Sevastopol
An XSD schema represented as a definite-clause translation grammar
A working paper prepared for the W3C XML Schema Working Group
C. M. Sperberg-McQueen
21 October 2005
$Id: podctg.html,v 1.7 2005/10/22 02:42:57 cmsmcq Exp $
- 1. Introduction
- 1.1. Context
- 1.2. How to read this paper
- 1.3. Layering
- 1.4. Naming conventions and terminology
- 1.4.1. Name mangling rules
- 1.4.2. Element types in the purchase-order schema
- 1.4.3. Complex types
- 1.4.4. Simple types
- 1.4.5. Terminology and variable names
- 2. The core: Providing PSVI properties
- 2.1. Top-level rules for element types
- 2.1.1. Basic pattern
- 2.1.2. Elements with complex types
- 2.1.3. Elements with simple types
- 2.2. Rules for attributes
- 2.2.1. Basic pattern
- 2.2.2. Namespace attributes and XSI attributes
- 2.2.3. Occurrence checking
- 2.2.4. Rules for the Purchase-order type
- 2.2.5. White-space normalization of simple types
- 2.2.6. Attributes for PurchaseOrderType, continued
- 2.2.7. Rules for attributes of other complex types
- 2.2.8. Simple types (namespace and XSI attributes)
- 2.2.9. Partitioning the list of attributes
- 2.3. Rules for content of complex types
- 2.4. Rules for checking values of simple types
- 2.4.1. Rules called from top-level element predicates
- 2.4.2. Checking strings
- 2.4.3. Checking decimals
- 2.4.4. Checking dates
- 2.4.5. Checking leap years
- 2.4.6. Checking SKUs
- 2.4.7. Checking quantities
- 2.5. Exposing the PSVI
- 2.5.1. Top-level call
- 2.5.2. Generating current set of namespace bindings
- 2.5.3. Generating QName given namespace bindings
- 2.5.4. Writing out attributes
- 2.5.5. Writing out element properties
- 2.5.6. Writing out attribute properties
- 2.5.7. Writing out children
- 2.6. Overview and Summary
- 2.6.1. Top level of program po_core.pl
- 2.6.2. Basic patterns
- 2.6.3. Naming conventions
- 2.6.4. Generic tools
- 2.6.5. Convenience files for the core grammar
- 2.7. Evaluation
- 2.1. Top-level rules for element types
- 3. Handling mixed content and substitution groups
- 3.1. Mixed content
- 3.2. Substitution groups
- 4. The PV grammar: Validity, validation-attempted, and error handling
- 4.1. Goals and overview
- 4.1.1. Additional PSVI properties
- 4.1.2. Handling invalid and partially valid input
- 4.1.3. Validation against element declaration
- 4.1.4. Summary of goals
- 4.1.5. Overview of PV grammar
- 4.2. Validation of simple types
- 4.2.1. Conventions for validating elements and lexical forms
- 4.2.2. Error codes for simple types
- 4.2.3. Validating xsd:string
- 4.2.4. Validating xsd:decimal
- 4.2.5. White space normalization in the PV grammar
- 4.2.6. Validating xsd:date
- 4.2.7. Validating po:quantity
- 4.2.8. Validating po:SKU
- 4.2.9. Validating QNames
- 4.2.10. Validating xsd:NMTOKEN
- 4.2.11. Validating list of anyURI
- 4.2.12. Validating xsd:boolean
- 4.2.13. Content rules for simple types
- 4.2.14. Summary of simple-type validation rules
- 4.2.15. Tests for validation of simple types
- 4.3. Validation of elements
- 4.3.1. Basic pattern for element rules
- 4.3.2. Elements with complex types
- 4.3.3. Elements with simple types
- 4.3.4. Maintaining the list of inscope namespaces
- 4.3.5. Checking elements against their element declarations
- 4.3.6. Adding properties to the PSVI
- 4.3.7. Calculating the validity and validation attempted properties
- 4.4. Validation of attributes
- 4.5. Validation of complex content
- 4.5.1. Content-model rules
- 4.5.2. Succeeding on invalid content
- 4.5.3. Simple fallback processing
- 4.6. Miscellaneous
- 4.7. Evaluation
- 4.7.1. Problems, enhancements, correctness
- 4.7.2. Timings
- 4.1. Goals and overview
- 5. Reification of schema components and the second-level interpreter
- 5.1. Overview
- 5.1.1. Structure
- 5.1.2. Naming and argument conventions
- 5.2. Reification of major component types
- 5.3. Starting schema-validity assessment
- 5.3.1. Shell script sevastopol
- 5.3.2. Top-level Prolog predicates
- 5.4. Validating individual elements
- 5.5. Validating content and pre-lexical forms against simple types
- 5.5.1. Validation
- 5.5.2. Recasting the lexical-form rules
- 5.6. Validating content against complex types
- 5.7. Validating attributes
- 5.7.1. Generic rules for attribute-validation
- 5.7.2. Type-specific definitions of attributes
- 5.7.3. Validation
- 5.8. Miscellaneous
- 5.9. Evaluation
- 5.1. Overview
- 6. Notes on other features of XML Schema
- 6.1. Handling xsi:type
- 6.2. Fallback to lax processing
- 6.3. Supporting wildcards with skip and lax processing
- 6.4. Supporting xsi:nil
- 6.5. Numeric exponents in content models
- 6.6. Mixed content
- 6.6.1. Filtering the children
- 6.6.2. Using second-level parsers
- 6.7. Other features
- 7. Conformance claim
- 8. Further work
- A. Works cited and further reading
- A.1. Works cited
- A.2. Further reading
- B. The test cases
- C. Regression testing
- D. SWI Prolog handling of characters
- E. Error codes for elements and attributes
- E.1. Schema-validity assessment
- E.2. Elements: local validity
- E.3. Validity with respect to a complex type
- E.4. Attributes
- E.5. Simple types
- E.5.1. Lexical forms
- E.5.2. Values
- E.6. Miscellaneous, common constructs
- F. List of possible improvements
- G. Indices to source code
1. Introduction
1.1. Context
1.2. How to read this paper
1.3. Layering
- No types have mixed content.
- No elements are in any substitution groups.
- The type hierarchy is very shallow, and there is little scope for non-vacuous use of xsi:type in the document instance.
- No types are nillable, so there is little use for the xsi:nil attribute in document instances.
- There are no wildcards.
- All content-model particles have minimum and maximum occurrence indicators of zero, one, or unbounded; there are no arbitrary numeric exponents.
- The schema is designed for single-namespace documents and no schema composition operations (import, include, redefine) are needed.
- The schema document has no undischarged references to types or elements, so it provides no examples of missing components.
- The schema imposes no identity constraints and uses no IDs or IDREFs.
- The schema document provides no annotations.
- The core of the grammar will provide some, but not all, of the infoset properties defined for the PSVI and the input infoset; it will provide a PSVI only for valid input documents; it will fail on invalid input. The first layer illustrates the representation of content models and attribute declarations in DCTG form.The purchase-order schema does not contain any mixed-content types or substitution groups, but after building the first layer it will be reasonably clear how to support those.
- The partial-validity layer (PV) returns a PSVI for all documents, not just schema-valid ones.
- The reification or second-level(2L) layer represents content models not as Prolog rules, but as Prolog data structures; this makes possible a more concise representation of the schema components, at the cost of having a more abstract validation process. At this point, it becomes possible to offer the user control over the starting point of schema-validity assessment: it need not start at the root of the document, and it need not begin in lax validation mode.
- When the document is invalid, the schema processor may (or should) exit with an error code. This restriction is lifted in the partial-validation layer.
- Schema-validity assessment always begins at the root element, with a known element declaration. Consequently, there is no need to provide the validation root property in the PSVI. This restriction is lifted in the reification layer (at least in the sense that the validation root property is provided, and that it would in principle be possible to start somewhere other than the root — no use is actually made of that possibility).
- The schema we are working with obeys the constraints on schemas; no checking of these constraints is necessary. Since the purchase-order schema does in fact obey all applicable constraints, this is perhaps more of an observation than an assumption. But in extending the patterns of DCTG construction shown here to other cases, it will be necessary to enforce the constraints on schema components and on XML representation of schemas.
- The schema we are working with has no missing components, again an observation more than an assumption.
- The xsi:type and xsi:nil attributes are not used in the document instance (or are used only vacuously).
- When an element is invalid, the schema processor should skip its children and move on: there is no fallback processing.
1.4. Naming conventions and terminology
- element rules match a single element in the input document and check it against a given declaration
- attribute-list rules check the attributes on an element against the relevant type declaration
- content-model rules check sequences of child elements against the content model of a given complex type
- simple-type checking rules check a character sequence in the input infoset against the definition of a given simple type
- type-sva rules check sets of attributes and sequences of child nodes against the definition of a given type; these serve as wrappers for the attribute-list, content-model, and simple-type checking rules
- ELEMID: element rules show up as grammar rules with names of the form ELEMID (e.g. e_purchaseOrder); a semantic action calls attribute-list and content rules to validate the element
- sva_atts_TYPEID: attribute-list rules, with names of the form sva_atts_ + TYPEID, check the attributes of an element against a type
- attocc_TYPEID: subsidiary rules named attocc_ + TYPEID check attribute occurrences for a given type
- ras_TYPEID and lras_TYPEID: grammar rules for attribute specifications of a given type, in single and list form
- sva_content_TYPEID: content-model rules carry names of the form sva_content_ + TYPEID and check the content of an element against the type of the element, whether simple or complex; these predicates are wrappers around lower-level predicates
- content_TYPEID: for complex types, this is the content model itself, in a grammar rule
- sva_plf_TYPEID: sva_plf_ + TYPEID rules check pre-lexical forms against simple types
- lexform_TYPEID: a grammar rule for checking the lexical representation of a simple type value; there are various auxiliaries which vary in the different levels of the grammar
 Figure 1: Abstract call graph for the core layer
Figure 1: Abstract call graph for the core layer
- The top-level routines load_go_file and load_file (at the top) call an ELEMID rule (specifically e_purchaseOrder).
- The oval labeled ELEMID represents the element rules.
- The type-sva rules sva_content_TYPEID and sva_atts_TYPEID check sets of attributes and sequences of child nodes against the definition of a given type; they call the attribute rules and content-model rules to do the core work.
- The attribute rules (at the right) include the grammar rules lras_TYPEID and ras_TYPEID, which define the attributes legal for the type.
- The content-model rules have names of the form content_TYPEID; they typically contain references to element rules (hence the cycle).
- The simple-type checking rules (sva_plf_TYPEID) check a character sequence against a given simple type; they are called both by individual attribute rules and by sva_content_TYPEID.
1.4.1. Name mangling rules
- e_ + name: top-level elements
- t_ + name: top-level types
- a_ + name: top-level attributes
- e_ + name + _ + TYPEID: elements local to a complex type (the TYPEID is the type identifier for the enclosing type)
- t_ + ELEMID: types local to an element; ELEMID is the element identifier for the enclosing element
- a_ + name + _ + TYPEID: attributes local to a complex type; the TYPEID is the type identifier for the enclosing type
1.4.2. Element types in the purchase-order schema
- e_purchaseOrder = /element(purchaseOrder)
- e_comment = /element(comment)
- e_shipTo_t_PurchaseOrderType = /complexType(po:PurchaseOrderType) /sequence() /element(shipTo)
- e_billTo_t_PurchaseOrderType = /complexType(po:PurchaseOrderType) /sequence() /element(billTo)
- e_items_t_PurchaseOrderType = /complexType(po:PurchaseOrderType) /sequence() /element(items)
- e_name_t_USAddress = /complexType(po:USAddress) /sequence() /element(name)
- e_street_t_USAddress = /complexType(po:USAddress) /sequence() /element(street)
- e_city_t_USAddress = /complexType(po:USAddress) /sequence() /element(city)
- e_state_t_USAddress = /complexType(po:USAddress) /sequence() /element(state)
- e_zip_t_USAddress = /complexType(po:USAddress) /sequence() /element(zip)
- e_item_t_Items = /complexType(po:Items) /sequence() /element(item)
- e_productName_t_e_item_t_Items = /complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(productName)
- e_quantity_t_e_item_t_Items = /complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(quantity)
- e_USPrice_t_e_item_t_Items = /complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(USPrice)
- e_shipDate_t_e_item_t_Items = /complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(shipDate)
1.4.3. Complex types
- t_PurchaseOrderType = /complexType(po:PurchaseOrderType)
- t_USAddress = /complexType(po:USAddress)
- t_Items = /complexType(po:Items)
- t_e_item_t_Items = /complexType(po:Items)/sequence()/element(item)/complexType()
1.4.4. Simple types
- t_e_quantity_t_e_item_t_Items = /complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(quantity) /simpleType()
- t_SKU = /simpleType(SKU)
- t_xsd_string = xsd:string
- t_xsd_integer = xsd:integer
- t_xsd_decimal = xsd:decimal
- t_xsd_date = xsd:date
1.4.5. Terminology and variable names
- Anjewierden/Wielemaker form: the Prolog representation of XML used by the XML parser in SWI Prolog, originally designed by Anjo Anjewierden and documented by Jan Wielemaker in [Wielemaker 2001]
- ATTID (in pseudo-code): a meta-syntactic variable indicating a place where, in actual code, an attribute identifier will occur
- AWF: Anjewierden/Wielemaker form, a representation of XML in Prolog datastructures
- attribute specification: the name-value pair given in an XML document (or information set) to specify the value for the attribute of that name; may be referred to as raw to distinguish it from a parsed attribute node; in variable names, often as or ras; a variable bound to a set or list of attribute specifications is often named Las or Lras
- DCTG properties: grammatical attributes provided by a DCTG
- grammatical attributes: the named values associated with nodes in the parse tree of a DCTG; in attribute grammars, these are normally referred to as attributes; the terms grammatical attributes and DCTG properties or just properties are sometimes used here to avoid confusion with XML attributes
- ELEMID (in pseudo-code): a meta-syntactic variable indicating a place where, in actual code, an element identifier will occur
- Las (in variable names): a list of attribute specifications
- Lf or LF (in predicate or variable names): lexical form
- Lpa (in variable names): a list of parsed attribute nodes (with DCTG properties)
- Lpe (in variable names): a list of parsed element nodes
- Lpna (in variable names): a list of parsed namespace-attribute nodes (with DCTG properties)
- Lras (in variable names): a list of raw attribute specifications
- Plf or PLF (in predicate or variable names): pre-lexical form
- PN (in predicate or variable names): parsed node with DCTG properties (as returned by grammar predicates)
- pre-lexical form: the sequence of characters presented in the input information set as an attribute value or the content of an simply-typed element; the application of the whitespace processing rules associated with a given simple type will transform the pre-lexical form into a lexical form which may or may not be legal for that type
- property: a grammatical attribute, a DCTG property
- raw: not yet provided with DCTG properties
- simply typed (of elements): being declared as having a simple (rather than a complex) type
- sva (in predicate names): schema-validity assessment
- TYPEID (in pseudo-code): a meta-syntactic variable indicating a place where, in actual code, a type identifier will occur (may occasionally appear as TID)
- XML attributes: the named values associated with elements in an XML document; the qualification XML is used to avoid confusion with grammatical attributes
2. The core: Providing PSVI properties
- for Attribute Information Items:
- [local name]
- [namespace name]
- [normalized value]
- for Element Information Items:
- [local name]
- [namespace name]
- [children]
- [attributes]
- [in-scope namespaces] or [namespace attributes]
- for Namespace Information Items:
- [prefix]
- [namespace name]
- type definition name, namespace, anonymous, and type
- schema specified (schema or infoset)
- validation attempted (always full)
- validity (always valid, because when the document is not valid, we fail)
- info_item: on elements and attributes, specifies what kind of information item it is (i.e. element or attribute)
2.1. Top-level rules for element types
2.1.1. Basic pattern
ELEMID ::= [element(N:GI,Lras,Lre)],
{
sva_atts_TYPEID(Lras,Lpa,Lpna),
sva_content_TYPEID(Lre,Lpe)
}
<:> info_item(element)
&& attributes(Lpa)
&& namespace_attributes(Lpna)
&& children(Lpe)
&& local_name(GI)
&& namespace_name(N)
&& type_definition_anonymous(Boolean)
&& type_definition_namespace(URI)
&& type_definition_name(NCName)
&& type_definition_type(complex)
&& validation_attempted(full)
&& validity(valid)
.
Later, we will add further grammatical attributes, and
use values other than full and valid
for invalid elements.2.1.2. Elements with complex types
/* e_purchaseOrder: grammatical rule for purchaseOrder element.
e_purchaseOrder(ParsedNode,L1,L2): holds if the difference
between L1 and L2 (difference lists) is a purchase order
element in SWI Prolog notation.
And so on for the other element types.
*/
e_purchaseOrder ::= [
element('http://www.example.com/PO1':purchaseOrder,
Lras,Lre)],
{
sva_atts_t_PurchaseOrderType(Lras,Lpa,Lpna),
sva_content_t_PurchaseOrderType(Lre,Lpe)
}
<:> local_name(purchaseOrder)
&& namespace_name('http://www.example.com/PO1')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('PurchaseOrderType')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace 2}
.
e_shipTo_t_PurchaseOrderType ::= [element(shipTo,Lras,Lre)],
{
sva_atts_t_USAddress(Lras,Lpa,Lpna),
sva_content_t_USAddress(Lre,Lpe)
}
<:> local_name(shipTo)
&& namespace_name('')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('USAddress')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace 2}
.
e_billTo_t_PurchaseOrderType ::= [element(billTo,Lras,Lre)],
{
sva_atts_t_USAddress(Lras,Lpa,Lpna),
sva_content_t_USAddress(Lre,Lpe)
}
<:> local_name(billTo)
&& namespace_name('')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('USAddress')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace 2}
.
e_items_t_PurchaseOrderType ::= [element(items,Lras,Lre)],
{
sva_atts_t_Items(Lras,Lpa,Lpna),
sva_content_t_Items(Lre,Lpe)
}
<:> local_name(items)
&& namespace_name('')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('Items')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace 2}
.
e_item_t_Items ::= [element(item,Lras,Lre)],
{
sva_atts_t_e_item_t_Items(Lras,Lpa,Lpna),
sva_content_t_e_item_t_Items(Lre,Lpe)
}
<:> local_name(item)
&& namespace_name('')
&& type_definition_anonymous('true')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('t_e_item_t_Items')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace 2}
.
This code is used in < DCTG core version of the purchase order schema 85 >
&& info_item(element) && attributes(Lpa) && namespace_attributes(Lpna) && children(Lpe) && validation_attempted(full) && validity(valid)
This code is used in < Rules for elements with complex types 1 > < Rules for elements with simple types 3 >
2.1.3. Elements with simple types
e_comment ::=
[element('http://www.example.com/PO1':comment,Lras,Lre)],
{Guard to check attributes and content of strings 4}
<:> local_name(comment)
&& namespace_name('http://www.example.com/PO1')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for strings 5}
.
e_name_t_USAddress ::= [element(name,Lras,Lre)],
{Guard to check attributes and content of strings 4}
<:> local_name(name)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for strings 5}
.
e_street_t_USAddress ::= [element(street,Lras,Lre)],
{Guard to check attributes and content of strings 4}
<:> local_name(street)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for strings 5}
.
e_city_t_USAddress ::= [element(city,Lras,Lre)],
{Guard to check attributes and content of strings 4}
<:> local_name(city)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for strings 5}
.
e_state_t_USAddress ::= [element(state,Lras,Lre)],
{Guard to check attributes and content of strings 4}
<:> local_name(state)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for strings 5}
.
e_zip_t_USAddress ::= [element(zip,Lras,Lre)],
{
sva_atts_simpletype(Lras,Lpa,Lpna),
sva_content_t_xsd_decimal(Lre,Lpe)
}
<:> local_name(zip)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for decimals 6}
.
e_productName_t_e_item_t_Items ::= [element(productName,
Lras,Lre)],
{Guard to check attributes and content of strings 4}
<:> local_name(productName)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for strings 5}
.
e_quantity_t_e_item_t_Items ::= [element(quantity,
Lras,Lre)],
{
sva_atts_simpletype(Lras,Lpa,Lpna),
sva_content_t_e_quantity_t_e_item_t_Items(Lre,Lpe)
}
<:> local_name(quantity)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
&& type_definition_anonymous('true')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('t_e_quantity_t_e_item_t_Items')
&& type_definition_type(simple)
.
e_USPrice_t_e_item_t_Items ::= [element('USPrice',Lras,Lre)],
{
sva_atts_simpletype(Lras,Lpa,Lpna),
sva_content_t_xsd_decimal(Lre,Lpe)
}
<:> local_name('USPrice')
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
{PSVI properties for decimals 6}
.
e_shipDate_t_e_item_t_Items ::= [element(shipDate,Lras,Lre)],
{
sva_atts_simpletype(Lras,Lpa,Lpna),
sva_content_t_xsd_date(Lre,Lpe)
}
<:> local_name(shipDate)
&& namespace_name('')
{Common infoset properties for elements in po namespace 2}
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('date')
&& type_definition_type(simple)
.
