Semantic interpretation of XML documents
Modelling linguistic information resources
Modellierung sprachlicher Informationsressourcen
12 Jan. 2004
C. M. Sperberg-McQueen
World Wide Web Consortium
MIT Computer Science and Artificial Intelligence Laboratory (CSAIL)
- 1. Overview
- 2. Acknowledgements / Responsibilities
- 3. Goal of our work
- 4. Does markup have meaning?
- 5. What kind of meaning?
- 6. Practical implications
- 7. Working notion of meaning
- 8. Specifying the meaning of markup
- 9. System overview
- 10. Concrete system overview
- 11. A possible goal
- 12. Rejection
- 13. Some premises
- 14. DTD-specific interpretation
- 15. Another approach
- 16. System overview
- 17. Two simple examples
- 18. The markup
- 19. Markup-related inferences
- 20. How does markup mean?
- 21. System overview
- 22. Image sentences
- 23. Application sentences
- 24. Metadata example
- 25. Some inferences
- 26. Formal inferences
- 27. Dates
- 28. Markup about markup
- 29. Inference rules
- 30. Formalized tag set description
- 31. An alternative system design
- 32. Challenges
- 33. Distributed properties
- 34. A synonymous example:
- 35. Inheritance
- 36. Non-distributed properties
- 37. Overrides and incompatibilities
- 38. Overrides
- 39. Overrides
- 40. Milestones
- 41. References to the same individual
- 42. Completeness
- 43. Ontology and reference
- 44. Ontology examples
- 45. Desert landscape
- 46. A ‘desert landscape’ view
- 47. A ‘fertile valley’ view
- 48. Thank you
Overview | 1 of 48 |
- introduction
- system overview
- image sentences
- application sentences
- inference rules / axioms
- an alternative design
- challenges
Acknowledgements / Responsibilities | 2 of 48 |
Virtues
- Claus Huitfeldt (Universitetet i Bergen)
- Allen Renear (University of Illinois at Urbana/Champaign)
- David Dubin (University of Illinois at Urbana/Champaign)
- Kjersti Berg (Universitetet i Bergen)
- Paul Meurer (Universitetet i Bergen)
- Sindre Sørensen (Universitetet i Bergen)
Vices
- C. M. Sperberg-McQueen
Goal of our work | 3 of 48 |
to give an intellectually satisfying (and potentially useful)
account of the meaning of markup.
Does markup have meaning? | 4 of 48 |
It would seem so.
- What else can tags like chapter, name, person, abbr mean?
- Why else do we guide our processing by the markup?
- How else can we argue over whether a given tagging is correct or incorrect?
What kind of meaning? | 5 of 48 |
Some salient characteristics:
- not* the same as natural-language meaning: cf.
"John" is a personal name
John loves Mary
- vocabulary-specific
- possible synonymy: cf.
<sic corr="receive">recieve</sic>
<corr sic="recieve">receive</corr>
- ambiguity* rather rare*
- predicate calculus truth-functional; markup can be performative or prescriptive
- markup sometimes self-referential
Practical implications | 6 of 48 |
A better grip on semantics ought to help with
- inter-translation among vocabularies
- retrieval across (or within) vocabularies
- comparison of content
- authenticity checking
- finding relevant vocabularies
- complexity measurement / design
Working notion of meaning | 7 of 48 |
... we shall accept that the meaning of A is the set of sentences S true because of A. The set S may also be called the set of consequences of A. Calling sentences of S consequences of A underscores the fact that there is an underlying logic which allows one to deduce that a sentence is a consequence of A.
Wladyslaw M. Turski and Thomas S. E. Maibaum,
The specification of computer programs
(Wokingham: Addison-Wesley,
1987), p. 4.
Specifying the meaning of markup | 8 of 48 |
So ...
- what inferences are licensed by each element type?
- by each attribute?
- for each location? (i.e. how do you associate the meaning with a particular instance?)
System overview | 9 of 48 |
In the abstract, ...

Concrete system overview | 10 of 48 |
In practice:

A possible goal | 11 of 48 |
Is this the goal?

Rejection | 12 of 48 |
It better not be.

