExclusive, minInclusive, minExclusive
- totalDigits, fractionDigits
V.16. Non-atomic simple types
- list (white-space delimited)
- unions (ordered)
VI. Another example
VI.1. Overview
- the idea of document grammars
- DTDs as document grammars (example)
- XML Schema: replicating DTDs
- XML Schema: types
- another example
- design issues and research questions
VI.2. An example
Consider an annotation language for a system which
- tokenizes characters into words
- lemmatizes the words
- analyses the tokens syntactically
VI.3. Annotation language
The tagging might look like this:
<w><sf>Taggeren</sf>
<reading lemma="Taggere"
features="subst mask appell be
ent samset"/>
<reading lemma="Taggeren"
features="adj pos m/f ub
ent samset "/></w>
<w><sf>består</sf>
<reading lemma="bestå"
features="verb pres i2 tr5 tr12
tr21 tr22 "/></w>
<w><sf>av</sf>
<reading lemma="av"
features="prep "/></w>
<w><sf>en</sf>
<reading lemma="en"
features="adv"/>
<reading lemma="en"
features="pron pers ent hum"/>
<reading lemma="en"
features="det kvant mask ent"/>
<reading lemma="ene"
features="verb imp tr1 "/></w>
<w><sf>preprosessor</sf>
<reading lemma="preprosessor"
features="subst mask appell ub
ent samset "/></w>
<w><sf>,</sf>
<reading lemma="$,"
features="clb <komma>"/>
<reading lemma="$,"
features="<komma> "/></w>
...
<!--* Output from Oslo-Bergen tagger for Norwegian
* http://decentius.hit.uib.no:8005/cl/cgp/test.html
* XML markup added by hand for didactic purposes
* 2001-10-25 *-->
VI.4. A DTD
With an XML DTD, we can manage part of the job:
<!ELEMENT w (sf, reading+)>
<!ELEMENT sf (#PCDATA)>
<!ELEMENT reading EMPTY >
<!ATTLIST reading
lemma CDATA #REQUIRED
features CDATA #REQUIRED >
We cannot constrain features as we'd like.VI.5. A schema for annotation
<!DOCTYPE xsd:schema PUBLIC "-//W3C//DTD XMLSCHEMA 200105//EN"
"http://www.w3.org/2001/XMLSchema.dtd" [
<!ENTITY % schemaAttrs "
xmlns:this CDATA #IMPLIED
xmlns:xsd CDATA #IMPLIED"
>
<!ENTITY % p "xsd:">
<!ENTITY % s ":xsd">
]>
<xsd:schema
targetNamespace="http://decentius.hit.uib.no:8005/cl/cgp/test.html"
version="2001-10-25"
xmlns:this="http://decentius.hit.uib.no:8005/cl/cgp/test.html"
xmlns:w3c="http://www.w3.org/2001/XMLSchema/typelibrary"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
...
</xsd:schema>
VI.6. The type feature
<xsd:simpleType name="feature">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="<komma>"/>
<xsd:enumeration value="adj"/>
<xsd:enumeration value="adv"/>
<xsd:enumeration value="appell"/>
<xsd:enumeration value="be"/>
<xsd:enumeration value="clb"/>
<xsd:enumeration value="det"/>
<xsd:enumeration value="ent"/>
<xsd:enumeration value="hum"/>
<xsd:enumeration value="i2"/>
<xsd:enumeration value="imp"/>
<xsd:enumeration value="kvant"/>
<xsd:enumeration value="m/f"/>
<xsd:enumeration value="mask"/>
<xsd:enumeration value="pers"/>
<xsd:enumeration value="pos"/>
<xsd:enumeration value="prep"/>
<xsd:enumeration value="pres"/>
<xsd:enumeration value="pron"/>
<xsd:enumeration value="samset"/>
<xsd:enumeration value="subst"/>
<xsd:enumeration value="tr1"/>
<xsd:enumeration value="tr12"/>
<xsd:enumeration value="tr21"/>
<xsd:enumeration value="tr22"/>
<xsd:enumeration value="tr5"/>
<xsd:enumeration value="ub"/>
<xsd:enumeration value="verb"/>
</xsd:restriction>
</xsd:simpleType>
VI.7. The type featureSet
<xsd:simpleType name="featureSet">
<xsd:list itemType="this:feature">
<xsd:annotation>
<xsd:documentation xmlns="http://www.w3.org/1999/xhtml">
<p>A feature set is (for our purposes)
a list of features, separated by
white space. This schema type does
<em>not</em> forbid duplicate items,
though in practice they will not
arise because the tagger doesn't
produce them.</p>
</xsd:documentation>
</xsd:annotation>
</xsd:list>
</xsd:simpleType>
VI.8. The word element
<xsd:element name="word">
<xsd:complexType mixed="false">
<xsd:sequence>
<xsd:element name="sf" type="w3c:text"/>
<xsd:element name="reading"
minOccurs="1"
maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence/>
<!--* EMPTY element *-->
<xsd:attribute name="lemma"
type="xsd:string"/>
<xsd:attribute name="features"
type="this:featureSet"/>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
VII. Design problems and research questions
VII.1. Overview
- the idea of document grammars
- DTDs as document grammars (example)
- XML Schema: replicating DTDs
- XML Schema: types
- another example
- design issues and research questions
VII.2. Some design problems
- Inheritance / type derivation
- Layering
- Schemas and namespaces
- Modularization
- Finding the schemas
- Information for downstream apps
VII.3. Inheritance
Document systems turn out to have a very clear model
of class systems and inheritance.
- inheritance of attributes
- inheritance of locations
- not inheritance of content models
VII.4. Inheritance in TEI
In the TEI, for example, elements can inherit attributes:
<!ATTLIST name %a.global;
%a.names;
type CDATA #IMPLIED
TEIform CDATA 'name' >
Or location in content models:
<!ENTITY % m.phrase '%x.phrase %m.data; | %m.edit; |
%m.formPointers; | %m.hqphrase; | %m.loc; |
%m.phrase.verse; | %m.seg; | %m.sgmlKeywords; |
%n.formula; | %n.fw; | %n.handShift;' >
VII.5. Inheritance Type derivation
By contrast, it turns out to be hard to model stepwise refinement
of programming-language types:
- restriction (preserves subset semantics)
- extension (preserves prefix semantics)
Depends on point of view:
- content model as list of fields with accessors, defining a record type
- content model as right-hand side of a grammar rule, defining a language
VII.6. Schema layers
We distinguish:
- schema documents (with single target namespace)
- schemas (sets of abstract components)
Schema composition operations:
- import
- include
- include with override / redefine
VII.7. Schemas and namespaces
Some (unpleasant) facts of life:
- Namespaces allow us to distinguish mine from not-mine.
- Namespaces do not provide universal names.
- The namespace : language relation is 1:n.
- The language : grammar relation is 1:n.
- Therefore, the namespace : schema relation is 1:n.
VII.8. Modularization
XML Schema makes it possible to write modular document
type definitions:
- late collection of schema components
- namespace-aware name matching, validation
- white-box wildcards (lax / opportunistic)
- black-box wildcards (skip)
VII.9. Linking document and schema
- namespace name
- schemaLocation hint
VII.10. Post-schema-validation infoset (PSVI)
XML-Schema validation: infoset → infoset.
- additions, no changes
- type assignment information
- validation-attempted information (strict, lax, skip)
- validation-outcome information