This code is used in < DCTG core version of the purchase order schema 85 >
{
sva_atts_simpletype(Lras,Lpa,Lpna),
sva_content_t_xsd_string(Lre,Lpe)
}
This code is used in < Rules for elements with simple types 3 >
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('string')
&& type_definition_type(simple)
This code is used in < Rules for elements with simple types 3 > < Rules for elements with simple types (PV) 183 >
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('decimal')
&& type_definition_type(simple)
This code is used in < Rules for elements with simple types 3 > < Rules for elements with simple types (PV) 183 >
2.2. Rules for attributes
- The input structure has namespace attributes and other attributes in the same list, while we need them in separate lists so we can assign them to two different infoset properties. So we need to partition the list of attributes. We can perform the partition either before all other processing, or after; doing it afterwards leads to more compact code in this version of the grammar, so we choose that.
- For each non-namespace attribute found, we need to validate it: if it is declared, we need to check it against its declared type. If the attribute is declared with a fixed value, we should check that the value given matches the prescribed value. If the attribute is not declared, we should raise an error, but we'll save that for a later layer. For now, we simply fail instead.
- We need to ensure that attributes required by the complex type are present and that attributes forbidden by the complex type are not present. For any attributes declared with default values, we need to supply an attribute information item with the default value, if the document didn't supply a value. Rather than trying to interleave this with other tasks, we will perform a separate check on attribute occurrences.
- We need to write the predicate sva_atts_TYPEID to wrap all attribute processing for the complex type TYPEID.
2.2.1. Basic pattern
sva_atts_TYPEID(Lras,Lpa,Lpna) :- lras_TYPEID(LpaAll,Lras,[]), /* parse w/ grammar */ partition(LpaAll,LpaPresent,Lpna), /* partition result */ attocc_TYPEID(LpaPresent,Lpa). /* check min, max rules */The logical variables have the following meanings:
- Lpa
- List of parsed attributes (i.e. of node() structures of the kind returned by any DCTG rule) for this complex type, including defaulted attributes
- Lpna
- List of parsed namespace attributes
- Lras
- The list of attribute-value specifications provided by the input structure returned by the SWI Prolog parser.
- LpaAll
- Combined list of parsed-attribute node() structures for all attributes, both namespace attributes and others
- LpaPresent
- List of parsed-attribute nodes for attributes explicitly assigned values in the document instance (without defaulted attributes)
lras_dt ::= [].
lras_dt ::= ras_dt, lras_dt. /* declared attributes */
lras_dt ::= ras_nsd, lras_dt. /* namespace declarations */
lras_dt ::= ras_xsi, lras_dt. /* XSI attributes */
ras_dt ::= [an1=Av], { sva_plf_st1(Av) }.
ras_dt ::= [an2=Av], { sva_plf_st2(Av) }.
Simple types will, of course, have no declared attributes, and
the rules for declared attributes and occurrence-checking
(together with the rules for individual attributes) will be omitted.
Wildcard support can also be added here when needed.2.2.2. Namespace attributes and XSI attributes
/* ras_nsd: grammatical rule for namespace-attribute
* specifications */
ras_nsd ::= [xmlns=DefaultNS]
<:> info_item(attribute)
&& local_name(xmlns)
&& namespace_name('http://www.w3.org/2000/xmlns/')
&& normalized_value(DefaultNS)
&& prefix('##NONE')
&& namespace(DefaultNS).
ras_nsd ::= [xmlns:Prefix=NSName]
<:> info_item(attribute)
&& local_name(Prefix)
&& namespace_name('http://www.w3.org/2000/xmlns/')
&& normalized_value(NSName)
&& prefix(Prefix)
&& namespace(NSName).
Continued in <Grammar rules for XSI attributes 8>This code is used in < Generic DCTG rules for DCTG-encoded schemas 89 >
/* ras_xsi: grammar rule for XSI attribute specifications */
ras_xsi ::=
['http://www.w3.org/2001/XMLSchema-instance':type=Value],
{ sva_plf_t_xsd_qname(Value) }
<:> local_name(type)
&& type_definition_name('QName')
&& type_definition_anonymous('false')
{Common properties for xsi attributes 9}
ras_xsi ::=
['http://www.w3.org/2001/XMLSchema-instance':nil=Value],
{ sva_plf_t_xsd_boolean(Value) }
<:> local_name(nil)
&& type_definition_name('boolean')
&& type_definition_anonymous('false')
{Common properties for xsi attributes 9}
ras_xsi ::=
['http://www.w3.org/2001/XMLSchema-instance':schemaLocation=Value],
{ sva_plf_t_xsd_list_of_qname(Value) }
<:> local_name(schemaLocation)
&& type_definition_name('t_a_schemaLocation')
&& type_definition_anonymous('true')
{Common properties for xsi attributes 9}
ras_xsi ::=
['http://www.w3.org/2001/XMLSchema-instance':noNamespaceSchemaLocation=Value],
{ sva_plf_t_xsd_qname(Value) }
<:> local_name(noNamespaceSchemaLocation)
&& type_definition_name('QName')
&& type_definition_anonymous('false')
{Common properties for xsi attributes 9}
&& info_item(attribute)
&& namespace_name('http://www.w3.org/2001/XMLSchema-instance')
&& normalized_value(Value)
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid).
This code is used in < Grammar rules for XSI attributes 8 >
/* QName has no meaningful restrictions on lexical form, so we * don't check anything. Even the whitespace normalization is * pointless in the core grammar. */ sva_plf_t_xsd_qname(PLF) :- ws_normalize(collapse,PLF,_LF), atom(PLF). sva_plf_t_xsd_list_of_qname(PLF) :- ws_normalize(collapse,PLF,_LF), atom(PLF). sva_plf_t_xsd_boolean(PLF) :- ws_normalize(collapse,PLF,LF), atom_chars(LF,L), lexform_boolean(_,L,[]).
lexform_boolean ::= bool_true. lexform_boolean ::= bool_false. bool_true ::= ['1']. bool_true ::= [t], [r], [u], [e]. bool_false ::= ['0']. bool_false ::= [f], [a], [l], [s], [e].
This code is used in < Generic DCTG rules for DCTG-encoded schemas 89 >
2.2.3. Occurrence checking
attocc_dt(LpaPres,LpaAll) :- atts_present(LpaPres,Lreq), atts_absent(LpaPres,Lnot), atts_defaulted(LpaPres,Ldft,LpaAll).
/* atts_present(Lpa,Lreq): true if a parsed attribute node is present in Lpa for each attribute name in Lreq */ atts_present(_LRAS,[]). atts_present(LRAS,[HRA|RequiredTail]) :- att_present(LRAS,HRA), atts_present(LRAS,RequiredTail). /* An attribute name matches if namespace name and local * name part match */ /* att_present(Lpa,Attname): true if a parsed attribute node * is present in Lpa which has name Attname */ att_present([Pa|_Lpa],NS:Attname) :- Pa^^local_name(Attname), Pa^^namespace_name(NS). att_present([_Pa|Lpa],Attname) :- att_present(Lpa,Attname). /* no base step: if we reach att_present([],Attname) we want * to fail. */Continued in <Utility for checking absent attributes 13>, <Utility for providing defaulted attributes 14>
This code is used in < Generic utilities for DCTG-encoded schemas 88 >
/* atts_absent(Lpa,Ltabu): true if no attribute named in * Ltabu is present in Lpa */ atts_absent(_LRAS,[]). atts_absent(LRAS,[H|T]) :- not(att_present(LRAS,H)), atts_absent(LRAS,T).
/* atts_defaulted(L1,L2,L3): true if L3 has all the * attributes in L1, plus all of the attributes in L2 which * are not also in L1 */ atts_defaulted(Lpa,[],Lpa). atts_defaulted(Lpa,[Padft|Ldft],LpaAll) :- atts_defaulted(Lpa,Ldft,Lpa2), att_merge(Lpa2,Padft,LpaAll).Continued in <Utility for providing defaulted attributes 15>
This code is used in < Utility for providing defaulted attributes (PV) 239 >
/* att_merge(L1,Pa,L2): if Pa is present in L1, then L3 = L1,
otherwise L3 = L1 + Pa. */
att_merge([],Padft,[Padft]).
att_merge([Pa|Lpa],Padft,[Pa|Lpa]) :-
nonvar(Pa), nonvar(Lpa), nonvar(Padft),
Pa^^namespace_name(NS),
Padft^^namespace_name(NS),
Pa^^local_name(Lnm),
Padft^^local_name(Lnm).
att_merge([Pa|Lpa],Padft,Lpa2) :-
nonvar(Pa), nonvar(Lpa), nonvar(Padft),
not( (Pa^^namespace_name(NS),
Padft^^namespace_name(NS),
Pa^^local_name(Lnm),
Padft^^local_name(Lnm) ) ),
att_merge(Lpa,Padft,Lpa2).
2.2.4. Rules for the Purchase-order type
/* sva_atts_TYPENAME(Lras,Lpa,Lpna): true if Lras contains
* an input-form list of attribute specifications which
* is legal for complex type TYPENAME, and which
* corresponds to the list of parsed attributes Lpa plus
* the list of parsed namespace attributes Lpna. */
sva_atts_t_PurchaseOrderType(Lras,Lpa,Lpna) :-
lras_t_PurchaseOrderType(LpaAll,Lras,[]),
partition(LpaAll,Lpa,Lpna),
attocc_t_PurchaseOrderType(LpaPres,Lpa).
lras_t_PurchaseOrderType ::= []
{Grammatical attributes for empty attribute list 22}.
lras_t_PurchaseOrderType ::= ras_t_PurchaseOrderType^^Pa,
lras_t_PurchaseOrderType^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_t_PurchaseOrderType ::= ras_nsd^^Pa,
lras_t_PurchaseOrderType^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_t_PurchaseOrderType ::= ras_xsi^^Pa,
lras_t_PurchaseOrderType^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
ras_t_PurchaseOrderType ::= [orderDate=Value],
{ sva_plf_t_xsd_date(Value) }
{Properties for orderDate attribute 24}.
/* Literally copying the pattern would give us this:
attocc_t_PurchaseOrderType(LpaPres,LpaAll) :-
atts_present(LpaPres,[]),
atts_absent(LpaPres,[]),
atts_defaulted(LpaPres,[],LpaAll).
but that's pointless. Instead, we'll do the equivalent: */
attocc_t_PurchaseOrderType(L,L).
This code is used in < DCTG core version of the purchase order schema 85 >
2.2.5. White-space normalization of simple types
- preserve No normalization is done, the value is not changed (this is the behavior required by [XML 1.0 (Second Edition)] for element content)
/* ws_normalize(Keyword,Input,Output): true if Output is * an atom identical to the whitespace-normalized form of * Input, with the whitespace mode indicated by Keyword. */ ws_normalize(preserve,Atom,Atom).Continued in <Utility for whitespace normalization 18>, <Utility for whitespace normalization 20>
This code is used in < Generic utilities for DCTG-encoded schemas 88 >
- replace All occurrences of #x9 (tab), #xA (line feed) and #xD (carriage return) are replaced with #x20 (space)
ws_normalize(replace,In,Out) :- atom_codes(In,Lcin), ws_blanks(Lcin,Lcout), atom_codes(Out,Lcout).
/* ws_blanks(A,B): where A has any whitespace, B has a blank */ ws_blanks([],[]). ws_blanks([9|T1],[32|T2]) :- ws_blanks(T1,T2). ws_blanks([10|T1],[32|T2]) :- ws_blanks(T1,T2). ws_blanks([13|T1],[32|T2]) :- ws_blanks(T1,T2). ws_blanks([H|T1],[H|T2]) :- not(member(H,[9,10,13])), ws_blanks(T1,T2).
- collapse After the processing implied by replace, contiguous sequences of #x20's are collapsed to a single #x20, and leading and trailing #x20's are removed.
ws_normalize(collapse,In,Out) :- ws_normalize(replace,In,Temp), atom_codes(Temp,Lctemp), ws_collapse(Lctemp,Lcout), atom_codes(Out,Lcout).Continued in <Utility to change whitespace characters to blanks 19>, <Utility for collapsing whitespace 21>
/* ws_collapse(A,B): B is like A, with all strings of blanks * collapsed to single blanks, and leading and trailing * blanks stripped. */ /* ws_collapse/2 strips leading blanks, then calls * ws_collapse/3 */ ws_collapse([],[]). ws_collapse([32|T1],T2) :- ws_collapse(T1,T2). ws_collapse([H|T1],[H|T2]) :- not(H=32), ws_collapse(internal,T1,T2). /* ws_collapse/3 walks past non-blanks, and when it hits a * string of blanks, it drops all but the last one before * a non-blank. */ ws_collapse(internal,[],[]). ws_collapse(internal,[32],[]). ws_collapse(internal,[H|T1],[H|T2]) :- not(H=32), ws_collapse(internal,T1,T2). ws_collapse(internal,[32,32|T1],T2) :- ws_collapse(internal,[32|T1],T2). ws_collapse(internal,[32,H|T1],[32,H|T2]) :- not(H=32), ws_collapse(internal,T1,T2).
2.2.6. Attributes for PurchaseOrderType, continued
<:> attributes([])
This code is used in < Attribute handling for PurchaseOrderType 16 > < Attribute handling for USAddress 25 > < Attribute handling for Items type 27 > < Attribute handling for t_e_item_t_Items 28 > < Attribute handling for simple types 30 >
<:> attributes([Pa|L]) ::- Lpa^^attributes(L)
This code is used in < Attribute handling for PurchaseOrderType 16 > < Attribute handling for USAddress 25 > < Attribute handling for Items type 27 > < Attribute handling for t_e_item_t_Items 28 > < Attribute handling for simple types 30 >
<:> info_item(attribute)
&& local_name('orderDate')
&& namespace_name('')
&& normalized_value(Value)
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('date')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid)
This code is used in < Attribute handling for PurchaseOrderType 16 >
2.2.7. Rules for attributes of other complex types
2.2.7.1. US Address
sva_atts_t_USAddress(Lras,Lpa,Lpna) :-
lras_t_USAddress(LpaAll,Lras,[]),
partition(LpaAll,LpaPres,Lpna),
attocc_t_USAddress(LpaPres,Lpa).
lras_t_USAddress ::= []
{Grammatical attributes for empty attribute list 22}.
lras_t_USAddress ::= ras_t_USAddress^^Pa,
lras_t_USAddress^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_t_USAddress ::= ras_nsd^^Pa, lras_t_USAddress^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_t_USAddress ::= ras_xsi^^Pa, lras_t_USAddress^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
ras_t_USAddress ::= [country='US']
<:> info_item(attribute)
&& local_name('country')
&& namespace_name('')
&& normalized_value('US')
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('NMTOKEN')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid)
.
Continued in <Attribute occurrence checking for USAddress 26>This code is used in < DCTG core version of the purchase order schema 85 >
attocc_t_USAddress(LpaPresent,LpaAll) :-
CountryAtt = node(
attribute(country),
[],
[ (info_item(attribute)),
(namespace_name('')),
(local_name('country')),
(normalized_value('US')),
(type_definition_anonymous('false')),
(type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')),
(type_definition_name('NMTOKEN')),
(type_definition_type(simple)),
(schema_specified(schema)),
(validation_attempted(full)),
(validity(valid))
]),
atts_defaulted(LpaPres,[CountryAtt],LpaAll).
2.2.7.2. Items
sva_atts_t_Items(Lras,Lpa,Lpna) :-
lras_t_Items(LpaAll,Lras,[]),
partition(LpaAll,LpaPres,Lpna).
lras_t_Items ::= []
{Grammatical attributes for empty attribute list 22}.
lras_t_Items ::= ras_nsd^^Pa, lras_t_Items^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_t_Items ::= ras_xsi^^Pa, lras_t_Items^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
This code is used in < DCTG core version of the purchase order schema 85 >
2.2.7.3. Type t_e_item_t_Items
sva_atts_t_e_item_t_Items(Lras,Lpa,Lpna) :-
lras_t_e_item_t_Items(LpaAll,Lras,[]),
partition(LpaAll,LpaPres,Lpna),
attocc_t_e_item_t_Items(LpaPres,Lpa).
lras_t_e_item_t_Items ::= []
{Grammatical attributes for empty attribute list 22}.
lras_t_e_item_t_Items ::= ras_t_e_item_t_Items^^Pa,
lras_t_e_item_t_Items^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_t_e_item_t_Items ::= ras_nsd^^Pa,
lras_t_e_item_t_Items^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_t_e_item_t_Items ::= ras_xsi^^Pa,
lras_t_e_item_t_Items^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
Continued in <PartNum attribute 29>This code is used in < DCTG core version of the purchase order schema 85 >
ras_t_e_item_t_Items ::= [partNum=Value],
{ sva_plf_t_SKU(Value) }
<:> info_item(attribute)
&& local_name('partNum')
&& namespace_name('')
&& normalized_value(Value)
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.example.com/PO1')
&& type_definition_name('SKU')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid)
.
/* one required attribute: partNum */
attocc_t_e_item_t_Items(LpaPres,LpaAll) :-
atts_present(LpaPres,['':partNum]),
atts_absent(LpaPres,[]),
atts_defaulted(LpaPres,[],LpaAll).
2.2.8. Simple types (namespace and XSI attributes)
sva_atts_simpletype(Lras,Lpa,Lpna) :-
lras_sT(LpaAll,Lras,[]),
partition(LpaAll,LpaPres,Lpna).
lras_sT ::= []
{Grammatical attributes for empty attribute list 22}.
lras_sT ::= ras_nsd^^Pa, lras_sT^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
lras_sT ::= ras_xsi^^Pa, lras_sT^^Lpa
{Grammatical attributes for attribute-list recursion 23}.
This code is used in < DCTG core version of the purchase order schema 85 >
2.2.9. Partitioning the list of attributes
partition(LpaAll,LpaPresent,Lpna) :-
LpaAll^^attributes(L),
partition2(L,LpaPresent,Lpna).
partition2([],[],[]).
partition2([Pa|Lpa],LpaPres,[Pa|Lpna]) :-
Pa^^local_name(xmlns),
partition2(Lpa,LpaPres,Lpna).
partition2([Pa|Lpa],LpaPres,[Pa|Lpna]) :-
Pa^^namespace_name('http://www.w3.org/2000/xmlns/'),
partition2(Lpa,LpaPres,Lpna).
partition2([Pa|Lpa],[Pa|LpaPres],Lpna) :-
not(Pa^^local_name(xmlns)),
not(Pa^^namespace_name('http://www.w3.org/2000/xmlns/')),
partition2(Lpa,LpaPres,Lpna).
This code is used in < Generic utilities for DCTG-encoded schemas 88 > < Generic utilities for DCTG-encoded schemas (PV) 95 > < Utilities for checking attribute occurrences (2L) 409 >
Pa^^namespace_name('http://www.w3.org/2000/xmlns/'),
to the rule for namespace attributes declaring default namespaces,
to avoid problems if xmlns were to appear as a
local name in some other namespace.
Since all names beginning with xml
are reserved, though, it would be illegal for xmlns
to appear in an application namespace (other than one defined
in the future by W3C), so I have not added this test.