Some premises | 13 of 48 |
- Rules are vocabulary-specific.
- The coding <F>a</F> is both visually and semantically parallel to Fa
- Definition of F to be provided ...
- In many cases, the relevant property has arity > 1: F(a,b), F(a,b,c), ...
- As a consequence, we need deixis.
DTD-specific interpretation | 14 of 48 |
<title level="j">CHum</title>

"node X is a title, with 'level' = 'j'"
"there exists a journal called CHum"
Another approach | 15 of 48 |

<title level="j">CHum</title>
"node X is a title, with 'level' = 'j'"
"if there exists an element of type 'title' with 'level' = 'j',
then there exists a journal whose name is spelled by the contents
of the element"
System overview | 16 of 48 |
Two simple examples | 17 of 48 |
Wittgenstein VW 103: 18r
Kann man aber wirklich so leben
daß das Leben aufhört
problematisch zu sein?
Wittgenstein, VW 108: 37
100 /
Ich beschreibe eine↑n↓ Tatsache
↑Sachverhalt↓ doch nicht ↑dadurch↓
daß ich das erwähne was mit
ihr↑m↓ nichts zu tun hat &
constatiere
daß ...
The markup | 18 of 48 |
<R>96</R><sec> <s>Kann man aber <d>wirklich</d> so leben daß das Leben auf­hört problematisch zu sein?</s> ... </sec>
<s>Ich beschreibe <p.em><p.em.el><uw1>eine<el>n</el> <d>Tatsache</d></uw1> <i>Sachverhalt</i> doch nicht <imw>dadurch</imw> daß ich das erwähne was mit ih<p.o><p.o.el>r</p.o.el><p.o.el>m</p.o.el></p.o> nichts zu tun hat & <p.trsn><p.trsn.el>c</p.trsn.el><p.trsn.el>k</p.trsn.el ></p.trsn>onstatiere daß ...</s>
Markup-related inferences | 19 of 48 |
- The manuscript contains some particular words (strings of characters).
- Some words (characters) are deleted in the MS.
- Some words (characters) are added above the line in the MS.
- This particular subsequence of words (characters) forms a sentence.
How does markup mean? | 20 of 48 |
Because markup means something, ...
we know certain things.
I.e. because we see certain markup,
we are allowed (licensed) to make certain inferences.
I.e. markup licenses inferences.
The meaning of markup is the set of inferences it licenses.
System overview | 21 of 48 |
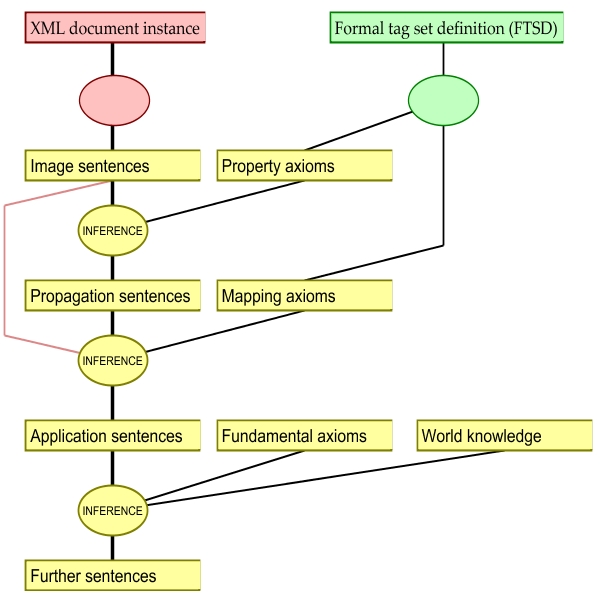
Image sentences | 22 of 48 |
Image sentences are about information items in the
XML information set:
node(n8365). node(n8366). ... gi(n8365,s). gi(n8374,d). gi(n8375,'#pcdata'). gi(n8377,i). gi(n8378,'#pcdata'). ... content(n8366,"Ich beschreibe "). content(n8375,"Tatsache"). content(n8378,"Sachverhalt"). ... first_child(n8365,n8365). first_child(n8367,n8368). ... nsib(n8357,n8365). nsib(n8365,n8367). ... parent(n8365,n8357). ...
Application sentences | 23 of 48 |
Application sentences are about objects in the
application domain. For the Wittgenstein project, for example:
char(c174832, 'T', 174832). char(c174833, 'a', 174833). char(c174834, 't', 174834). char(c174835, 's', 174835). char(c174836, 'a', 174836). char(c174837, 'c', 174837). char(c174838, 'h', 174838). char(c174839, 'e', 174839). deleted(c174832). deleted(c174833). deleted(c174834). ...For a purchase order application:
purchase_order(p123). po_shippingaddress(p123,a45). po_billingaddress(p123,a46). relation_applies(shipto,[p123,a45]). relation_applies(billto,[p123,a46]).
Metadata example | 24 of 48 |