2.3. Rules for content of complex types
content_t_PurchaseOrderType ::=
e_shipTo_t_PurchaseOrderType^^S,
e_billTo_t_PurchaseOrderType^^B,
opt_e_comment^^C,
e_items_t_PurchaseOrderType^^I
{Children attribute of t_PurchaseOrder 36}
.
opt_e_comment ::= []
{Empty list of children for opt_e_comment nonterminal 34}
.
opt_e_comment ::= e_comment^^Comm
{Children for opt_e_comment nonterminal 35}
.
content_t_USAddress ::=
e_name_t_USAddress^^N,
e_street_t_USAddress^^S,
e_city_t_USAddress^^C,
e_state_t_USAddress^^ST,
e_zip_t_USAddress^^Z
{Children attribute of t_USAddress 33}
.
content_t_Items ::= star_e_item_t_Items^^L
{Children attribute of content_t_Items 40}
.
star_e_item_t_Items ::= []
{Empty list of children for star_e_item_t_Items nonterminal 41}
.
star_e_item_t_Items ::=
e_item_t_Items^^I,
star_e_item_t_Items^^L
{Children for star_e_item_t_Items nonterminal 42}
.
content_t_e_item_t_Items ::=
e_productName_t_e_item_t_Items^^PN,
e_quantity_t_e_item_t_Items^^Q,
e_USPrice_t_e_item_t_Items^^USP,
opt_e_comment^^C,
opt_e_shipDate_t_e_item_t_Items^^S
{Children attribute of t_e_item_t_Items 37}
.
opt_e_shipDate_t_e_item_t_Items ::= []
{Empty list of children for opt_e_shipdate nonterminal 38}
.
opt_e_shipDate_t_e_item_t_Items ::=
e_shipDate_t_e_item_t_Items^^S
{Children for opt_e_shipdate nonterminal 39}
.
This code is used in < DCTG core version of the purchase order schema 85 >
<:> children([N,S,C,ST,Z])
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 > < Rules for purchase-order content models (2L) 389 >
<:> children([])
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 >
<:> children([Comm])
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 >
<:> children(Lpe) ::-
C^^children(CC),
flatten([S,B,CC,I],Lpe)
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 > < Rules for purchase-order content models (2L) 389 >
<:> children(Lpe) ::-
C^^children(CC),
S^^children(SC),
flatten([PN,Q,USP,CC,SC],Lpe)
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 > < Rules for purchase-order content models (2L) 389 >
<:> children([])
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 >
<:> children([S])
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 >
<:> children(List) ::- L^^children(List)
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 > < Rules for purchase-order content models (2L) 389 >
<:> children([])
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 >
<:> children([I|T]) ::- L^^children(T)
This code is used in < Rules for purchase-order content models 32 > < Rules for purchase-order content models (PV) 241 >
sva_content_t_PurchaseOrderType(Lre,Lpe) :- content_t_PurchaseOrderType(Topnode,Lre,[]), Topnode ^^ children(Lpe). sva_content_t_USAddress(Lre,Lpe) :- content_t_USAddress(Topnode,Lre,[]), Topnode ^^ children(Lpe). sva_content_t_Items(Lre,Lpe) :- content_t_Items(Topnode,Lre,[]), Topnode ^^ children(Lpe). sva_content_t_e_item_t_Items(Lre,Lpe) :- content_t_e_item_t_Items(Topnode,Lre,[]), Topnode ^^ children(Lpe).
This code is used in < DCTG core version of the purchase order schema 85 >
2.4. Rules for checking values of simple types
2.4.1. Rules called from top-level element predicates
sva_content_t_xsd_string([PLF],[PLF]) :- sva_plf_t_xsd_string(PLF). sva_content_t_xsd_decimal([PLF],[PLF]) :- sva_plf_t_xsd_decimal(PLF). sva_content_t_xsd_integer([PLF],[PLF]) :- sva_plf_t_xsd_integer(PLF). sva_content_t_xsd_date([PLF],[PLF]) :- sva_plf_t_xsd_date(PLF).
This code is used in < Generic utilities for DCTG-encoded schemas 88 >
sva_content_t_SKU([PLF],[PLF]) :- sva_plf_t_SKU(PLF). sva_content_t_e_quantity_t_e_item_t_Items([PLF],[PLF]) :- sva_plf_t_e_quantity_t_e_item_t_Items(PLF).
This code is used in < DCTG core version of the purchase order schema 85 >
2.4.2. Checking strings
/* In our representation of XML, character data is * represented as atoms. Handling of non-ASCII characters is * OK if they are in UTF8, but the SWI parser currently has * trouble with some named entity references to non-ASCII * characters */ sva_plf_t_xsd_string(LF) :- atom(LF).Continued in <sva_plf rules for built-in types 10>, <Checking decimal and integer values 47>, <Checking date values 49>, <Checking date values 56>, <Checking date values 57>
This code is used in < Generic utilities for DCTG-encoded schemas 88 >
2.4.3. Checking decimals
sva_plf_t_xsd_decimal(PLF) :- ws_normalize(collapse,PLF,LF), atom_chars(LF,L), lexform_decimal(_,L,[]). sva_plf_t_xsd_integer(PLF) :- ws_normalize(collapse,PLF,LF), atom_chars(LF,L), lexform_integer(_,L,[]).
lexform_decimal ::= lexform_integer, fractionalpart.
lexform_integer ::= opt_sign, digits.
fractionalpart ::= [].
fractionalpart ::= decimalpoint.
fractionalpart ::= decimalpoint, opt_digits.
opt_sign ::= [].
opt_sign ::= ['+'].
opt_sign ::= ['-'].
decimalpoint ::= ['.'].
opt_digits ::= [].
opt_digits ::= digits.
/* We supply a 'lexval' property on digits, for use in
* date checking */
digits ::= digit^^D
<:> lexval([Dv]) ::- D^^lexval(Dv).
digits ::= digit^^D1, digits^^Dd
<:> lexval([D1val|Ddval]) ::-
D1^^lexval(D1val),
Dd^^lexval(Ddval).
digit ::= [Ch], { char_type(Ch,digit) }
<:> lexval(Ch).
This code is used in < Generic DCTG rules for DCTG-encoded schemas 89 >
2.4.4. Checking dates
sva_plf_t_xsd_date(PLF) :- ws_normalize(collapse,PLF,LF), atom_chars(LF,Lc), lexform_date(_,Lc,[]).
lexform_date ::= year^^Y, hyphen, month^^M, hyphen, day^^D,
{ Y^^val(Yv), M^^val(Mv), D^^val(Dv), dateok(Yv,Mv,Dv) }.
Continued in <Lexical form for year 51>, <Lexical form for month 54>, <Lexical form for day of month 55>This code is used in < Generic DCTG rules for DCTG-encoded schemas 89 >
/* Years must have at least four digits */
yearnum ::= digit^^D1, digit^^D2, digit^^D3, digits^^Dd
<:> val(Num) ::- D1^^lexval(Dv1),
D2^^lexval(Dv2),
D3^^lexval(Dv3),
Dd^^lexval(Dv4),
flatten([Dv1,Dv2,Dv3,Dv4],LF),
number_chars(Num,LF).
year ::= yearnum^^Y
<:> val(Num) ::- Y^^val(Num).
year ::= ['-'], yearnum^^Y
<:> val(Num) ::- Y^^val(N), Num is 0 - N.
hyphen ::= ['-'].
month ::= ['0'], ['1']. month ::= ['0'], ['2']. ... month ::= ['0'], ['9']. month ::= ['1'], ['0']. month ::= ['1'], ['1']. month ::= ['1'], ['2'].
This code is not used elsewhere.
month ::= ['0'], digit^^D
{ D^^lexval(Dv), number_chars(V,Dv), V > 0 }
<:> val(V).
month ::= ['1'], digit^^D
{ D^^lexval(Dv), number_chars(V,Dv), V < 3 }
<:> val(Val) ::- Val is 10 + V.
This code is not used elsewhere.
month ::= digit^^D1, digit^^D2,
{ D1^^lexval(Dv1),
D2^^lexval(Dv2),
number_chars(Num,[Dv1,Dv2]),
Num > 0,
Num < 13 }
<:> val(Num).
day ::= digit^^D1, digit^^D2,
{ D1^^lexval(Dv1),
D2^^lexval(Dv2),
number_chars(Num,[Dv1,Dv2]),
Num > 0,
Num < 32 }
<:> val(Num).
2.4.5. Checking leap years
dateok(_Y,_M,D) :- D < 29. dateok(_Y,M,29) :- M =\= 2. dateok(_Y,M,30) :- M =\= 2. dateok(_Y,M,31) :- member(M,[1,3,5,7,8,10,12]). dateok(Y,2,29) :- (Y >= 0 -> Yx = Y ; Yx is Y + 1), /* adjust for BC */ 0 is Yx mod 4, Lc is Yx mod 100, L4c is Yx mod 400, leapyearcheck(Lc,L4c).
/* if C is nonzero, it's not a century year, * so it's a leapyear */ leapyearcheck(C,_Q) :- C =\= 0. /* If both numbers are 0, it's a quad-century year, * so it's a leapyear */ leapyearcheck(0,0).
2.4.6. Checking SKUs
sva_plf_t_SKU(PLF) :-
ws_normalize(preserve,PLF,LF),
atom_chars(LF,Charseq),
lexform_t_SKU(_Structure,Charseq,[]).
lexform_t_SKU ::= sku_decimal_part, hyphen, sku_alpha_part.
sku_decimal_part ::= digit, digit, digit.
sku_alpha_part ::= cap_a_z, cap_a_z.
cap_a_z ::= [Char], { char_type(Char,upper) }.
Continued in <Value-checking rules for quantities 59>This code is used in < DCTG core version of the purchase order schema 85 >
2.4.7. Checking quantities
sva_plf_t_e_quantity_t_e_item_t_Items(PLF) :- ws_normalize(collapse,PLF,LF), atom_chars(LF,Lchars), lexform_integer(_,Lchars,[]), number_chars(Num,Lchars), Num < 100.
2.5. Exposing the PSVI
2.5.1. Top-level call
- calls a lower-level predicate to find all the namespaces needed in the document, and return a list of namespace bindings
- writes out the element's generic identifier using an appropriate namespace prefix
- calls lower-level predicates to writing out the element's attributes, its DCTG properties, and its children
- writes out an end-tag
/* write_psvi(ParsedNode): write top-level element. */
write_psvi(Pn) :-
XPSVI = 'http://www.w3.org/People/cmsmcq/ns/xpsvi',
nsbindings(Pn,[ns('##NONE',''),ns(xpsvi,XPSVI)],Nsbs),
Pn ^^ local_name(Gi),
Pn ^^ namespace_name(NS),
Pn ^^ attributes(LPa),
Pn ^^ namespace_attributes(LPna),
Pn ^^ children(LCh),
uname_qname_context(NS,Gi,Nsbs,QN),
write('<'),
write(QN),
psvi_atts(LPa,Nsbs),
write(' xmlns:xpsvi="'), write(XPSVI), write('"'), nl,
psvi_nsatts(LPna,Nsbs),
psvi_props(Pn,Nsbs),
psvi_attprops(LPa,Nsbs),
write('>'),
psvi_children(LCh,Nsbs),
write('</'),
write(QN),
write('>'),
nl.
Continued in <Calculating list of active namespace bindings 61>, <Generating a QName from a namespace name and local name, given a list of namespace bindings 62>, <Writing out attributes in PSVI 65>, <Writing out namespace attributes in PSVI 70>, <Writing out PSVI properties for element 71>, <Writing out PSVI properties for attributes 76>, <Writing out children in PSVI 81>This code is used in < Generic utilities for DCTG-encoded schemas 88 > < Generic utilities for DCTG-encoded schemas (PV) 95 > < Generic utilities for DCTG-encoded schemas (2L) 269 >
2.5.2. Generating current set of namespace bindings
/* nsbindings(Pn,Inherited,Total): true if Total is a list of * namespace bindings, those attached to Pn first, then * the inherited ones. */ nsbindings(Pn,Inherited,Nsbs) :- Pn ^^ namespace_attributes(LPna), nsbind(Inherited,LPna,Nsbs). nsbind(Bindings,[],Bindings). nsbind(Inherited,[Pna | LPna],[ns(Pre,NS) | Nsbs]) :- Pna ^^ prefix(Pre), Pna ^^ namespace(NS), nsbind(Inherited,LPna,Nsbs).Continued in <Finding one binding for a namespace 64>
2.5.3. Generating QName given namespace bindings
/* uname_qname_context(NS,Localname,Nsbs,QName) */
uname_qname_context(NS,Localname,Nsbs,QName) :-
binding(Nsbs,NS,Prefix),
Prefix \= '##NONE',
Prefix \= '',
concat_atom([Prefix,':',Localname],QName).
uname_qname_context(NS,Localname,Nsbs,Localname) :-
binding(Nsbs,NS,'##NONE').
uname_qname_context(NS,Localname,Nsbs,Localname) :-
binding(Nsbs,NS,'').
/* emergency: spit out a Uname if you have to */
uname_qname_context(NS,Localname,Nsbs,Uname) :-
not(binding(Nsbs,NS,_Prefix)),
concat_atom(['{',NS,'}',Localname],Uname).
Continued in <QName generation for attributes 63>
/* Attributes use special rules. */
uname_attname_context('',Localname,_Nsbs,Localname).
uname_attname_context('##NONE',Localname,_Nsbs,Localname).
uname_attname_context(NS,Localname,Nsbs,Qname) :-
NS \= '',
NS \= '##NONE',
uname_qname_context(NS,Localname,Nsbs,Qname).
/* binding(Nsbs,NS,Prefix) : true iff Prefix is bound * to NS in Nsbs. */ binding(Nsbs,NS,Prefix) :- binding(Nsbs,NS,[],Prefix). /* binding/4: return the first binding found for the namespace */ /* If the head of the list of bindings is for our NS, and the * prefix is not occluded, then return the prefix. */ binding([ns(Prefix,NS) | _Nsbs],NS,Occluded,Prefix) :- not(member(Prefix,Occluded)). /* If the head of the list of bindings is for our NS, but the * prefix is occluded, then recur. */ binding([ns(BadPrefix,NS) | Nsbs],NS,Occluded,Prefix) :- member(BadPrefix,Occluded), binding(Nsbs,NS,Occluded,Prefix). /* If the head of the list of bindings is not for our NS, * then recur. */ binding([ns(Prefix0,NS0) | Nsbs],NS,Occluded,Prefix) :- NS0 \= NS, binding(Nsbs,NS,[Prefix0 | Occluded], Prefix).
2.5.4. Writing out attributes
/* psvi_atts(Lpa,Nsbs) : write out the attributes in Lpa, * using the namespace bindings in Nsbs */ psvi_atts([],_). psvi_atts([H|T],Nsbs) :- psvi_att(H,Nsbs), psvi_atts(T,Nsbs).Continued in <Writing out a single attribute in PSVI 66>, <Writing out a single attribute in PSVI 67>, <Writing out an attribute value in PSVI 68>, <Writing out a string without double quotes 69>
/* psvi_att(Pa,Nsbs) : write out the attribute Pa and its
* value, using the namespace bindings in Nsbs */
psvi_att(node(_NT, _LChildren, LProperties),Nsbs) :-
LProperties^^local_name(An),
LProperties^^namespace_name(NS),
LProperties^^normalized_value(SNF),
uname_attname_context(NS,An,Nsbs,QName),
write(' '),
write(QName),
write(' = '),
psvi_snf(SNF),
nl.
psvi_att(X) :-
X \= node(_NT, _LChildren, _LProperties),
nl, write('!! '), write(X), nl, write('!!'), nl.
/* psvi_snf(SchemaNormalizedForm) */
{Rules for writing schema_error_code property values (PV) 255}
psvi_snf(SNF) :-
atom(SNF),
atom_chars(SNF,Lc),
not(member('"',Lc)), !,
write('"'), write(SNF), write('"').
psvi_snf(SNF) :-
atom(SNF),
atom_chars(SNF,Lc),
not(member('''',Lc)), !,
write(''''), write(SNF), write('''').
psvi_snf(SNF) :-
atom(SNF),
atom_chars(SNF,Lc),
member('"',Lc),
member('''',Lc),
write('"'), write_nodq(Lc), write('"').
write_nodq([]).
write_nodq([H|T]) :-
write_nodq(H),
write_nodq(T).
write_nodq('"') :- write('"').
write_nodq(Atom) :- atom(Atom),
Atom \= '"',
write(Atom).
/* psvi_nsatts(Lpa,Nsbs) : write out the attributes in Lpa,
* using the namespace bindings in Nsbs */
psvi_nsatts([],_).
psvi_nsatts([H|T],Nsbs) :- psvi_nsatt(H,Nsbs), psvi_nsatts(T,Nsbs).
/* psvi_nsatt(Pan,Nsbs) : write one NS attribute, ignoring Nsbs */
psvi_nsatt(Pan,_Nsbs) :-
/* We can ignore Nsbs, since the prefix 'xmlns' is reserved. */
Pan ^^ namespace_name('http://www.w3.org/2000/xmlns/'),
Pan ^^ prefix(Prefix),
Pan ^^ namespace(NS),
psvi_nsatt_write(Prefix,NS).
/* psvi_nsatt_write(P,NS) : bind P to NS.
* If P = 'xmlns', write a default namespace declaration */
psvi_nsatt_write('xmlns',NS) :-
write(' xmlns'),
write(' = '),
psvi_snf(NS),
nl.
/* If P != 'xmlns', write a normal namespace declaration */
psvi_nsatt_write(Prefix,NS) :-
Prefix \= 'xmlns',
write(' xmlns:'),
write(Prefix),
write(' = '),
psvi_snf(NS),
nl.
2.5.5. Writing out element properties
psvi_props(node(_NT,_LChildren,LProperties),Nsbs) :- psvi_props(LProperties,Nsbs). psvi_props([],_). psvi_props([H|T],Nsbs) :- psvi_prop(H,Nsbs), psvi_props(T,Nsbs).Continued in <Handling a single PSVI property with a body 72>, <Handling a single PSVI property 73>, <Suppressing some PSVI properties 74>
psvi_prop((Property ::- Body),Nsbs) :- Body, Property =.. [Name, Value], psvi_prop_val(Name,Value,Nsbs).
psvi_prop(Property,Nsbs) :- Property \= (_Head ::- _Body), Property =.. [Name, Value], psvi_prop_val(Name,Value,Nsbs).
psvi_prop_val(attributes,_Value,_Nsbs).
psvi_prop_val(namespace_attributes,_Value,_Nsbs).
psvi_prop_val(inscope_namespaces,_Value,_Nsbs).
psvi_prop_val(validation_context,_Value,_Nsbs).
psvi_prop_val(children,_Value,_Nsbs).
psvi_prop_val(schema_information,Value,Nsbs) :-
uname_attname_context('http://www.w3.org/People/cmsmcq/ns/xpsvi',
schema_information,Nsbs,QName),
write(' '),
write(QName),
write(' = "'),
psvi_schemainfo(Value),
write('"'),
nl.
Continued in <Writing out a single PSVI property 75>, <Rules for writing extract from schema_information property 256>
psvi_prop_val(Name,Value,Nsbs) :-
Name \= attributes,
Name \= namespace_attributes,
Name \= inscope_namespaces,
Name \= validation_context,
Name \= children,
Name \= schema_information,
uname_attname_context('http://www.w3.org/People/cmsmcq/ns/xpsvi',Name,Nsbs,QName),
write(' '),
write(QName),
write(' = '),
psvi_snf(Value),
nl.
2.5.6. Writing out attribute properties
psvi_attprops([],_).Continued in <Writing out PSVI properties for attributes 77>, <Writing out a single PSVI property for attributes 78>, <Writing out a single PSVI property for attributes 79>, <Writing out a single PSVI property for attributes 80>
psvi_attprops([Pa|Lpa],Nsbs) :- psvi_attprop(type_definition_name, [Pa|Lpa], Nsbs), psvi_attprop(type_definition_namespace, [Pa|Lpa], Nsbs), psvi_attprop(type_definition_anonymous, [Pa|Lpa], Nsbs), /* don't waste people's time. This is always the same. psvi_attprop(type_definition_type, [Pa|Lpa], Nsbs), */ psvi_attprop(schema_specified, [Pa|Lpa], Nsbs), psvi_attprop(validation_attempted, [Pa|Lpa], Nsbs), psvi_attprop(validity, [Pa|Lpa], Nsbs).
psvi_attprop(Propname, Lpa, Nsbs) :-
concat_atom(['att_',Propname],Attname),
uname_attname_context(
'http://www.w3.org/People/cmsmcq/ns/xpsvi',Attname,Nsbs,QName),
write(' '),
write(QName),
write(' = "'),
psvi_attprop0(Propname,Lpa,Nsbs),
write('"'),
nl.
psvi_attprop0(_Propname,[],_Nsbs).
psvi_attprop0(Propname,[H|T],Nsbs) :-
H ^^ namespace_name(NS),
H ^^ local_name(LN),
node_prop_val(H,Propname,Value),
( Value = kw(absent)
-> true
; ( uname_attname_context(NS,LN,Nsbs,QName),
write(QName),
write(' '),
atom_chars(Value,Lc),
write_nodq(Lc),
(T = [_H2|_T2]
-> (nl, write(' '))
; true)
)
),
psvi_attprop0(Propname,T,Nsbs).
node_prop_val(node(_,_,LProps),Propname,Value) :- node_prop_val(LProps,Propname,Value). node_prop_val([H|T],Propname,Value) :- H = (Head ::- Body), ( ( Head =.. [Propname, Value], Body ) -> true ; node_prop_val(T,Propname,Value) ). node_prop_val([H|T],Propname,Value) :- H \= (_Head ::- _Body), H =.. [Propname, Value] -> true ; node_prop_val(T,Propname,Value). node_prop_val([],_Propname,kw(absent)).