<doc> <code-version>mecs102</code-version> <group>Manuscripts</group> <group>BΣnde</group> <catno>108</catno> <ti>Band IV Philosophische Bemerkungen</ti> <crncopy>10</crncopy> <datfrom>19291213</datfrom> <datto>19300809</datto> <transcribers>Claus Huitfeldt 1984, Alois Pichler 1991</transcribers> <proofreaders>Ole Letnes 1992</proofreaders> <revisionhistory>Transcribed by Claus Huitfeldt July 1984 ‐ February 1985. Recoded from CT I to CT IIb by Claus Huitfeldt 881002. Recoded from NWP to WAB registration standard 911031; recoded from mecs101 to mecs102 920212. Retranscribed by Alois Pichler 1991. Special notations, Protocols und Typography März 1992. Erste Korrektur Ole Letnes April bis Juni 1992. Vergleich mit dem Original Herbst 1992; korrigiert nach diesem Vergleich September 1995. Spellcheck by Maria Sollohub and Alois Pichler, September 1995.</revisionhistory> <hands>H1, H2</hands> ... </doc>
Some inferences | 25 of 48 |
- The file vw108 is a transcription of von Wright item 108.
- The file vw108 conforms to MECS-WIT version 1.02.
- The title of the item transcribed in file vw108 is Band IV Philosophische Bemerkungen.
- The item transcribed in file vw108 is estimated to have been written on or after 13 December 1929.
- The item transcribed in file vw108 is estimated to have been written on or before 9 August 1930.
- The transcription in vw108 was made by “Claus Huitfeldt 1984, Alois Pichler 1991”.
- The transcription in vw108 was proofread by “Ole Letnes 1992”.
- ...
Formal inferences | 26 of 48 |
- Node n.vw108.0001 is a transcription of
the item with number 108 in von Wright's catalog of 1984.
(∃ i : item) (item_vwnumber(i, 108) & transcribes(n.vw108.0001,i) & (∀ j)(item_vwnumber(j,108) ⇒ i = j) & (∀ k)(transcribes(n.vw108.0001,k) ⇒ i = k))
- The file vw108 conforms to MECS-WIT
version 1.02.
conforms(n.vw108.0001,'1.02')
- The title of the item transcribed in file vw108
is Band IV Philosophische Bemerkungen.
... item_title(i,'Band IV Philosophische Bemerkungen')
Dates | 27 of 48 |
The item transcribed in file vw108
is estimated to have been written on or after 13 December 1929.
... item_a_quo(i,'1929-12-13')
The item transcribed in file vw108
is estimated to have been written on or before 9 August 1930.
... item_ad_quem(i,'1930-08-09')
Markup about markup | 28 of 48 |
The transcription in vw108 was made by
“Claus Huitfeldt 1984, Alois Pichler 1991”.
... (∃ p : persons)
(transcribes_as(p, i, m)
& nl_describes(
"Claus Huitfeldt 1984, Alois Pichler 1991",
p)))
The transcription in vw108 was proofread by
“Ole Letnes 1992”.
... (∃ p : persons)
(proofreads_against(p, m, i)
& nl_describes("Ole Letnes 1992", p)))
Inference rules | 29 of 48 |
To make inference rules, we
- replace names with variables
- describe the conditions under which the conclusion is valid
- wrap the conditional in variable bindings
The contents of a transcription
element e provide a natural-language description of
the person(s) who transcribed the document containing e.
(∀ n : node) (∀ m : node)
(∀ i : item) (∀ s : string)
(gi(n,'transcribers') & contents(n,s)
& root(n,m) & transcribes(m,i)
⇒ (∃ p : persons)
(transcribes_as(p, i, m)
& nl_describes(s, p)))
Formalized tag set description | 30 of 48 |
The formalized tag-set documentation for TEI (in part):
<attribute match="@lang"> <doc> <p>If an element has a <ident>lang</ident> attribute, the attribute value names the language of the element's content (unless overridden).</p> </doc> <rule distributed="true" lang="Prolog"> lang(<de xv="../@id"/>,.) :- !. </rule> <doc> <p>Otherwise, the language is the same as that of the parent element.</p> </doc> <rule distributed="false" lang="Prolog"> lang(E,L) :- parent(P,E), lang(P,L). </rule> </attribute>
An alternative system design | 31 of 48 |