2.5.7. Writing out children
psvi_children([],_Nsbs). psvi_children([H|T],Nsbs) :- psvi_child(H,Nsbs), psvi_children(T,Nsbs).Continued in <Writing out a PCDATA atom in PSVI 82>, <Writing out a non-Prolog Unicode character in PSVI 83>, <Writing out a child element in PSVI 84>
psvi_child(Atom,_) :- atom(Atom), write(Atom).
psvi_child(entity(N),_) :-
number(N),
write('&#'),
write(N),
write(';').
psvi_child(entity(E),_) :-
not(number(E)),
write('&'),
write(E),
write(';').
psvi_child(node(NT, LChildren, LProperties),Nsbs) :-
( LProperties ^^ info_item(element)
-> psvi_elem(node(NT,LChildren,LProperties),Nsbs)
; LProperties ^^ info_item(textnode)
-> LChildren = [[Atom]],
psvi_child(Atom,Nsbs) ).
psvi_elem(Pn,Nsbs0) :-
nsbindings(Pn,Nsbs0,Nsbs),
Pn^^local_name(Gi),
Pn^^namespace_name(NS),
Pn^^attributes(LPa),
Pn^^namespace_attributes(LPna),
Pn^^children(LCh),
uname_qname_context(NS,Gi,Nsbs,QN),
write('<'),
write(QN),
psvi_atts(LPa,Nsbs),
psvi_nsatts(LPna,Nsbs),
psvi_props(Pn,Nsbs),
psvi_attprops(LPa,Nsbs),
write('>'),
psvi_children(LCh,Nsbs),
write('</'),
write(QN),
write('>').
2.6. Overview and Summary
2.6.1. Top level of program po_core.pl
/* po_core.pl: a definite-clause translation grammar
* representation of the sample purchase-order schema from
* the XML Schema tutorial.
*
* This DCTG was generated by a literate programming system;
* if maintenance is necessary, make changes to the source
* (podctg.xml), not to this output file.
*/
{W3C copyright notice 86}
/* top-level element rules:
* e_ELEMID grammar rules */
{Rules for elements with complex types 1}
{Rules for elements with simple types 3}
/* attribute-list rules:
* sva_atts_TYPEID predicates and helpers (including
* DCTG grammar for attributes of the type) */
{Attribute handling for PurchaseOrderType 16}
{Attribute handling for USAddress 25}
{Attribute handling for Items type 27}
{Attribute handling for t_e_item_t_Items 28}
{Attribute handling for simple types 30}
/* content-model rules for complex types:
* content_TYPEID grammar rules */
{Rules for purchase-order content models 32}
/* pre-lexical and lexical form rules for simple types:
* sva_content_TYPEID, sva_plf_TYPEID */
{Simple-type content rules for purchase-order types 45}
{Value-checking rules for SKU 58}
/* type_sva rules (wrappers) for complex types:
* sva_content_TYPEID */
{Wrapper predicates (sva_content_TYPE) for complex content 43}
/* Copyright (c) 2004, 2005 World Wide Web Consortium, * (Massachusetts Institute of Technology, European Research * Consortium for Informatics and Mathematics, Keio University). * All Rights Reserved. This work is distributed under the * W3C(TM) Software License [1] in the hope that it will be * useful, but WITHOUT ANY WARRANTY; without even the implied * warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. * * [1] http://www.w3.org/Consortium/Legal/2002/copyright-software-20021231 */
This code is used in < DCTG core version of the purchase order schema 85 > < Generic utilities for DCTG-encoded schemas 88 > < Generic DCTG rules for DCTG-encoded schemas 89 > < [File load_core.pl] 90 > < [File test_core.pl] 91 > < DCTG for purchase order schema, partial-validation layer 94 > < Generic utilities for DCTG-encoded schemas (PV) 95 > < Test cases for simple types 167 > < Prolog code for testing lexical forms 168 > < [File load_pv.pl] 257 > < [File test_pv.pl] 258 > < DCTG for purchase order schema, layer 2L 268 > < Generic utilities for DCTG-encoded schemas (2L) 269 > < [File load_2l.pl] 410 > < [File test_2l.pl] 411 > < Utility routines for testing Prolog implementations of po1.xsd 424 >
### Copyright (c) 2004, 2005 World Wide Web Consortium, ### (Massachusetts Institute of Technology, European Research ### Consortium for Informatics and Mathematics, Keio University). ### All Rights Reserved. This work is distributed under the ### W3C(TM) Software License [1] in the hope that it will be ### useful, but WITHOUT ANY WARRANTY; without even the implied ### warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. ### [1] http://www.w3.org/Consortium/Legal/2002/copyright-software-20021231
This code is used in < Shell script sevastopol (purchase-order validator) 319 > < [File regression_test.sh] 425 >
/* Generic utilities for DCTG-encoded schemas
*/
{W3C copyright notice 86}
:- module(xsd_lib_core,
[atts_absent/2, atts_defaulted/3, atts_present/2,
dateok/3,
partition/3,
sva_content_t_xsd_date/2, sva_content_t_xsd_decimal/2,
sva_content_t_xsd_integer/2, sva_content_t_xsd_string/2,
sva_plf_t_xsd_boolean/1,
sva_plf_t_xsd_date/1,
sva_plf_t_xsd_decimal/1,
sva_plf_t_xsd_integer/1,
sva_plf_t_xsd_list_of_qname/1,
sva_plf_t_xsd_qname/1,
sva_plf_t_xsd_string/1,
ws_normalize/3,
write_psvi/1]).
/* NOT exposed:
att_merge/3, att_present/2,
binding/3, binding/4,
leapyearcheck/2,
node_prop_val/3, nsbind/3, nsbindings/3,
psvi_att/1, psvi_att/2, psvi_attprop/3, psvi_attprop0/3,
psvi_attprops/2, psvi_atts/2,
psvi_child/2, psvi_children/2,
psvi_elem/2,
psvi_nsatt/2, psvi_nsatt_write/2, psvi_nsatts/2,
psvi_prop/2, psvi_prop_val/3, psvi_props/2,
psvi_schema_info/1, psvi_snf/1, psvi_snf_ce/1,
psvi_snf/errorcodes/1, psvi_snf/errordetails/1,
uname_attname_context/4, uname_qname_context/4,
write_nodq/1, ws_blanks/2, ws_collapse/2, ws_collapse/3
*/
{Utilities for checking attribute occurrences 12}
{Utility for whitespace normalization 17}
{partition predicate 31}
{sva_content rules for built-in Types 44}
{sva_plf rules for built-in types 46}
{Top-level predicate for writing PSVI 60}
/* Rules for namespace attributes and attributes in the
* XSI namespace */
{W3C copyright notice 86}
{Grammar rules for namespace and XSI attributes 7}
/* Lexical forms for built-in types (DCTG rules) */
{Lexical form for decimal and integer 48}
{Lexical form for year 50}
{Lexical form for boolean 11}
2.6.2. Basic patterns
- The content model of each complex type T is translated into a grammar which is used to validate the contents of each element declared as having type T. The grammar corresponding to a given content model defines a regular language; the only recursion in the grammar is to handle repetition. Elements found in the content are treated, for purposes of this regular grammar, as if they were lexical items; the recursive validation of their content is accomplished by separate calls to the parser.The grammar for the content model of a complex type TYPEID has start-symbol content_TYPEID.For example:
content_t_USAddress ::= e_name_t_USAddress^^N, e_street_t_USAddress^^S, e_city_t_USAddress^^C, e_state_t_USAddress^^ST, e_zip_t_USAddress^^Z <:> children([N,S,C,ST,Z]).
In some cases, the grammar will have several rules, to cover repetitions and choices.A wrapper function named sva_content_TYPEID calls the grammar and calculates the list of parsed nodes to be used as the children property of the parent element. - The attributes associated with each complex type TYPEID are checked by an attribute-checking grammar which also checks for namespace declarations and attributes in the XSI namespace.The predicate used to perform attribute checking for a given complex type TYPEID is called sva_atts_TYPEID; it calls the grammar for the attributes of TYPEID, which has the start-symbol lras_TYPEID, then partitions the result into normal attributes and namespace attributes, and checks to make sure all required attributes are present and supplies default values where neeed.The generic pattern for a type named TYPEID is:
sva_atts_TYPEID(Lras,Lpa,Lpna) :- /* parse against grammar of attributes */ lras_TYPEID(LpaAll,Lras,[]), /* partition the result */ partition(LpaAll,LpaPresent,Lpna), /* check min, max occurrence rules */ attocc_TYPEID(LpaPresent,Lpa).
The auxiliary predicate attocc_TYPEID is used to check for required and forbidden attributes. - Individual elements in the document instance are matched by trivial grammar rules which validate their attributes and contents by recursively invoking the parser to check the attributes and the content of the element.The pre-terminal symbol which matches a single element with generic identifier GI is named e_GI.The pattern for such rules is:
e_NCName ::= [element(NS:GI,Lras,Lre)], { sva_atts_TYPEID(Lras,Lpa,Lpna), sva_content_TYPEID(Lre,Lpe) } <:> attributes(Lpa) && namespace_attributes(Lpna) /* etc. */ .When the element has a simple type, the pattern is identical except that it uses a standard sva_atts_simpletype predicate instead of sva_atts_TYPEID. - Simple types are checked by (a) a grammar defining their legal lexical forms, and (b) ad hoc rules checking other facets.A pre-lexical form which occurs as the content of an element associated with simple type TYPEID is matched by a trivial grammar rule for the non-terminal sva_content_TYPEID. That rule has semantic actions which fire to check the prelexical form and value. The pattern is:
sva_content_TYPEID(Atom,Atom) :- sva_plf_TYPEID(Atom).
The predicate which checks whether a lexical form is legal for a given simple type TYPEID is named sva_plf_TYPEID; it performs whitespace normalization, calls the parser to check the lexical form, and performs any value-related tests itself. The pattern issva_plf_TYPEID(PLF) :- ws_normalize(WSkeyword,PLF,LF), atom_chars(LF,Charseq), lexform_TYPEID(_Structure,Charseq,[]), /* additional value checks */ .
The grammar for the lexical form of a simple type TYPEID has start-symbol lexform_TYPEID.For example:lexform_sku ::= sku_decimal_part, hyphen, sku_alpha_part. sku_decimal_part ::= digit, digit, digit. sku_alpha_part ::= cap_a_z, cap_a_z. cap_a_z ::= [Char], { char_type(Char,upper) }.
2.6.3. Naming conventions
- e_GI: refers to a top-level element. Also used as a grammar non-terminal.
- e_GI_TYPEID: refers to an element with generic identifier GI local to type TYPEID. Also used as a grammar non-terminal.
- t_NAME: refers to a top-level type.
- t_ELEMID: refers to a type local to the element with id ELEMID.
- t_xsd_NAME: denotes a built-in simple type.
- sva_atts_TYPEID(+Lras,-Lpa,-Lpna): predicate true iff Lras is a list of raw attribute-value pairs, in Anjewierden/Wielemaker form (AWF), which is legal on elements of complex type TYPEID, and which corresponds to the union of Lpa (a list of parsed attribute nodes) and Lpna (a list of parsed namespace-attribute nodes)
- sva_content_TYPEID(Lre,Lpe): true iff Lre is a list of raw elements and text nodes in AWF, which are legal as content of an element with type TYPEID, when parsed appropriately correspond to the list of parsed element and text nodes Lpe.
- sva_plf_TYPEID(PLF): true iff atom PLF is a legal pre-lexical form and denotes a legal value for simple type TYPEID.
- ELEMID (i.e. e_GI or e_GI_TYPEID): parses one occurrence of the element type in question, producing parsed element node.
- content_TYPEID: parses the content of an element of type TYPEID; the rule is a translation of the content model and produces a list of parsed nodes.
- lras_TYPEID: a list of attributes legal for type TYPEID.
- ras_TYPEID: a single attribute legal for type TYPEID.
- ras_nsd: a single namespace attribute.
- ras_xsi: a single attribute in the XSI namespace.
- lexform_TYPEID: lexical form for type TYPEID.
2.6.4. Generic tools
- partition(+LpaAll, -LpaPresent, -Lpna): true iff LpaAll is the union of LpaPresent (normal parsed attribute nodes) and Lpna (parsed namespace attribute nodes), with the latter two disjoint.
- atts_present(+Lpa, +Lreq): true iff every name in Lreq is the name of a parsed attribute node in Lpa.
- atts_absent(+Lpa, +Lno): true iff no name in Lno is the name of a parsed attribute node in Lpa.
- atts_defaulted(+Lpa, +Ldfts, -LpaAll): true iff LpaAll contains every parsed attributed node in Lpa, plus additionally every node in Ldfts which has a name which doesn't match anything in Lpa.
- ws_normalize(+Kw, +In, -Out): true iff applying to In the whitespace normalization associated with Kw yields Out; In and Out are atoms. There are three cases: Kw must be one of preserve, replace, or collapse.
- flatten([L0,L1, ...], L)
- concat_atom
2.6.5. Convenience files for the core grammar
2.6.5.1. The load_core.pl program
/* load_core.pl: load the core DCTG grammar and other
* auxiliary material. */
{W3C copyright notice 86}
/* The directory where this file lives is the reference point
* for all the directories we care about.
* Assert it as a file-search-path alias during load time
* (afterwards is too late).
*/
?- prolog_load_context(directory,Dir),
assert(file_search_path(po_bin,Dir)).
file_search_path(dctg,po_bin('..')).
file_search_path(po_tests,dctg('testdata/tests')).
file_search_path(po_out,dctg('testdata/tmp')).
file_search_path(po_lib,dctg('lib')).
?- ensure_loaded(po_lib('msmdctg.pl')).
?- ensure_loaded(po_bin('xsd_lib_core.pl')).
?- absolute_file_name(po_bin('xsd_lib_core.dctg'),Grammar),
dctg_reconsult(Grammar).
?- absolute_file_name(po_bin('po_core.pl'),Grammar),
dctg_reconsult(Grammar).
load_file(File,Structure) :-
load_structure(File,Infoset,[dialect(xmlns),space(remove)]),
e_purchaseOrder(Structure,Infoset,[]).
load_go_file(File) :-
load_file(File,Structure),
write_psvi(Structure).
2.6.5.2. The test_core.pl program
/* test_core.pl: run tests on the core DCTG grammar */
{W3C copyright notice 86}
?- prolog_load_context(directory,Dir),
assert(file_search_path(po_bin,Dir)).
?- ensure_loaded(po_bin('load_core.pl')).
?- ensure_loaded(po_bin('coretests.pl')).
Continued in <Predicates to load and run test files 92>, <Predicates to load and run test files 93>load_test(File,Structure) :- potestfile(File,_RC), absolute_file_name(po_tests(File),Testfile), load_file(Testfile,Structure). load_go_test(File) :- potestfile(File,_RC), absolute_file_name(po_tests(File),Testfile), load_go_file(Testfile).
/* run_test(File,Flag): parse File, write psvi, check top-level output */
run_test(File,Flag) :-
write('Testing '), writeq(File), write(': '),
potestfile(File,ExpectedRC),
absolute_file_name(po_tests(File),Testfile),
load_structure(Testfile,Structure,[dialect(xmlns),space(remove)]),
( ExpectedRC = valid
-> ( e_purchaseOrder(Pn,Structure,[]),
Pn ^^ validity(RC) )
; ( ( not(e_purchaseOrder(_Pn,Structure,[])),
RC = 'invalid' )
-> true
; ( e_purchaseOrder(Pn,Structure,[]),
Pn ^^ validity(RC) ))),
( ( RC = valid, Flag = psvi )
-> write_psvi_for_xmlfile(Pn,File)
; true ),
report(RC,ExpectedRC).
write_psvi_for_xmlfile(Pn,Testfile) :-
atom_concat(Stem,'.xml',Testfile),
concat_atom([Stem,'.psvi.core.xml'],PSVIfilename),
absolute_file_name(po_out(PSVIfilename), PSVIfile),
telling(Stdout), tell(PSVIfile),
write_psvi(Pn),
told, tell(Stdout), !.
report(RC,RC) :- write('ok ('), write(RC), write(' as expected)'), nl.
report(RC,ExpectedRC) :-
RC \= ExpectedRC,
write('!!! NOT OK: expected '),
writeq(ExpectedRC),
write(', got '),
writeq(RC),
write(' !!!'),
nl.
good :- good(nopsvi).
bad :- bad(nopsvi).
ugly :- ugly(nopsvi).
good(Option) :-
run_tests(valid,Option).
bad(Option) :-
run_tests(invalid,Option).
ugly(Option) :-
run_tests(valid,Option),
run_tests(invalid,Option).
run_tests(RC,Option) :-
bagof(File,potestfile(File,RC),Files),
member(F,Files),
run_test(F,Option),
fail.
run_tests(_RC,_Option).
2.7. Evaluation
- E35, which supplies a duplicate attribute; in theory, the upstream XML parser should be catching that well-formedness error, and so I have chosen not to modify the grammar to catch it.
- E125 (a through f), which provide bad values for xsi:type, which the core grammar does not check.
- E127a, which provides xsi:nil='false' on the purchase-order element; this is illegal because the purchase-order element type is not nillable.
- E129, which provides a bad value (illegal URI, two hash marks) for xsi:schemaLocation on the purchase-order element.
- E131a, which provides a bad value (multiple URIs) for xsi:noNamespaceSchemaLocation on the purchase-order element.
- E131b, which provides a bad value (bad URI) for xsi:noNamespaceSchemaLocation on the purchase-order element.
3. Handling mixed content and substitution groups
3.1. Mixed content
content_t_PurchaseOrderType ::=
opt_pcdata^^P1,
e_shipTo_t_PurchaseOrderType^^S,
opt_pcdata^^P2,
e_billTo_t_PurchaseOrderType^^B,
opt_pcdata^^P3,
opt_e_comment^^C,
e_items_t_PurchaseOrderType^^I,
opt_pcdata^^P4
<:> children(Lpe) ::-
C^^children(CC),
P1^^children(PC1),
P2^^children(PC2),
P3^^children(PC3),
P4^^children(PC4),
flatten([PC1,S,PC2,B,PC3,CC,I,PC4],Lpe).
opt_e_comment ::= []
<:> children([]).
opt_e_comment ::= e_comment^^Comm, opt_pcdata^^P
<:> children(CC) ::-
P^^children(PC),
flatten([Comm,PC],CC).
content_t_Items ::= opt_pcdata^^P,
star_e_item_t_Items^^L
<:> children(List) ::-
P^^children(PC),
L^^children(Lc),
flatten([PC,Lc],List).
star_e_item_t_Items ::= []
<:> children([]).
star_e_item_t_Items ::=
e_item_t_Items^^I,
opt_pcdata^^P,
star_e_item_t_Items^^L
<:> children([I,P|T]) ::- L^^children(T).
opt_pcdata ::= [] <:> children([]). opt_pcdata ::= [Atom] <:> children([Atom]).Note that the children property records the atom matched by the rule, so that it can be included among the children of the parent element.
opt_pcdata ::= []
<:> children([]).
opt_pcdata ::= pcdata_unit^^U, opt_pcdata^^P
<:> children([Unit|PC]) ::-
U^^children(Unit),
P^^children(PC).
pcdata_unit ::= [Atom]
<:> children(Atom).
pcdata_unit ::= [entity(Arg)]
<:> children(entity(Arg)).
3.2. Substitution groups
e_H ::= e_E.The only complication is that every property of E must be copied upward to H. Thus if we added an element po with type t_po in the substitution group of purchaseOrder, the rules will take the form:
e_po ::= [
element('http://www.example.com/PO1':purchaseOrder,
Lras,Lre)],
{
sva_atts_t_po(Lras,Lpa,Lpna),
sva_content_t_po(Lre,Lpe)
}
<:> local_name(po)
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('t_po')
&& type_definition_type(complex)
&& attributes(Lpa)
&& namespace_attributes(Lpna)
&& children(Lpe)
&& namespace_name('http://www.example.com/po1_extended')
&& validation_attempted(full)
&& validity(valid)
.
e_purchaseOrder ::= e_po^^E,
<:> local_name(LN) ::- E^^local_name(LN)
&& type_definition_anonymous(TDA) ::- E^^type_definition_anonymous(TDA)
&& type_definition_namespace(TDNS) ::- E^^type_definition_namespace(TDNS)
&& type_definition_name(TDN) ::- E^^type_definition_name(TDN)
&& type_definition_type(TDT) ::- E^^type_definition_type(TDT)
&& attributes(Lpa) ::- E^^attributes(Lpa)
&& namespace_attributes(Lpna) ::- E^^namespace_attributes(Lpna)
&& children(Lpe) ::- E^^children(Lpe)
&& namespace_name(Ns) ::- E^^namespace_name(Ns)
&& validation_attempted(VA) ::- E^^validation_attempted(VA)
&& validity(Valid) ::- E^^validity(Valid)
.
e_po ::= e_big_po <:> local_name(LN) ...taken together with those already given will ensure that big_po can be substituted for purchaseOrder.
lit_ELEMID ::= [element(N:GI,Lras,Lre)],
{
sva_atts_TYPEID(Lras,Lpa,Lpna),
sva_content_TYPEID(Lre,Lpe)
}.
Content-model rules will still refer to e_ +
ELEMID, but we have now provided a level of
indirection which we will use to allow either just the literal
element itself or any element in its substitution group to
appear in the instance.
In our examples, we thus have:
lit_e_purchaseOrder ::= [
element('http://www.example.com/PO1':purchaseOrder,
Lras,Lre)],
{ sva_atts_t_PurchaseOrderType(Lras,Lpa,Lpna),
sva_content_t_PurchaseOrderType(Lre,Lpe) }.
lit_e_po ::= [
element('http://www.example.com/po1_extended':po,
Lras,Lre)],
{ sva_atts_t_po(Lras,Lpa,Lpna),
sva_content_t_po(Lre,Lpe) }.
lit_e_big_po ::= [
element('http://www.example.com/po1_extended':big_po,
Lras,Lre)],
{ sva_atts_t_big_po(Lras,Lpa,Lpna),
sva_content_t_big_po(Lre,Lpe) }.
Or for the E, F, H
example:
lit_e_H ::= [element('H',Lras,Lre)] ...
lit_e_E ::= [element('E',Lras,Lre)] ...
lit_e_F ::= [element('F',Lras,Lre)] ...
subst_e_purchaseOrder ::= lit_e_purchaseOrder. subst_e_po ::= lit_e_po. subst_e_big_po ::= lit_e_big_po. subst_e_H ::= lit_e_H. subst_e_E ::= lit_e_E. subst_e_F ::= lit_e_F.Next, we note that E is in the substitution group of H and so forth, by writing rules relating the substitution group of the head to the substitution group of the member:
subst_e_purchaseOrder ::= subst_e_po. subst_e_po ::= subst_e_big_po. subst_e_H ::= subst_e_E. subst_e_E ::= subst_e_F.Note that this ensures the transitive nature of group membership: anywhere the non-terminal subst_e_purchaseOrder is allowed, the non-terminal subst_e_po is allowed, and anywhere the non-terminal subst_e_po is allowed, the non-terminal subst_e_big_po is allowed, and that in turn includes elements of type big_po.
e_purchaseOrder ::= subst_e_purchaseOrder. e_po ::= subst_e_po. e_big_po ::= subst_e_big_po. e_H ::= subst_e_H. e_E ::= lit_e_E. /* N.B. substitution is blocked. */ e_F ::= subst_e_F.
4. The PV grammar: Validity, validation-attempted, and error handling
4.1. Goals and overview
4.1.1. Additional PSVI properties
4.1.2. Handling invalid and partially valid input
sva_content_t_PurchaseOrderType(Lre,Lpe,ok) :- content_t_PurchaseOrderType(Lre,Lpe,[]). sva_content_t_PurchaseOrderType(Lre,Lpe, error(cvc-complex-type.2.4)) :- not(content_t_PurchaseOrderType(Lre,Lpe,[])).or, using the Prolog if-then-else construct,
sva_content_t_PurchaseOrderType(Lre,Lpe,ReturnCode) :-
(content_t_PurchaseOrderType(Lpe,Lre,[])
-> ReturnCode = ok
; ReturnCode = error(cvc-complex-type.2.4)
).
4.1.3. Validation against element declaration
4.1.4. Summary of goals
- Add more PSVI properties to the parsed nodes.
- Succeed on invalid data, and produce parsed nodes with appropriate values in the [validity] property and appropriate error diagnostics in the [schema error code] properties.
- Use the error codes suggested by [W3C 2001b] to diagnose the errors caught by the grammar. (But we will not attempt to change the grammar in order to test for, and raise, every identifiable error, lest it involve a radical restructuring of the grammar. That is a task for a separate paper.)
4.1.5. Overview of PV grammar
- Rules for validating (pre-)lexical forms against simple types,
given in section 4.2, “Validation of simple types”. For
each simple type TYPEID in the schema, we define:
- sva_content_TYPEID(Lre, Lexical_Form, Lerr): a wrapper for the other rules, called for elements with simple content but not for attributes.
- sva_plf_TYPEID(Lre, LF, PN, Lerr): takes a pre-lexical form Lre (in Anjewierden/Wielemaker form, a series of atoms and entity structures) and translates it into a list of characters (or character codes) before calling other predicates to produce a lexical form LF, a parsed node (with DCTG attributes), and a list of errors.
- plf_wlv_TYPEID(Lre, LF, Lerr): performs whitespace normalization and calls the next predicate in the chain.
- plf_lv_TYPEID(LF, Lerr): checks the lexical form against the DCTG grammar for the type and calls predicates which perform any necessary value checks.
- lexform_TYPEID: DCTG rule for the lexical space of the given type.
- aelist_codes(Lre, Lcodes, Lerr): translates a list of atoms and entity structures into a list of character codes; return a list of errors if needed (defined in section 4.2.3.2, “Converting from Anjewierden/Wielemaker form to list of codes”).
- aelist_chars(Lre, Lcodes, Lerr): translates a list of atoms and entity structures into a list of single-character atoms; return a list of errors if needed (defined in section 4.2.4.2, “Converting from Anjewierden/Wielemaker form to characters”).
- ws_normalize(Keyword, Input, Output, Lerr): performs white-space normalization (defined in section 4.2.5, “White space normalization in the PV grammar”).
- Rules to match individual elements, validate against their
element declarations and types, and supply grammatical
attributes, given in section 4.3, “Validation of elements”. For each element type in the schema, there is
- a DCTG rule named ELEMID: matches one occurrence of the element (or of an element in its effective substitution group).
- a Prolog rule named sva_elemdecl_ELEMID: checks an element instance against the element declaration.
- calc_validation_attempted(Lpa, Lpe, VA): calculates the validation attempted property (VA) for an element, given lists of its parsed attributes (Lpa) and parsed child elements (Lpe).
- calc_validity(Lerr0, Lerr1, Lerr2, Lpa, Lpe, V): calculates the validity property (V) for an element, given error lists from its local validation and lists of its parsed attributes (Lpa) and parsed child elements (Lpe).
- Rules to validate elements against their element declarations: sva_elemdecl_ELEMID(Lras, Lre, Lnsb, Lerr)
- Rules for validating attribute lists, given in section 4.4, “Validation of attributes”. For each complex type
TYPEID there are several predicates:
- lras_TYPEID: a DCTG rule for a list of attributes for this type.
- ras_TYPEID: a DCTG rule for an individual attribute on an element of this type (one rule for each declared attribute, plus one for undeclared attributes).
- attocc_TYPEID(LpaPresent, LpaAll): Prolog rules for checking attribute occurrence constraints for the given type; this is only supplied for types that actually have occurrence constraints.
- sva_atts_TYPEID(Lras, Lpa, Lpna, Lerr): a Prolog wrapper for the DCTG rules.
- ras_nsd: a DCTG rule for a namespace declaration.
- ras_xsi: a DCTG rule for an attribute from the xsi namespace.
- A Prolog wrapper called sva_atts_simpleType(Lras, Lpa, Lpna, Lerr) wrapped around:
- A DCTG rule lras_sT, which just expands to ras_nsd and ras_xsi.
- Rules for validating content against content models,
given in section 4.5, “Validation of complex content”.
These are of two kinds:
- content_TYPEID: DCTG rules representing the content model of type TYPEID.
- sva_content_TYPEID(Lre, Lpe, Lerr): a Prolog wrapper for the call to the DCTG rule; if the grammar fails, it calls a fallback rule to skip the content.
- A top-level rule for starting schema-validity assessment; this is given in 4.6.1, “Starting schema-validity assessment”.
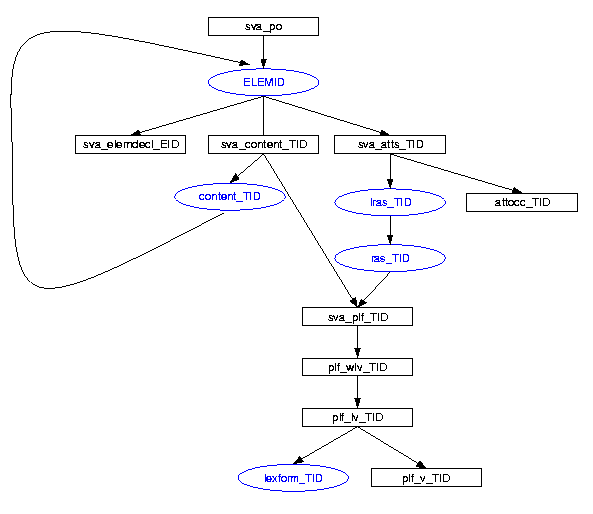 Figure 2: Abstract call graph for the PV layer
Figure 2: Abstract call graph for the PV layer
/* po_pv.pl: a definite-clause translation grammar representation
* of the sample purchase-order schema from the XML Schema tutorial.
* This is version PV, which does partial validation.
*
* This DCTG was generated by a literate programming system; if
* maintenance is necessary, make changes to the source (podctg.xml)
* not to this output file.
*/
{W3C copyright notice 86}
/* simple-type rules:
* sva_content_TYPEID, sva_plf_TYPEID, value checks */
{Checking (pre-) lexical forms against schema-specific types (PV) 165}
/* single-element rules: e_ELEMID */
{Rules for elements with complex types (PV) 179}
{Rules for elements with simple types (PV) 183}
/* validating elements against their element declarations */
{Rules for validating against element declarations (PV) 203}
/* attribute-list rules:
* sva_atts_TYPEID, lras_TYPEID, ras_TYPEID */
{Attribute rules for complex types (PV) 214}
{Attribute handling for simple types (PV) 233}
/* content-model rules:
* sva_content_TYPEID, content_TYPEID */
{Complex-content rules (PV) 240}
{Simple-type content rules for purchase-order types (PV) 162}
/* type derivation information */
{Top-level components in the purchase-order schema (PV) 198}
{Schema-specific derivation information (PV) 200}
{Derivation information for built-ins (PV) 201}
/* Information about element/type bindings */
{Element-type bindings for purchase-order schema (PV) 202}
/* xsd_lib_pv.pl: library routines not specific to any one schema.
* This is version PV, which does partial validation.
*
* This code was generated by a literate programming system; if
* maintenance is necessary, make changes to the source (podctg.xml)
* not to this output file.
*/
{W3C copyright notice 86}
/* Utilities for working with simple types and
* their values */
{Generic predicates for simple types (PV) 166}
/* Rules for checking pre-lexical form of builtin types */
{Checking pre-lexical forms against built-in types (PV) 163}
/* Maintaining in-scope namespaces property */
{Calculating in-scope namespaces (PV) 185}
/* Resolving QNames */
{Resolve QName to type (PV) 195}
{Expand QName to expanded name triple (PV) 196}
{Mapping from expanded name to type ID (PV) 197}
/* Checking type derivations (incomplete implementation) */
{Type derivation hierarchy for purchase-order schema (PV) 199}
/* Rules for checking elements against element declarations */
{Check value given in xsi:type (PV) 189}
/* Rules for calculating validity of elements */
{Calculating validation-attempted property (PV) 210}
/* Rules for mixed content */
{Distinguishing mixed-content error from child-sequence error (PV) 242}
{The content_skip predicate (PV) 245}
{The grammar rule atts_skip (PV) 249}
/* Rules for simple content */
{sva_content rules for built-in types (PV) 161}
/* Generic rules for validating attributes */
{Generic rules for attribute validation (PV) 215}
/* Rules for xsi attributes and namespace declarations */
{Grammar rules for namespace and XSI attributes (PV) 234}
/* Rules for attribute occurrence checking */
{Utilities for checking attribute occurrences (PV) 237}
/* old stuff from core layer */
{partition predicate 31}
/* DCTG rules for built-in simple types */
{Grammar rules for lexical forms of built-in types (PV) 164}
/* writing out the PSVI */
{Top-level predicate for writing PSVI 60}
4.2. Validation of simple types
4.2.1. Conventions for validating elements and lexical forms
4.2.1.1. Checking simple element content and checking lexical forms
- Lre (‘list of raw elements’) is the input list of atoms (for PCDATA), entity() structures (for characters not in the Prolog character set), and element() structures provided by the upstream parser. Of course, if any of the latter occur in simple content, we'll have to raise an error.
- Lerr (‘list of error codes’) is either a list of error codes or (at the uppermost levels) the keyword ok; if the list is empty, or the value is ok, the element's content is valid with respect to the type involved.
- LF (‘lexical form’) is the lexical form checked (i.e. what we get after performing whitespace processing on the pre-lexical form); for now we'll assume this is a list of single-character atoms, but we could change the convention later.
- PN (‘parsed node’) is the parsed node returned by the DCTG grammar rules when parsing the lexical form.
4.2.1.2. Pattern for sva_content_TYPEID predicates
/* sva_content_TYPEID(+Lre, -LF, -Lerrs): true iff validating
* raw element list Lre against type TYPEID produces
* lexical form LF and error list Lerrs. */
sva_content_TYPEID(Lre,LF,[]) :-
sva_plf_TYPEID(Lre,LF,_PN,[]).
sva_content_TYPEID(Lre, LF,
[ElemError,LfError|Errors]) :-
sva_plf_TYPEID(Lre,LF,_PN,[LfError|Errors]),
ElemError = error(cvc-type.3.1.3).
sva_content_TYPEID(Lre,LF,Lerr) :-
sva_plf_TYPEID(Lre,LF,_PN,Lerr0),
( Lerr0 = []
-> Lerr = []
; append([error(cvc-type.3.1.3)],
Lerr0,
Lerr)
).
This is not quite satisfactory, because it fails to suggest
any relationship between the cvc-type.3.1.3 error
and the others. In fact, there is a causal relationship
between them: they cause the cvc-type.3.1.3.
To express this, we'll allow our error
structure to contain other error structures.
sva_content_TYPEID(Lre,LF,Lerr) :-
sva_plf_TYPEID(Lre,LF,_PN,Lerr0),
( Lerr0 = []
-> Lerr = []
; Lerr = [error(
cvc-type.3.1.3,
cause(Lerr0))]
).
This is an improvement on the corresponding predicates of the core,
but it's not finished: (1) this predicate should also handle empty
elements, (2) it should check for elements among the children, and (3)
the error reporting should have something more than a keyword. The
full definition of the sva_content_TYPEID predicates
for level PV is found below (4.3). The full definition of the
sva_plf_TYPEID predicates is in sections 4.2.3 through 4.2.8.
4.2.1.3. Pattern for sva_plf_TYPEID predicates
/* sva_plf_TYPEID(+Lre, -LF, -PN, -Lerrs): true iff validating * raw element list Lre as a pre-lexical form against type * TYPEID produces lexical form LF and error list Lerrs. */ sva_plf_TYPEID(PLF,LF,PN) :- aelist_chars(PLF,Lchars), ws_normalize(Keyword_Method,Lchars,LF) lexform_TYPEID(PN,LF,[]), vcheck1(PN), vcheck2(PN), ... /* checks on value */ vcheckN(PN).where
- aelist_chars converts the pre-lexical form from AWF (a series of atoms and entity structures) into a list of character atoms (or, for Unicode characters which are not legal Prolog characters, integers). An analogous predicate named aelist_codes converts the input list into a sequence of integers. We check the lexical form against the resulting lists of characters plus integers or just integers.
- ws_normalize is substantially the same as in the core grammar described above
- lexform_TYPEID is the grammar rule for the lexical form, expressed in terms of characters just as in the core grammar; it produces a parsed node (PN) which is used as the basis for any checks on the value as opposed to the lexical form
- vcheck1, vcheck2, etc. are a series of type-specific tests to check the value against the value-specific constraints on the type
sva_plf_TYPEID(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars)
-> (ws_normalize(Keyword,Lchars,LF)
-> (lexform_TYPEID(PN,LF,[])
-> (vcheck1(PN)
-> (vcheck2(PN)
-> (vcheckN(PN)
-> Lerr = []
; Lerr = ['failed vcheckN'])
; Lerr = ['failed vcheck2'])
; Lerr = ['failed vcheck1'])
; Lerr = ['bad lexical form'])
; LF = [],
Lerr = ['whitespace normalization failed (huh?!!)'])
; Lerr = ['aelist_chars failed'])
.
For now, we represent errors as simple atoms containing a brief
natural-language description; this is too simple for real work, but
suffices for working out the pattern in more detail.
sva_plf_TYPEID(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars)
-> plf_wlv_TYPEID(Lchars, LF, PN, Lerr)
; Lerr = ['aelist_chars failed']).
/* plf_wlv_TYPEID(+Lre, -LF, -Lerr) is true iff parsing the list
* of characters Lchars as a pre-lexical form of type TYPEID
* produces lexical form LF and list of errors Lerr. In the
* process, we:
* - do whitespace normalization (w),
* - check lexical form (l),
* - check value (v)
* which gives us the 'wlv' in the name of the predicate.
*/
plf_wlv_TYPEID(Lchars,LF,PN,Lerr) :-
(ws_normalize(KEYWORD,Lchars,LF)
-> plf_lv_TYPEID(LF,PN,Lerr)
; Lerr = ['whitespace normalization failed (can this even HAPPEN?)'],
LF = [],
PN = 'unparsed').
/* plf_lv_TYPEID(+LF, PN, -Lerr) is true iff parsing the list of
* characters LF as a lexical form of type TYPEID produces
* the parsed node PN and the list of errors Lerr. In the
* process, we check the lexical form (l) and the value (v),
* which gives us the 'lv' in the name of the predicate. */
plf_lv_TYPEID(LF,PN,Lerr) :-
(lexform_TYPEID(PN,LF,[])
-> plf_v_TYPEID(PN,Lerr)
; Lerr = ['parse of lexical form failed'],
LF = [],
PN = 'unparsed').
/* plf_v_TYPEID(+ParsedNode, -Lerr) is true iff checking the
* parsed DCTG node ParsedNode against the value constraints
* of type TYPEID produces the list of errors Lerr. */
plf_v_TYPEID(PN,Lerr) :-
(vcheck1(PN),
-> plf_v2_TYPEID(PN,Lerr)
; Lerr = ['failed vcheck1']).
plf_v2_TYPEID(PN,Lerr) :-
(vcheck2(PN),
-> plf_v3_TYPEID(PN,Lerr)
; Lerr = ['failed vcheck2']).
/* ... */
plf_vN_TYPEID(PN,Lerr) :-
(vcheckN(PN),
-> Lerr = []
; Lerr = ['failed vcheckN']).
/* sva_plf_TYPEID(+Lre, -LF, -PN, -Lerr) */
sva_plf_TYPEID(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_TYPEID(Lchars,LF,PN,Lerr)
; ( Lerr = ['aelist chars failed' | Lerr0]),
LF = [],
PN = 'unparsed' )
; ( Lerr = ['aelist_chars failed, no further info']),
LF = [],
PN = 'unparsed' ).
/* plf_wlv(+Lre,-LF,-PN,-Lerr):
* do whitespace, lex check, value check */
plf_wlv_TYPEID(Lchars,LF,PN,Lerr) :-
(ws_normalize(KEYWORD,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_TYPEID(LF,PN,Lerr)
; ( LF = [],
PN = 'unparsed,
Lerr = ['ws normalization failed' | Lerr0]))
; LF = [],
PN = 'unparsed',
Lerr = ['whitespace normalization failed (can this even HAPPEN?)']).