Challenges | 32 of 48 |
- technical / plumbing
- distributed / non-distributed properties
- overriding inheritance
- milestone elements
- unique identity of individuals
- design / philosophical
- completeness
- fertile valley vs. desert landscape
- meta-markup
Distributed properties | 33 of 48 |
If the word Tatsache is deleted,
then the letter T is deleted.
If the word Indenture is rendered in black-letter,
then its initial letter I is rendered in black-letter.
Consider this (from
Tristram Shandy):
<hi rend="gothic">And this Indenture further witnesseth</hi> that the said <hi rend="italic">Walter Shandy</hi>, merchant, in consideration of the said intended marriage ...
A synonymous example: | 34 of 48 |
Or equivalently*:
<P><HI REND="gothic">And</HI> <HI REND="gothic">this</HI> <HI REND="gothic">Indenture</HI> <HI REND="gothic">further</HI> <HI REND="gothic">witnesseth</HI> that the said <HI REND="italic">Walter Shandy</HI>, merchant, in consideration of the said intended marriage ... </P>
These examples license the same inferences.
Inheritance | 35 of 48 |
Distributed properties: commonly inherited.
If an ancestor is in English (has lang="en"),
then this element also is in English.
Non-distributed properties | 36 of 48 |
Non-distributed properties are true of the element as a
whole, but not true of all of the individual words or characters
of the content. From the markup
<P>Reader, I married him.</P>we can infer the existence of one paragraph, but we cannot infer that the word Reader is itself a paragraph. We can, however, infer that it has the property of being within a paragraph.
Overrides and incompatibilities | 37 of 48 |
Consider:
<doc lang="en"> <p>Wittgenstein wrote: <q lang="de"><ital>Die Welt ist alles, was der Fall ist.</ital></q> It is hard to escape, at first reading, the suspicion that Wittgenstein is guilty here of a gross platitude; it is only after reading the rest of the <title lang="la">Tractatus</title> that on returning to its famous first sentence one appreciates the depths of its intension.</p> </doc>
Overrides | 38 of 48 |
If an ancestor is in English (has lang="en"),
then this element also is in English.
Overrides | 39 of 48 |
If an ancestor is in English (has lang="en"),
then this element also is in English, unless
this element or an ancestor has a different
value for lang.
Milestones | 40 of 48 |
Generally, inferences about an element (or about what it
represents) rely on the generic identifier and
attributes of
- the element
- its ancestors
But how do we know what page a word is on?
Typically, the page is not an ancestor of the paragraph.
References to the same individual | 41 of 48 |
When we speak of “the item transcribed by
this MECS-WIT document”, or
“the bibliographic item described by
the enclosing bibl element”,
how do we translate the
the?
Existential assertion:
(there exists x) (bib_item(x) & bibl_item_desc(x,[[.]]) & (∀ y)(bibl_item_desc(y,[[.]]) ↔ x = y))and reference:
title(.)
& (∀ x)
(bibl_item_desc(x, [[ancestor::bibl]])
→ bib_item_title(x,[[.]])]
Completeness | 42 of 48 |
Can we really expect to list "all and only the inferences
licensed by the markup"?
No: we cannot list them all (infinite set).
We may be able to identify a basis (a finite set of
sentences from which the members of the infinite set follow).
Or maybe not?
Ontology and reference | 43 of 48 |
What do the deictic expressions actually denote?
- the element (in this encoding)
- the text (= this rule asserts that in the text there is some (component?) part which is represented by this XML element in this encoding, and that that component has some property.
- some referent of the text
- some other encoding or representation of the text
- the words or characters contained* (except for notes, etc.) within this element (but N.B. deletions, insertions)
Ontology examples | 44 of 48 |
- the element (This TEI header was last updated 2001-06-15.)
- the text (This work [i.e. Peer Gynt] was created in 1874)
- some referent of the text (Henrik Ibsen was born in ...)
- the words or characters contained in this element (The string "Ibsen" is a proper noun here — not the name element)
- some other encoding or representation of the text (A page-break occurs at this point in the edition of 1874)
Desert landscape | 45 of 48 |
char(c174832, 'T', 174832). char(c174833, 'a', 174833). char(c174834, 't', 174834). ... deleted(c174832). deleted(c174833). deleted(c174834). ... deletion(d342, c174832, c174839).
Do deletions exist?
A ‘desert landscape’ view | 46 of 48 |
The Wittgenstein transcripts postulate
- the manuscript
- the transcription
- pages
- text blocks (main block, left margin, ...)
- characters
- the von Wright catalog and its entries
- words and sentences as described by Duden
- people
- dates
- MECS-WIT version numbers
A ‘fertile valley’ view | 47 of 48 |
We may also postulate
- sections
- revisions
- acts of deletion
- insertions
- formulae
- quotations
- names, dates, things, ...
Thank you | 48 of 48 |