/* plf_lv(+LF, -Lerr): check lexical form (l), value (v) */
plf_lv_TYPEID(LF,Lerr) :-
(lexform_TYPEID(PN,LF,[])
-> (PN ^^ errors(E),
(Lerr0 = []
-> plf_v_TYPEID(PN,Lerr)
; Lerr = ['lex form parse failed' | Lerr0]))
; ( PN = 'unparsed',
Lerr = ['parse of lexical form failed, dunno why'] )).
/* plf_v(+PN, -Lerr): check value */
plf_v_TYPEID(PN,Lerr) :-
(vcheck1(PN,Lerr0),
-> (Lerr0 = []
-> plf_v2_TYPEID(PN,Lerr)
; Lerr = ['failed vcheck1' | Lerr0])
; Lerr = ['failed vcheck1']).
plf_v2_TYPEID(PN,Lerr) :-
(vcheck2(PN,Lerr0),
-> (Lerr0 = []
-> plf_v3_TYPEID(PN,Lerr)
; Lerr = ['failed vcheck2' | Lerr0])
; Lerr = ['failed vcheck2']).
/* ... */
plf_vN_TYPEID(PN,Lerr) :-
(vcheckN(PN,Lerr0),
-> (Lerr0 = []
-> Lerr = []
; Lerr = ['failed vcheckN' | Lerr0])
; Lerr = ['failed vcheckN']).
4.2.2. Error codes for simple types
- cvc-simple-type string not locally valid w.r.t. the given simple type. This should also have one or more error codes from cvc-datatype-valid in datatypes spec. These should be nested, not just later in the list — otherwise they look like independent errors, which they are not.
- cvc-datatype-valid.1 lexical form not datatype-valid w.r.t. a given simple type: does not match a literal in the lexical space.
- cvc-datatype-valid.2 lexical form not datatype-valid w.r.t. a given simple type: does not denote a member of the value space.
- L is not a legal lexical form for T,
because either
- L is not in the lexical space of the primitive simple type of T, or
- L does not match a pattern given in the derivation. In this case, it will be handy to specify which type in the hierarchy imposed the pattern.
- L is a legal lexical form for its primitive type (and matches all relevant patterns), but L denotes a primitive value which has been excluded from T.
- Code is the error code provided by the XML Schema specification or by our validator (for details not specifically addressed by the spec), e.g. “cvc-datatype-valid.2” or “pv_plf_ae.2”.
- Shortdesc is a short description intended primarily to make it easier, while reading the Prolog source code, to follow what's going on, e.g. “bad lexical form for type”. A quick and dirty user interface might expose this description to the user, but a good user interface is expected to use the Code and Info to produce suitable error messages for the user.
- Info is a list of simple label(value) structures which provide information which may make it easier to understand the cause of the error and which should be available to be integrated into the user-level error messages. Values may be atoms, but will in some cases be complex objects. In particular, by convention we will use the structure ce(Lerr) to provide a list of errors returned by a subordinate predicate (ce = ‘contributing errors’).
/* sva_plf_T(+Lre, -LF, -PN, -Lerr) */
sva_plf_TYPEID(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_TYPEID(Lchars, LF, PN, Lerr)
; ( Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(TYPEID), ce(Lerr0)])],
PN = 'unparsed',
LF = [])),
; ( Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(TYPEID), ce([])])],
PN = 'unparsed',
LF = [] )).
/* plf_wlv_T(+Lchars,-LF,-PN,-Lerr):
* do whitespace, lex check, value check */
plf_wlv_TYPEID(Lchars,LF,PN,Lerr) :-
(ws_normalize(KEYWORD,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_TYPEID(LF,PN,Lerr)
; ( Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(TYPEID), ce(Lerr0)])],
LF = [],
PN = 'unparsed' ))
; ( LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(TYPEID), ce([])])] )).
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_TYPEID(LF,PN,Lerr) :-
(lexform_TYPEID(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> plf_v_TYPEID(PN,Lerr)
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(TYPEID), lf(LF), ce(Lerr0)])]))
; PN = 'unparsed',
Lerr = ['cvc-datatype-valid.1',
'bad lexical form, grammar failed',
[type(TYPEID), ce([]), lf(LF)])]).
/* etc. */
sva_plf_TYPEID(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars)
-> (ws_normalize(Keyword,Lchars,LF)
-> (lexform_TYPEID(PN,LF,[])
-> (vcheck1(PN)
-> (vcheck2(PN)
-> (vcheckN(PN)
-> Lerr = []
; Lerr = ['failed vcheckN'])
; Lerr = ['failed vcheck2'])
; Lerr = ['failed vcheck1'])
; Lerr = ['bad lexical form'])
; LF = [],
Lerr = ['whitespace normalization failed (huh?!!)'])
; Lerr = ['aelist_chars failed']).
The astute reader reading this paragraph will correctly infer,
however, that despite the author's horror at the needless
obscurity of the pattern adopted in the code below, he has
not yet taken the time to replace it.
- t_xsd_string = xsd:string
- t_xsd_decimal = xsd:decimal
- t_xsd_date = xsd:date
- t_xsd_quantity = /complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(quantity) /simpleType()
- t_SKU = /simpleType(SKU)
4.2.3. Validating xsd:string
4.2.3.1. String itself
/* sva_plf_t_xsd_string(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_string(PLF,PLF,PN,Lerr) :-
(aelist_codes(PLF,Lcodes,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_string(Lcodes, PN, Lerr)
; ( Lerr = [error(pv_plf_ae1,'aelist_chars failed',
[type(t_xsd_string), ce(Lerr0)])],
PN = 'unparsed' ))
; ( Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_string), ce([])])],
PN = 'unparsed' )).
/* N.B. no whitespace normalization needed for string */
/* plf_lv_t_xsd_string(+LF,-PN,-Lerr):
* check lexical form (l), value (v) */
plf_lv_t_xsd_string(LF,PN,Lerr) :-
(lexform_t_xsd_string(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_string), lf(LF), ce(Lerr0)])]))
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed',
[type(t_xsd_string), ce([]), lf(LF)])]).
/* N.B. no value-level checks are defined for string */
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
4.2.3.2. Converting from Anjewierden/Wielemaker form to list of codes
/* aelist_codes(+List,-Codes,-Lerr): convert list of
* atoms and entity structures into list of integer codes,
* or else return errors.
*/
aelist_codes([],[],[]).
aelist_codes([Head|Tail],Codes,Lerr) :-
ae_unit(Head,CHead,Lerr1),
aelist_codes(Tail,CTail,Lerr2),
flatten([CHead,CTail],Codes),
append(Lerr1,Lerr2,Lerr).
aelist_codes(Atom,Codes,Lerr) :-
atom(Atom),
ae_unit(Atom,Codes,Lerr).
/* entities and special characters. These come first so that
* first-argument indexing will try them first when appropriate
* and skip them otherwise.
*/
ae_unit(entity(Code),Code,[]) :-
integer(Code).
/* N.B. for now, we do not support the use of named general
* entities in the Anjewierden/Wielemaker form. Maybe later.
*/
ae_unit(entity(Code),Code,
[error(pv_ae2,
'Entity names not supported, use numeric references',
[entity(Code)])]) :-
not(integer(Code)).
/* Main case: an atom, which we convert to a list of integers */
ae_unit(Head,CHead,Lerr) :-
atom(Head),
(atom_codes(Head,CHead)
-> Lerr = []
; Lerr = [error(pv_ae1,
'Unable to convert item into character',
[problem(Head)])],
CHead = []
).
/* Error case: not an atom, not an entity() structure */
ae_unit(Head,[],Error) :-
not(atom(Head)),
Head \= entity(_X),
Error = [error(pv_ae3,
'This is not an atom or an entity structure, what is it doing here?',
[problem(Head)])].
This code is used in < Generic predicates for simple types (PV) 166 >
<ok xsi:type="xsd:string">This is a sample string.</ok> <ok xsi:type="xsd:string">This is a sample string.</ok> <ok xsi:type="xsd:string">This is a sample string.</ok> <ok xsi:type="xsd:string">Voici une phrase française.</ok> <ok xsi:type="xsd:string">Voici une phrase française.</ok> <ok xsi:type="xsd:string">Voici une phrase française.</ok> <ok xsi:type="xsd:string"> The characters for single dagger (†), double dagger (‡), and per-mille (‰) are not in the basic Prolog character set.</ok>Continued in <Simple test cases for strings (PV) (cont'd) 105>, <Simple test cases for strings (cont'd) 107>
This code is used in < Test cases for simple types 167 >
<not_ok xsi:type="xsd:string">This is a sample string <emph>with embedded markup</emph>.</not_ok>
4.2.3.3. Lexical form of string
lexform_t_xsd_string ::= []
<:> errors([])
&& value([]).
lexform_t_xsd_string ::= [Code], lexform_t_xsd_string^^R,
{ ( not(integer(Code))
-> Lerr0 = [error(pv_string1,
'Non-integer code point found',
[code(Code)])]
; Code > 1114112
-> Lerr0 = [error(pv_string2,
'Code point too large',
[code(Code)])]
; Code < 0
-> Lerr0 = [error(pv_string3,
'Code point negative',
[code(Code)])]
; Code =:= 0
-> Lerr0 = [error(pv_string4,
'NUL character not legal in XML',
[])]
; Lerr0 = []
)
}
<:> errors(Lerr) ::-
R ^^ errors(Lerr1),
append(Lerr0,Lerr1, Lerr)
&& value(S) ::- R ^^ value(S0),
(Lerr0 = []
-> S = [Code | S0]
; S = S0)
.
This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
<ok xsi:type="xsd:string">The character � is legal.</ok> <ok xsi:type="xsd:string">Character  is legal.</ok> <not_ok xsi:type="xsd:string">Character x11FFFF (�) is not legal.</not_ok> <not_ok xsi:type="xsd:string">Character x0000 (�) is not legal.</not_ok> <ok xsi:type="xsd:string">Character x19 () is legal.</ok> <ok xsi:type="xsd:string">Character x1B () is legal.</ok> <ok xsi:type="xsd:string">Character x89 (‰) is legal.</ok> <ok xsi:type="xsd:string">Character x8B (‹) is legal.</ok>
4.2.4. Validating xsd:decimal
4.2.4.1. Decimal itself
/* sva_plf_t_xsd_decimal(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_decimal(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_xsd_decimal(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_xsd_decimal), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_decimal), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_xsd_decimal(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_decimal(LF,PN,Lerr)
; ( Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_xsd_decimal), ce(Lerr0)])],
PN = 'unparsed' ))
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_xsd_decimal), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_xsd_decimal(LF,PN,Lerr) :-
(lexform_t_xsd_decimal(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_decimal), lf(LF), ce(Lerr0)])]))
; ( Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed, reason unknown',
[type(t_xsd_decimal), ce([]), lf(LF)])],
PN = 'unparsed')).
/* N.B. no value checks for decimal: every legal lexical
* form denotes a legal value */
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
<ok xsi:type="xsd:decimal">0123456789</ok> <ok xsi:type="xsd:decimal">&longnumber;</ok> <not_ok xsi:type="xsd:decimal">This is a sample decimal <emph>with embedded markup</emph>.</not_ok> <!--* and another ... *--> <not_ok xsi:type="xsd:decimal">3<decimal_point/>141592.</not_ok>Continued in <More test cases for decimals 118>
This code is used in < Test cases for simple types 167 >
<!ENTITY tendigits "0123456789"> <!ENTITY forty "&tendigits;&tendigits;&tendigits;&tendigits;"> <!ENTITY longnumber "&forty;&forty;&forty;.&forty;&forty;">
This code is used in < Test cases for simple types 167 >
4.2.4.2. Converting from Anjewierden/Wielemaker form to characters
/* aelist_chars(+List,-Chars,-Lerr): convert list of
* atoms and entity structures into list of characters,
* using integers when the input character is not a legal
* Prolog character, or else return errors.
*/
aelist_chars([],[],[]).
aelist_chars([Head|Tail],Chars,Lerr) :-
ae_char(Head,CHead,Lerr1),
aelist_chars(Tail,CTail,Lerr2),
flatten([CHead,CTail],Chars),
append(Lerr1,Lerr2,Lerr).
aelist_chars(Atom,Lc,Lerr) :-
atom(Atom),
ae_char(Atom,Lc,Lerr).
ae_char(Head,CHead,Lerr) :-
atom(Head),
( atom_chars(Head,CHead)
-> Lerr = []
; Lerr = [error(pv_ae4,
'Unable to convert item into char sequence',
[problem(Head)])],
CHead = []
).
ae_char(entity(Code),Code,[]) :-
integer(Code).
/* N.B. for now, we do not support the use of named general
* entities in the Anjewierden/Wielemaker form. Maybe later.
*/
ae_char(entity(Code),Code,
[error(pv_ae5,
'Entity names not supported, use numeric references',
[entity(Code)])]) :-
not(integer(Code)).
ae_char(Head,[],Error) :-
not(atom(Head)),
not(integer(Head)),
Head \= entity(_X),
Error = [error(pv_ae6,
'This is not an atom or an entity structure, what is it doing here?',
[problem(Head)])].
This code is used in < Generic predicates for simple types (PV) 166 >
4.2.4.3. Lexical form of decimal
lexform_t_xsd_decimal ::= lexform_t_xsd_integer^^I, fractionalpart^^F
<:> lexval(LV) ::- I^^lexval(LVi),
F^^lexval(LVf),
append(LVi,LVf,LV)
&& value(V) ::- I^^value(Vi),
F^^value(Vf),
/* if sign is negative, subtract Vf,
* else add */
(I^^lexval(['-'|_])
-> V is Vi - Vf
; V is Vi + Vf)
&& errors(Lerr) ::- I^^errors(Lerr0),
F^^errors(Lerr1),
append(Lerr0,Lerr1,Lerr).
Continued in <Lexical form of integer (PV) 113>, <Grammar for fractional part of decimal (PV) 114>This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
lexform_t_xsd_integer ::= opt_sign^^S, digits^^D,
{ S ^^ lexval(Sign),
D ^^ lexval(LVd) }
<:> lexval([Sign | LVd])
&& value(V) ::- Sign = '+',
length(LVd, S0),
Scale is S0 - 1,
D^^value(Scale,V)
/* N.B. Scale is passed in as parameter to help
* determine value. */
&& value(Vn) ::- Sign = '-',
length(LVd, S0),
Scale is S0 - 1,
D^^value(Scale,V0),
Vn is 0 - V0
&& errors(Lerr) ::- S^^errors(Lerrs),
D^^errors(Lerrd),
append(Lerrs,Lerrd,Lerr).
fractionalpart ::= []
<:> value(0)
&& lexval([])
&& errors([]).
/* redundant, suppress this
fractionalpart ::= decimalpoint
<:> value(0)
&& errors([]).
*/
fractionalpart ::= decimalpoint^^P, opt_digits^^D,
{ P ^^ lexval(LVp), D ^^ lexval(LVd) }
<:> lexval([LVp | LVd])
&& value(V) ::- D ^^ value(-1,V)
/* N.B. Scale of -1 is passed in as parameter */
&& errors(Lerr) ::- P^^errors(Lerr1), D^^errors(Lerr2), append(Lerr1,Lerr2,Lerr).
Continued in <Grammar for sign and decimal point of decimal (PV) 115>, <Grammar for optional digits of decimal (PV) 116>, <Grammar for digits of decimal (PV) 117>This code is used in < Lexical form of decimal (2L) 379 >
opt_sign ::= []
<:> lexval('+')
&& errors([]).
opt_sign ::= ['+']
<:> lexval('+')
&& errors([]).
opt_sign ::= ['-']
<:> lexval('-')
&& errors([]).
decimalpoint ::= ['.']
<:> errors([])
&& lexval('.').
opt_digits ::= []
<:> lexval('')
&& value(_Scale,0)
&& errors([]).
opt_digits ::= digits^^D
<:> lexval(LV) ::- D^^lexval(LV)
&& value(Scale,V) ::- D^^value(Scale,V)
&& errors(Lerr) ::- D^^errors(Lerr).
digits ::= digit^^D
<:> lexval([Dv]) ::- D^^lexval(Dv)
&& value(Scale,V) ::- D^^value(Scale,V)
&& errors([]).
digits ::= digit^^D1, digits^^Dd
<:> lexval([D1val|Ddval]) ::-
D1^^lexval(D1val),
Dd^^lexval(Ddval)
&& value(Scale,V) ::- D1^^value(Scale,V1),
S2 is Scale - 1,
Dd^^value(S2,V2),
V is V1 + V2
&& errors(Lerr) ::-
D1^^errors(Lerr1),
Dd^^errors(Lerrd),
append(Lerr1,Lerrd,Lerr).
digit ::= [Ch], { char_type(Ch,digit) }
<:> lexval(Ch)
&& value(Scale,V) ::- atom_number(Ch,V0),
V is V0 * (10 ** Scale)
&& errors([]).
<ok xsi:type="xsd:decimal">3.141592</ok> <ok xsi:type="xsd:decimal"> 3.141592 </ok> <ok xsi:type="xsd:decimal"> 0.141592 </ok> <ok xsi:type="xsd:decimal"> 4. </ok> <ok xsi:type="xsd:decimal"> -4.2 </ok> <ok xsi:type="xsd:decimal"> +4.2 </ok> <not_ok xsi:type="xsd:decimal">3.14.1592</not_ok> <not_ok xsi:type="xsd:decimal"> 3.14.1592 </not_ok> <not_ok xsi:type="xsd:decimal"> --4.2 </not_ok> <not_ok xsi:type="xsd:decimal"> -+4.2 </not_ok> <not_ok xsi:type="xsd:decimal"> ++4.2 </not_ok> <not_ok xsi:type="xsd:decimal"> 3 . 141592 </not_ok> <not_ok xsi:type="xsd:decimal"> - 4.2 </not_ok> <not_ok xsi:type="xsd:decimal"> + 4.2 </not_ok> <not_ok xsi:type="xsd:decimal"> 4.2++ </not_ok>
4.2.5. White space normalization in the PV grammar
/* ws_normalize(Keyword,Input,Output): true if Output is * an atom identical to the whitespace-normalized form of * Input, with the whitespace mode indicated by Keyword. */ ws_normalize(preserve,List,List,[]).Continued in <Utility for whitespace normalization (PV) 120>, <Utility for whitespace normalization (PV) 122>
This code is used in < Generic predicates for simple types (PV) 166 >
ws_normalize(replace,In,Out,Lerr) :- ws_blanks(In,Out,Lerr).
/* ws_blanks(A,B): where A has any whitespace, B has a blank */ ws_blanks([],[],[]). ws_blanks(['\t'|T1],[' '|T2],Lerr) :- ws_blanks(T1,T2,Lerr). ws_blanks(['\n'|T1],[' '|T2],Lerr) :- ws_blanks(T1,T2,Lerr). ws_blanks(['\r'|T1],[' '|T2],Lerr) :- ws_blanks(T1,T2,Lerr). ws_blanks([H|T1],[H|T2],Lerr) :- not(member(H,['\t','\n','\r'])), ws_blanks(T1,T2,Lerr).
This code is used in < Generic predicates for simple types (PV) 166 >
ws_normalize(collapse,In,Out,Lerr) :- ws_normalize(replace,In,Temp,Lerr0), ws_collapse(Temp,Out,Lerr1), append(Lerr0,Lerr1,Lerr).
- initial state: no non-blank character has yet been seen. Blanks stay in this state (with no output signal), non-blanks go to the inword state (and emit the non-blank character as output).
- inword state: the most recent character is a non-blank, so we are in the middle of a character sequence to be preserved. Non-blank characters stay in this state (and copy the character to output); blanks go to the after-word state (with no output).
- afterword state: the most recent character is a blank. If there are non-blanks following it, we want to write it out again, but if we have hit some trailing whitespace we don't want any more output. Blanks stay in this state (with no output); non-blanks go back to the inword state (emitting a blank and then the non-blank that cause the transition).
/* ws_collapse(A,B): B is like A, with all strings of blanks * collapsed to single blanks, and leading and trailing * blanks stripped. */ /* ws_collapse/3 just calls ws_collapse/4 with the * appropriate state (initial). */ ws_collapse(L0,L,Lerr) :- ws_collapse(initial,L0,L,Lerr). ws_collapse(_State,[],[],[]). /* ws_collapse(initial, L0, L, Lerr) walks past initial * whitespace and then calls ws_collapse(inword, ...). */ ws_collapse(initial,[' '|T0],T,Lerr) :- ws_collapse(initial,T0,T,Lerr). ws_collapse(initial,[C|T0],[C|T],Lerr) :- C \= ' ', ws_collapse(inword,T0,T,Lerr). /* ws_collapse(inword, ...) accumulates non-blanks. * On blank we call ws_collapse(afterword, ...). */ ws_collapse(inword,[' '|T0],T,Lerr) :- ws_collapse(afterword,T0,T,Lerr). ws_collapse(inword,[C|T0],[C|T],Lerr) :- C \= ' ', ws_collapse(inword,T0,T,Lerr). /* ws_collapse(afterword, ...) skips blanks, and * if we see a non-blank we emit a blank and the non-blank, * then call ws_collapse(inword, ...). */ ws_collapse(afterword,[' '|T0],T,Lerr) :- ws_collapse(afterword,T0,T,Lerr). ws_collapse(afterword,[C|T0],[' ',C|T],Lerr) :- C \= ' ', ws_collapse(inword,T0,T,Lerr).
This code is used in < Generic predicates for simple types (PV) 166 >
4.2.6. Validating xsd:date
/* sva_plf_t_xsd_date(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_date(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_xsd_date(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_xsd_date), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_date), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_xsd_date(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_date(LF,PN,Lerr)
; ( Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_xsd_date), ce(Lerr0)])],
PN = 'unparsed' ))
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_xsd_date), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_xsd_date(LF,PN,Lerr) :-
(lexform_t_xsd_date(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> plf_v_t_xsd_date(PN,Lerr)
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_date), lf(LF), ce(Lerr0)])]))
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed, reason unknown',
[type(t_xsd_date), ce([]), lf(LF)])]).
/* plf_v: check value */
plf_v_t_xsd_date(PN,Lerr) :-
(date_ok(PN,Lerr0)
-> (Lerr0 = []
-> Lerr = []
; Lerr = [error(code,'date value not OK',[ce(Lerr0)])])
; Lerr = [error(code,'date value not OK (date_ok failed)',[])]).
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
lexform_t_xsd_date ::= year^^Y, hyphen, month^^M, hyphen, day^^D
<:> errors(Lerr) ::-
Y^^errors(Lerr1),
M^^errors(Lerr2),
D^^errors(Lerr3),
flatten([Lerr1,Lerr2,Lerr3],Lerr)
&& year(YV) ::- Y^^value(YV)
&& month(MV) ::- M^^value(MV)
&& day(DV) ::- D^^value(DV)
{Calculating a date value (PV) 133}
.
Continued in <Lexical form for year (PV) 128>This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
<ok xsi:type="xsd:date">1998-02-08</ok> <ok xsi:type="xsd:date"> 1998-02-08 </ok> <ok xsi:type="xsd:date">231998-02-08</ok> <ok xsi:type="xsd:date">0027-02-08</ok> <not_ok xsi:type="xsd:date">19980208</not_ok> <not_ok xsi:type="xsd:date">1998-02</not_ok> <not_ok xsi:type="xsd:date">1998--02--08</not_ok> <not_ok xsi:type="xsd:date">1998-002-008</not_ok> <not_ok xsi:type="xsd:date">3.141592</not_ok>Continued in <Some test cases for dates (four or more year-digits) 129>, <Some test cases for dates (ranges on month, day) 132>, <Some test cases for dates (leap-year calculations) 137>
This code is used in < Test cases for simple types 167 >
/* Years must have at least four digits */
yearnum ::= digit^^D1, digit^^D2, digit^^D3, digits^^Dd
<:> value(Num) ::- D1^^lexval(Dv1),
D2^^lexval(Dv2),
D3^^lexval(Dv3),
Dd^^lexval(Dv4),
flatten([Dv1,Dv2,Dv3,Dv4],LF),
number_chars(Num,LF)
&& errors([]).
year ::= yearnum^^Y
<:> value(Num) ::- Y^^value(Num)
&& errors(Lerr) ::- Y^^errors(Lerr).
year ::= ['-'], yearnum^^Y
<:> value(Num) ::- Y^^value(N), Num is 0 - N
&& errors(Lerr) ::- Y^^errors(Lerr).
hyphen ::= ['-'].
Continued in <Lexical form for month (PV) 130>, <Lexical form for day of month (PV) 131>This code is used in < Lexical form for dates (2L) 381 >
<ok xsi:type="xsd:date">-1998-02-08</ok> <ok xsi:type="xsd:date">-0047-03-13</ok> <not_ok xsi:type="xsd:date">27-02-08</not_ok> <not_ok xsi:type="xsd:date">-047-03-13</not_ok>
month ::= digit^^D1, digit^^D2,
{ D1^^lexval(Dv1),
D2^^lexval(Dv2),
number_chars(Num,[Dv1,Dv2]) }
<:> value(Num)
&& errors([]) ::-
Num > 0,
Num < 13
&& errors([error(pv_lf_date_1,'Month must be at least 01',
[lf([Dv1,Dv2]), num(Num)])]) ::-
Num =< 0
&& errors([error(pv_lf_date_2,'Month must be at most 12',
[lf([Dv1,Dv2]), num(Num)])]) ::-
Num > 12.
day ::= digit^^D1, digit^^D2,
{ D1^^lexval(Dv1),
D2^^lexval(Dv2),
number_chars(Num,[Dv1,Dv2]) }
<:> value(Num)
&& errors([]) ::-
Num > 0,
Num < 32
&& errors([error(pv_lf_date_3,'Day of month must be at least 01',
[lf([Dv1,Dv2]), num(Num)])]) ::-
Num =< 0
&& errors([error(pv_lf_date_4,'Day of month must be at most 31',
[lf([Dv1,Dv2]), num(Num)])]) ::-
Num > 31.
<ok xsi:type="xsd:date">1998-01-08</ok> <ok xsi:type="xsd:date">1998-12-08</ok> <ok xsi:type="xsd:date">1998-01-01</ok> <ok xsi:type="xsd:date">1998-12-31</ok> <not_ok xsi:type="xsd:date">1998-00-08</not_ok> <not_ok xsi:type="xsd:date">1998-22-08</not_ok> <not_ok xsi:type="xsd:date">1998-12-00</not_ok> <not_ok xsi:type="xsd:date">1998-12-32</not_ok>
&& value(V) ::-
Y^^value(Y0),
M^^value(M0),
D^^value(D0),
(M0 < 3
-> Y1 is Y0 - 1
; Y1 is Y0),
M1 is (M0 + 9) mod 12,
(Y1 >= 0
-> C is Y1 // 100,
Y2 is Y1 mod 100
; C is Y1 // 100,
Y2 is Y1 - (C * 100)),
V is ((C * 146097) // 4)
+ ((Y2 * 1461) // 4)
+ (((M1 * 153) + 2) // 5)
+ D0
+ 1721119
This code is used in < Lexical form for dates (PV) 126 > < Lexical form for dates (2L) 381 >
- A year is 365 days, 366 in leap years.
- Four years (except century years) have 3 × 365 + 1 × 366 = 4 × 365 + 1 = 1461 days.
- Four centuries have 400 years and (3 × 24 + 1 × 25) = (4 × 24 + 1) leap years.
- 400 years thus = 400 × 365 + 4 × 24 + 1 = 146097 days.
- C centuries thus have ((146097 × C) div 4) days.
- Y years since a century have ((1461 × Y) div 4) days.
- M months since March 1 have (((153 × M) + 2) div 5) days.
- D days since the beginning of the month have D days.
date_ok(PN, []) :- PN^^day(D), D < 29. date_ok(PN, []) :- PN^^day(29), PN^^month(M), M =\= 2. date_ok(PN, []) :- PN^^day(30), PN^^month(M), M =\= 2. date_ok(PN, []) :- PN^^day(31), PN^^month(M), member(M,[1,3,5,7,8,10,12]). date_ok(PN, []) :- PN^^day(29), PN^^month(2), PN^^year(Y), (Y >= 0 -> Yx = Y ; Yx is Y + 1), /* adjust for BC */ 0 is Yx mod 4, Lc is Yx mod 100, L4c is Yx mod 400, leapyearcheck(Lc,L4c).Continued in <Checking date values (PV) 135>, <Checking date values (PV) 136>
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 > < Grammar rules for lexical forms of built-in types (2L) 374 >
date_ok(PN, [error(pv_v_date_1,
'February does not have a 30th day this or any year',
[year(Y), month(2), day(30)])]) :-
PN^^day(30),
PN^^month(2),
PN^^year(Y).
date_ok(PN, [error(pv_v_date_2,
'This month has no 31st day',
[year(Y), month(M), day(31)])]) :-
PN^^day(31),
PN^^month(M),
PN^^year(Y),
not(member(M,[1,3,5,7,8,10,12])).
date_ok(PN, [error(pv_v_date_3,
'February does not have a 29th day this year',
[year(Y)])]) :-
PN^^day(29),
PN^^month(2),
PN^^year(Y),
(Y >= 0 -> Yx = Y ; Yx is Y + 1), /* adjust for BC */
0 is Yx mod 4,
Lc is Yx mod 100,
L4c is Yx mod 400,
not(leapyearcheck(Lc,L4c)).
/* if C is nonzero, it's not a century year, * so it's a leapyear */ leapyearcheck(C,_Q) :- C =\= 0. /* If both numbers are 0, it's a quad-century year, * so it's a leapyear */ leapyearcheck(0,0).
<ok xsi:type="xsd:date">1066-06-30</ok> <not_ok xsi:type="xsd:date">1066-06-31</not_ok> <not_ok xsi:type="xsd:date">1066-02-29</not_ok> <not_ok xsi:type="xsd:date">1066-02-31</not_ok> <ok xsi:type="xsd:date">1068-02-29</ok> <ok xsi:type="xsd:date">1200-02-29</ok> <ok xsi:type="xsd:date">2000-02-29</ok> <ok xsi:type="xsd:date">4000-02-29</ok> <not_ok xsi:type="xsd:date">1000-02-29</not_ok>
4.2.7. Validating po:quantity
/* sva_plf_t_e_quantity_t_e_item_t_Items(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_e_quantity_t_e_item_t_Items(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_e_quantity_t_e_item_t_Items(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_e_quantity_t_e_item_t_Items), ce(Lerr0)])],
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_e_quantity_t_e_item_t_Items), ce([])])],
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_e_quantity_t_e_item_t_Items(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_e_quantity_t_e_item_t_Items(LF,PN,Lerr)
; Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_e_quantity_t_e_item_t_Items), ce(Lerr0)])])
; LF = [],
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_e_quantity_t_e_item_t_Items), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_e_quantity_t_e_item_t_Items(LF,PN,Lerr) :-
(lexform_t_e_quantity_t_e_item_t_Items(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> plf_minInclusive_t_e_quantity_t_e_item_t_Items(PN,Lerr)
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_e_quantity_t_e_item_t_Items), lf(LF), ce(Lerr0)])]))
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed',
[type(t_e_quantity_t_e_item_t_Items), ce([]), lf(LF)])]).
This code is used in < Checking (pre-) lexical forms against schema-specific types (PV) 165 >
/* plf_minInclusive: check value against lower bound */
plf_minInclusive_t_e_quantity_t_e_item_t_Items(PN,Lerr) :-
PN ^^ value(V),
(V >= 1
-> plf_maxExclusive_t_e_quantity_t_e_item_t_Items(PN,Lerr)
; Lerr = [error('cvc-minInclusive-valid',
'Value too small',
[minInclusive(1), value(V), type(t_e_quantity_t_e_item_t_Items)])]).
plf_maxExclusive_t_e_quantity_t_e_item_t_Items(PN,Lerr) :-
PN ^^ value(V),
(V < 100
-> Lerr = []
; Lerr = [error('cvc-maxExclusive-valid',
'Value too large',
[maxExclusive(100), value(V), type(t_e_quantity_t_e_item_t_Items)])]).
This code is used in < Checking (pre-) lexical forms against schema-specific types (PV) 165 >
lexform_t_e_quantity_t_e_item_t_Items ::= opt_plussign^^S, digits^^D,
{ S ^^ lexval(Sign),
D ^^ lexval(LVd) }
<:> lexval([Sign | LVd])
&& value(V) ::- Sign = '+',
length(LVd, S0),
Scale is S0 - 1,
D^^value(Scale,V)
/* N.B. Scale is passed in as parameter to help
* determine value. */
&& errors(Lerr) ::- S^^errors(Es),
D^^errors(Ed),
append(Es,Ed,Lerr).
opt_plussign ::= []
<:> lexval('+')
&& errors([]).
opt_plussign ::= ['+']
<:> lexval('+')
&& errors([]).
This code is used in < Checking (pre-) lexical forms against schema-specific types (PV) 165 >
<ok xsi:type="po:quantity"> 1 </ok> <ok xsi:type="po:quantity"> 99 </ok> <ok xsi:type="po:quantity"> 00099 </ok> <not_ok xsi:type="po:quantity"> 00 </not_ok> <not_ok xsi:type="po:quantity"> 100 </not_ok> <not_ok xsi:type="po:quantity"> 1.0 </not_ok> <not_ok xsi:type="po:quantity"> 99.00 </not_ok>
This code is used in < Test cases for simple types 167 >
4.2.8. Validating po:SKU
/* sva_plf_t_SKU(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_SKU(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_SKU(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_SKU), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_SKU), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_SKU(Lchars,LF,PN,Lerr) :-
(ws_normalize(preserve,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_SKU(LF,PN,Lerr)
; Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_SKU), ce(Lerr0)])])
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_SKU), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_SKU(LF,PN,Lerr) :-
(lexform_t_SKU(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_SKU), lf(LF), ce(Lerr0)])]))
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed',
[type(t_SKU), ce([]), lf(LF)])]).
This code is used in < Checking (pre-) lexical forms against schema-specific types (PV) 165 >
lexform_t_SKU ::= sku_decimal_part^^D, hyphen, sku_alpha_part^^A
<:> errors(Lerr) ::-
D^^errors(LerrD),
A^^errors(LerrA),
append(LerrD,LerrA,Lerr)
&& lexval(LV) ::-
D^^lexval(LVD),
A^^lexval(LVA),
flatten([LVD,['-'],LVA],LV)
&& value(V) ::-
D^^lexval(LVD),
A^^lexval(LVA),
flatten([LVD,['-'],LVA],V).
/* Having both 'value' and 'lexval' looks rather dumb
* for strings */
sku_decimal_part ::= digit^^D1, digit^^D2, digit^^D3
<:> errors(Lerr) ::-
D1^^errors(Lerr1),
D2^^errors(Lerr2),
D3^^errors(Lerr3),
flatten([Lerr1,Lerr2,Lerr3],Lerr)
&& lexval([LV1,LV2,LV3]) ::-
D1^^lexval(LV1),
D2^^lexval(LV2),
D3^^lexval(LV3).
sku_alpha_part ::= cap_a_z^^L1, cap_a_z^^L2
<:> errors(Lerr) ::-
L1^^errors(Lerr1),
L2^^errors(Lerr2),
append(Lerr1,Lerr2,Lerr)
&& lexval([LV1,LV2]) ::-
L1^^lexval(LV1),
L2^^lexval(LV2).
/* Since the ISO Prolog character set is ISO Latin 1,
* it's not enough to call char_type(Char,upper),
* we also need to check that the character is in the ASCII
* range to make sure it's in the range [A-Z]. */
cap_a_z ::= [Char],
{ char_type(Char,upper),
char_type(Char,ascii) }
<:> errors([])
&& lexval(Char).
This code is used in < Checking (pre-) lexical forms against schema-specific types (PV) 165 >
<ok xsi:type="po:SKU">123-AB</ok> <ok xsi:type="po:SKU">000-AA</ok> <ok xsi:type="po:SKU">999-ZA</ok> <ok xsi:type="po:SKU"> 999-ZA </ok> <not_ok xsi:type="po:SKU">123-ab</not_ok> <not_ok xsi:type="po:SKU">000-aa</not_ok> <not_ok xsi:type="po:SKU">999-ÄU</not_ok> <not_ok xsi:type="po:SKU">99-9A-U</not_ok> <not_ok xsi:type="po:SKU">9990-AAA</not_ok> <not_ok xsi:type="po:SKU">1066-06-30</not_ok> <not_ok xsi:type="po:SKU">3.14159</not_ok>
This code is used in < Test cases for simple types 167 >
4.2.9. Validating QNames
/* sva_plf_t_xsd_QName(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_QName(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_xsd_QName(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_xsd_QName), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_QName), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_xsd_QName(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_QName(LF,PN,Lerr)
; PN = 'unparsed',
Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_xsd_QName), ce(Lerr0)])])
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_xsd_QName), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_xsd_QName(LF,PN,Lerr) :-
(lexform_t_xsd_QName(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_QName), lf(LF), ce(Lerr0)])]))
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed, reason unknown',
[type(t_xsd_QName), ce([]), lf(LF)])]).
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
/* do an eager match first: use the colon if it's there */
lexform_t_xsd_QName ::= lexform_t_xsd_NCName^^P, colon, lexform_t_xsd_NCName^^L
<:> errors(Lerr) ::-
P^^errors(Lerr1),
L^^errors(Lerr2),
flatten([Lerr1,Lerr2],Lerr)
&& prefix(Prefix) ::- P^^value(LcPrefix), atom_chars(Prefix,LcPrefix)
&& local_name(LName) ::- L^^value(LcLName), atom_chars(LName,LcLName)
.
/* if there is no colon, fall back to this. */
lexform_t_xsd_QName ::= lexform_t_xsd_NCName^^L
<:> errors(Lerr) ::-
L^^errors(Lerr)
&& prefix('')
&& local_name(LName) ::- L^^value(LName)
.
lexform_t_xsd_NCName ::= namestart_char^^C, other_name_chars^^Tail
<:> value(V) ::- C^^value(Vc),
Tail^^value(Vt),
append(Vc,Vt,V)
&& errors([])
.
colon ::= [':'].
namestart_char ::= [Char], { namestart_char(Char) }
<:> value([Char]).
name_char ::= [Char], { name_char(Char) }
<:> value([Char]).
other_name_chars ::= name_char^^C, other_name_chars^^Tail
<:> value(V) ::- C^^value(Vc),
Tail^^value(Vt),
append(Vc,Vt,V)
.
other_name_chars ::= []
<:> value([]).
/* Eventually, we'll do the right thing by Unicode. For now,
* a quick approximation for those who really only use ASCII
* anyway. */
/*
namestart_char(Char) :-
( char_type(Char,csymf)
; Char = '.'
; Char = '-' ).
name_char(Char) :-
( char_type(Char,csym)
; Char = '.'
; Char = '-' ).
*/
namestart_char('.').
namestart_char('-').
namestart_char(Char) :- char_type(Char,csymf).
name_char('.').
name_char('-').
name_char(C) :- integer(C), C < 256, char_type(C,csym).
name_char(Char) :- not(integer(Char)), char_type(Char,csym).
This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
<ok xsi:type="xsd:QName">abracadabra</ok> <ok xsi:type="xsd:QName"> xsd:date </ok> <ok xsi:type="xsd:QName">my_ns:my_element</ok> <not_ok xsi:type="xsd:QName">swizzle stick</not_ok> <not_ok xsi:type="xsd:QName">swizzle^stick</not_ok> <not_ok xsi:type="xsd:QName">hotstuff!</not_ok> <not_ok xsi:type="xsd:QName">name@address</not_ok> <not_ok xsi:type="xsd:QName"><name.address></not_ok> <not_ok xsi:type="xsd:QName">a:b:c</not_ok>
This code is used in < Test cases for simple types 167 >
QName_Lnsb_ok(ParsedNode, Lnsb, []) :-
ParsedNode^^prefix(P),
member(ns(P,_NS),Lnsb).
QName_Lnsb_ok(ParsedNode, Lnsb,
[error('qname-1','QName prefix has no binding',
[prefix(P),local(L)])]) :-
ParsedNode^^prefix(P),
ParsedNode^^local_name(P),
not(member(ns(P,_NS),Lnsb)).
This code is not used elsewhere.
4.2.10. Validating xsd:NMTOKEN
[7] Nmtoken ::= (NameChar)+
[4] NameChar ::= Letter | Digit | '.' | '-' | '_' | ':' |
CombiningChar | Extender
As with QName, we will not provide full Unicode support in this
version of the schema, but take a shortcut and just accept
ASCII name characters.
/* sva_plf_t_xsd_NMTOKEN(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_NMTOKEN(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_xsd_NMTOKEN(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_xsd_NMTOKEN), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_NMTOKEN), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_xsd_NMTOKEN(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_NMTOKEN(LF,PN,Lerr)
; ( Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_xsd_NMTOKEN), ce(Lerr0)])],
PN = 'unparsed' ))
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_xsd_NMTOKEN), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_xsd_NMTOKEN(LF,PN,Lerr) :-
(lexform_t_xsd_NMTOKEN(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_NMTOKEN), lf(LF), ce(Lerr0)])]))
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed, reason unknown',
[type(t_xsd_NMTOKEN), ce([]), lf(LF)])]).
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
lexform_t_xsd_NMTOKEN ::= name_char^^C, other_name_chars^^Tail
<:> value(V) ::- C^^value(Vc),
Tail^^value(Vt),
append(Vc,Vt,V)
&& errors([])
.
This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
<ok xsi:type="xsd:NMTOKEN">XML</ok> <ok xsi:type="xsd:NMTOKEN">X.M.L.</ok> <ok xsi:type="xsd:NMTOKEN">...</ok> <ok xsi:type="xsd:NMTOKEN"> XML </ok> <not_ok xsi:type="xsd:NMTOKEN">illegal_�_illegal</not_ok> <not_ok xsi:type="xsd:NMTOKEN">illegal internal blanks</not_ok> <ok xsi:type="xsd:NMTOKEN">abc.123-456.xyz</ok> <ok xsi:type="xsd:NMTOKEN">123.abc-xyz.456</ok> <ok xsi:type="xsd:NMTOKEN">123-----456</ok>
This code is used in < Test cases for simple types 167 >
4.2.11. Validating list of anyURI
/* sva_plf_t_xsd_anyURI(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_anyURI(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_xsd_anyURI(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_xsd_anyURI), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_anyURI), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_xsd_anyURI(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_anyURI(LF,PN,Lerr)
; ( Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_xsd_anyURI), ce(Lerr0)])],
PN = 'unparsed' ))
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_xsd_anyURI), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_xsd_anyURI(LF,_PN,Lerr) :-
(lexform_t_xsd_anyURI(LF,Lerr0)
-> (Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_anyURI), lf(LF), ce(Lerr0)])])
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed, reason unknown',
[type(t_xsd_anyURI), ce([]), lf(LF)])]).
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
concat_atom(Split,'#',URI), length(Split,Len), Len < 3The built-in concat_atom predicate, called in mode (-++), parses the atom passed as third argument, splitting on the delimiter (second argument), and returns in the first argument the list of tokens thus created. If there is no hash mark, it returns a singleton list containing the original atom; if there is one hash, the list has two parts (if the hash is the last character, the second atom in that list is ''); if there are two hashes, you get three parts. And so on. The only complication is that the pre-lexical form will be passed to us as a list which may contain just a single atom (the simple case) or may contain several (in case there are entity structures).
lexform_t_xsd_anyURI(LF,Lerr) :-
concat_atom(LF,URI),
concat_atom(Split1,'#',URI),
concat_atom(Split2,' ',URI),
length(Split1,Len1),
length(Split2,Len2),
( Len1 > 2
-> Lerr = [error('pv-anyURI-hash','Too many hash marks',
[lf(LF), test_atom(URI), hashcount_plus_one(Len1)])]
; ( Len2 > 1
-> Lerr = [error('pv-anyURI-hash','Too many tokens',
[lf(LF), test_atom(URI), token_count(Len2)])]
; Lerr = [] ) ).
This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
<ok xsi:type="xsd:anyURI">http://www.w3.org/2001/XMLSchema</ok> <ok xsi:type="xsd:anyURI">//www.w3.org/2001/XMLSchema</ok> <ok xsi:type="xsd:anyURI">/2001/XMLSchema</ok> <ok xsi:type="xsd:anyURI">../../2001/XMLSchema</ok> <ok xsi:type="xsd:anyURI">XMLSchema</ok> <ok xsi:type="xsd:anyURI"> http://www.w3.org/2001/XMLSchema </ok> <not_ok xsi:type="xsd:anyURI"> http://example.org/this is an unusual URI if indeed it is a URI </not_ok> <not_ok xsi:type="xsd:anyURI">http://example.org/an unusual URI #many_happy_returns</not_ok> <ok xsi:type="xsd:anyURI">http://example.org/xyz#abc</ok> <not_ok xsi:type="xsd:anyURI">http://example.org/xyz#abc#def</not_ok> <not_ok xsi:type="xsd:anyURI">http://example.org/xyz#abc#</not_ok> <not_ok xsi:type="xsd:anyURI">http://example.org/xyz##def</not_ok> <ok xsi:type="xsd:anyURI">#xyz</ok> <not_ok xsi:type="xsd:anyURI">##abc##</not_ok> <not_ok xsi:type="xsd:anyURI">##abc</not_ok> <not_ok xsi:type="xsd:anyURI">##</not_ok> <ok xsi:type="xsd:anyURI">#</ok>
This code is used in < Test cases for simple types 167 >
/* sva_plf_t_xsd_list_anyURI(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_list_anyURI(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_xsd_list_anyURI(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_xsd_list_anyURI), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_list_anyURI), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_xsd_list_anyURI(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_list_anyURI(LF,PN,Lerr)
; ( Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_xsd_list_anyURI), ce(Lerr0)])],
PN = 'unparsed' ))
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_xsd_list_anyURI), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_xsd_list_anyURI(LF,_PN,Lerr) :-
(lexform_t_xsd_list_anyURI(LF,Lerr0)
-> (Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_list_anyURI), lf(LF), ce(Lerr0)])])
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed, reason unknown',
[type(t_xsd_list_anyURI), ce([]), lf(LF)])]).
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
lexform_t_xsd_list_anyURI(LF,Lerr) :- tokenize(LF,LTokens,Lerr0), sva_urilist(LTokens,Lerr1), append(Lerr0,Lerr1,Lerr). /* tokenize: split charlist on whitespace */ /* tokenize(LcIn, LLcResult, Lerr): true iff * tokenizing LcIn on blanks results in the list of * lists LLcResult, with errors Lerr. */ /* Start with an empty current-token list and recur */ tokenize([],[],[]). tokenize([C|LcIn],[Token|LTokens],Lerr) :- first_token([C|LcIn],Token,LcRest), tokenize(LcRest,LTokens,Lerr). /* first_token(Lc, Tok, Rest): true iff * flatten([Tok, [' '] Rest], Lc), i.e. * Lc is the concatenation of Tok (a character list without blanks), * a blank, and Rest (a character list). */ first_token(List,Token,Rest) :- first_token(List, [], Token, Rest). /* first_token(Lc, Curtok, Tok, Rest): true iff * Curtok is the prefix of some half-read token Tok, * Lc contains the rest of Tok, a blank, and then Rest. */ /* If the input list is empty, take whatever token you have * got so far. Avoid calling first_token with first two * arguments both empty, or else you'll get empty tokens. */ first_token([], CurToken, Token, []) :- reverse(CurToken,Token). /* skip leading blanks if the current token is empty, * to avoid returning an empty list as a token. */ first_token([' '|Rest0], [], Token, Rest) :- first_token(Rest0, [], Token, Rest). /* If the current token is not empty, return it as soon as * you see a blank. Reverse it first, to correct for the * way we stacked the characters as we read them. */ first_token([' '|Rest], CurToken, Token, Rest) :- CurToken \= [], reverse(CurToken,Token). /* If the current character is not a blank, stack it * onto the current token and recur. Note that stacking * on the front this way requires reversing the token later. */ first_token([Char|Rest0], CurToken, Token, Rest) :- Char \= ' ', first_token(Rest0,[Char|CurToken], Token, Rest). sva_urilist([],[]). sva_urilist([URI|Luris],Lerr) :- lexform_t_xsd_anyURI(URI,Lerr0), sva_urilist(Luris,Lerr1), append(Lerr0,Lerr1,Lerr).
This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
<ok xsi:type="xsd:list_anyURI">http://www.w3.org/2001/XMLSchema ./foo bar</ok> <ok xsi:type="xsd:list_anyURI">#foo //www.w3.org/2001/XMLSchema</ok> <ok xsi:type="xsd:list_anyURI">/2001/XMLSchema #bar #baz</ok> <ok xsi:type="xsd:list_anyURI"> ../../2001/XMLSchema foo#bar</ok> <ok xsi:type="xsd:list_anyURI">XMLSchema</ok> <ok xsi:type="xsd:list_anyURI"> http://www.w3.org/2001/XMLSchema </ok> <ok xsi:type="xsd:list_anyURI"> http://example.org/this is an unusual URI if indeed it is a URI </ok> <not_ok xsi:type="xsd:list_anyURI">http://example.org/##an unusual URI #many_happy_returns</not_ok> <ok xsi:type="xsd:list_anyURI">http://example.org/xyz#abc x y z a b c d e f g h i j k l m n o p</ok> <not_ok xsi:type="xsd:list_anyURI">jklm http://example.org/xyz#abc#def</not_ok> <not_ok xsi:type="xsd:list_anyURI">http://example.org/xyz#abc#</not_ok> <not_ok xsi:type="xsd:list_anyURI">http://example.org/xyz##def</not_ok> <ok xsi:type="xsd:list_anyURI">#xyz</ok> <not_ok xsi:type="xsd:list_anyURI">#ok ##abc##</not_ok> <not_ok xsi:type="xsd:list_anyURI">##abc</not_ok> <not_ok xsi:type="xsd:list_anyURI">##</not_ok> <ok xsi:type="xsd:list_anyURI">#</ok>
This code is used in < Test cases for simple types 167 >
4.2.12. Validating xsd:boolean
/* sva_plf_t_xsd_boolean(+PLF,-LF,-PN,-Lerr) */
sva_plf_t_xsd_boolean(PLF,LF,PN,Lerr) :-
(aelist_chars(PLF,Lchars,Lerr0)
-> (Lerr0 = []
-> plf_wlv_t_xsd_boolean(Lchars, LF, PN, Lerr)
; Lerr = [error(pv_plf_ae1,'aelist_chars raised error',
[type(t_xsd_boolean), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
; Lerr = [error(pv_plf_ae2,'aelist_chars failed',
[type(t_xsd_boolean), ce([])])],
PN = 'unparsed',
LF = []).
/* plf_wlv: do whitespace, lex check, value check */
/* plf_wlv(+Lchars,-LF,-PN,-Lerrors):
* do whitespace, lex check, value check */
plf_wlv_t_xsd_boolean(Lchars,LF,PN,Lerr) :-
(ws_normalize(collapse,Lchars,LF,Lerr0)
-> (Lerr0 = []
-> plf_lv_t_xsd_boolean(LF,PN,Lerr)
; ( Lerr = [error(pv_plf_ws1,'ws normalization raised error',
[type(t_xsd_boolean), ce(Lerr0)])],
PN = 'unparsed' ))
; LF = [],
PN = 'unparsed',
Lerr = [error(pv_plf_ws2,
'ws normalization failed (can this happen?)',
[type(t_xsd_boolean), ce([])])]).
/* plf_lv: check lexical form (l), value (v) */
/* plf_lv_T(+LF, -PN, -Lerr): check lexical form (l), value (v) */
plf_lv_t_xsd_boolean(LF,PN,Lerr) :-
(lexform_t_xsd_boolean(PN,LF,[])
-> (PN ^^ errors(Lerr0),
(Lerr0 = []
-> Lerr = []
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form',
[type(t_xsd_boolean), lf(LF), ce(Lerr0)])]))
; Lerr = [error('cvc-datatype-valid.1',
'bad lexical form, grammar failed, reason unknown',
[type(t_xsd_boolean), ce([]), lf(LF)])]).
This code is used in < Checking pre-lexical forms against built-in types (PV) 163 >
lexform_t_xsd_boolean ::= bool_true <:> errors([]). lexform_t_xsd_boolean ::= bool_false <:> errors([]). bool_true ::= ['1']. bool_true ::= [t], [r], [u], [e]. bool_false ::= ['0']. bool_false ::= [f], [a], [l], [s], [e].
This code is used in < Grammar rules for lexical forms of built-in types (PV) 164 >
<ok xsi:type="xsd:boolean"> 0 </ok> <ok xsi:type="xsd:boolean"> 1 </ok> <ok xsi:type="xsd:boolean"> true </ok> <ok xsi:type="xsd:boolean"> false </ok> <not_ok xsi:type="xsd:boolean">01</not_ok> <not_ok xsi:type="xsd:boolean">10</not_ok> <not_ok xsi:type="xsd:boolean">0000</not_ok> <not_ok xsi:type="xsd:boolean">maybe</not_ok>
This code is used in < Test cases for simple types 167 >
4.2.13. Content rules for simple types
sva_content_t_xsd_string([PLF],[PLF],Lerr) :- sva_plf_t_xsd_string(PLF,_LF,_PN,Lerr). sva_content_t_xsd_decimal([PLF],[PLF],Lerr) :- sva_plf_t_xsd_decimal(PLF,_LF,_PN,Lerr). /* sva_content_t_xsd_integer([PLF],[PLF],Lerr) :- sva_plf_t_xsd_integer(PLF,_LF,_PN,Lerr). */ sva_content_t_xsd_date([PLF],[PLF],Lerr) :- sva_plf_t_xsd_date(PLF,_LF,_PN,Lerr).
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
sva_content_t_SKU([PLF],LF,Lerr) :- sva_plf_t_SKU(PLF,LF,_PN,Lerr). sva_content_t_e_quantity_t_e_item_t_Items([PLF],LF,Lerr) :- sva_plf_t_e_quantity_t_e_item_t_Items(PLF,LF,_PN,Lerr).
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
4.2.14. Summary of simple-type validation rules
/* Rules for checking pre-lexical forms against
* built-in types: perform whitespace normalization,
* validate lexical form. */
{Checking a pre-lexical form as a string (PV) 102}
{Pre-lexical form checking for NMTOKENs (PV) 149}
{Pre-lexical form checking for anyURI (PV) 152}
{Pre-lexical form checking for list of anyURI (PV) 155}
{Checking pre-lexical form as xsd_decimal (PV) 108}
{Pre-lexical form checking for QNames (PV) 145}
{Pre-lexical form checking for dates (PV) 125}
{Pre-lexical form checking for boolean (PV) 158}
/* Rules for checking values of built-in types. */
/* No value-level checks for string ... */
/* No value-level checks for NMTOKEN ... */
/* No value-level checks for decimal ... */
{Checking date values (PV) 134}
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
/* DCTG rules for lexical forms of built-in types. */
{Lexical form of string (PV) 106}
{Lexical form for NMTOKENs (PV) 150}
{Lexical form of decimal (PV) 112}
{Lexical form for dates (PV) 126}
{Lexical form for QNames (PV) 146}
{Lexical form for anyURI (PV) 153}
{Lexical form for list_anyURI (PV) 156}
{Lexical form for boolean (PV) 159}
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
/* Rules for pre-lexical forms against user-defined
* simple types. */
{Checking pre-lexical forms as SKU (PV) 142}
{Checking pre-lexical forms as quantities (PV) 138}
/* DCTG rules for lexical forms of user-defined simple
* types. */
{Lexical form for SKU (PV) 143}
{Lexical form for quantity type (PV) 140}
/* Value-base rules for user-defined simple types. */
{Checking quantity values against bounds (PV) 139}
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
{Conversion between atom/entity list and list of codes (PV) 103}
{Conversion between atom/entity list and list of characters 111}
{Utility for whitespace normalization (PV) 119}
{Normalizing to blanks (PV) 121}
{Collapsing whitespace (PV) 123}
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Generic predicates for simple types (2L) 376 >
4.2.15. Tests for validation of simple types
<!--* tests of lexical forms in elements and attributes *-->
<!DOCTYPE tests [
<!ENTITY ccedil "ç">
<!ENTITY Auml "Ä">
{Entity declarations for long number 110}
<!--*
{W3C copyright notice 86}
*-->
]>
<tests xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:po ="http://www.example.com/PO1"
>
{Simple test cases for strings (PV) 104}
{Simple test cases for decimals 109}
{Some test cases for dates 127}
{Some test cases for QNames 147}
{Some test cases for quantities 141}
{Some test cases for SKUs 144}
{Simple test cases for NMTOKEN values 151}
{Simple test cases for anyURI values 154}
{Simple test cases for list_anyURI values 157}
{Simple test cases for boolean values 160}
</tests>
<ok xsi:type="xsd:string">This is a sample string.</ok> <ok xsi:type="xsd:decimal"> 4.3 </ok> <not_ok xsi:type="xsd:integer"> 4.3 </not_ok> <ok xsi:type="xsd:date"> 2004-08-28 </ok> <not_ok xsi:type="po:quantity"> 2004-08-28 </not_ok> <not_ok xsi:type="po:SKU"> 2004-08-28 </not_ok>
/* pvtest.lf.pl: run the test cases for lexical form diagnostics.
*/
{W3C copyright notice 86}
testlf :- testlf(verbose).
testlf(KW) :-
write('Testing '), write(KW), write('ly:'), nl,
load_structure('2004/schema/dctg/Prolog/pvtest.lf.xml',
[element(tests, _Atts, Testcases)],
[dialect(xmlns), space(remove)]),
run_lf_tests(KW,Testcases).
run_lf_tests(_KW,[]).
run_lf_tests(KW,[element(ExpectedResult, Atts, Content) | Tail]) :-
run_lf_test(KW,Atts,ExpectedResult,Content),
run_lf_tests(KW,Tail).
run_lf_test(Msglvl,
['http://www.w3.org/2001/XMLSchema-instance':type=Val],
Expected,
Content) :-
{Write out what is expected for this test 170},
{Invoke the correct validation routine 171},
{Write out result of this test 172}.
(Msglvl = 'verbose'
-> {Write expectations (verbose) 173}
; Msglvl = 'terse'
-> {Write expectations (terse) 174}
; Msglvl = 'silent'
-> {Write expectations (silent) 175}
; /* unrecognized message level, default to verbose */
{Write expectations (verbose) 173}
)
This code is used in < Run one test 169 >
( Val = 'xsd:string'
-> sva_plf_t_xsd_string(Content,LF,PN,Lerr)
; Val = 'xsd:decimal'
-> sva_plf_t_xsd_decimal(Content,LF,PN,Lerr)
; Val = 'xsd:integer'
-> sva_plf_t_xsd_integer(Content,LF,PN,Lerr)
; Val = 'xsd:date'
-> sva_plf_t_xsd_date(Content,LF,PN,Lerr)
; Val = 'xsd:QName'
-> sva_plf_t_xsd_QName(Content,LF,PN,Lerr)
; Val = 'xsd:NMTOKEN'
-> sva_plf_t_xsd_NMTOKEN(Content,LF,PN,Lerr)
; Val = 'xsd:anyURI'
-> sva_plf_t_xsd_anyURI(Content,LF,PN,Lerr)
; Val = 'xsd:list_anyURI'
-> sva_plf_t_xsd_list_anyURI(Content,LF,PN,Lerr)
; Val = 'xsd:boolean'
-> sva_plf_t_xsd_boolean(Content,LF,PN,Lerr)
; Val = 'po:quantity'
-> sva_plf_t_e_quantity_t_e_item_t_Items(Content,LF,PN,Lerr)
; Val = 'po:SKU'
-> sva_plf_t_SKU(Content,LF,PN,Lerr)
)
This code is used in < Run one test 169 >
(Msglvl = 'verbose'
-> {Write out the result (verbose) 176}
; Msglvl = 'terse'
-> {Write out the result (terse) 177}
; Msglvl = 'silent'
-> {Write out the result (silent) 178}
; /* unrecognized message level, default to verbose */
{Write out the result (verbose) 176}
)
This code is used in < Run one test 169 >
( write(Val), write(': '),
write(Content),
nl,
write(' expected: '),
write(Expected), nl,
write(' check plf: '), nl
)
This code is used in < Write out what is expected for this test 170 >
( write(Val), write(': ') )
This code is used in < Write out what is expected for this test 170 >
true
This code is used in < Write out what is expected for this test 170 >
write(' got: '),
( Lerr = []
-> write('ok, lexform = ')
; write('not ok, lexform = ')
),
write(LF), nl,
tab(4), write(Lerr),
nl, nl
This code is used in < Write out result of this test 172 >
( ( Lerr = [], Expected = 'ok' )
-> write('ok / ok')
; ( Lerr = [], Expected = 'not_ok' )
-> write('!! expected error, got none !! Pre-lexical form = '),
write(Content)
; ( Lerr = [_|_], Expected = 'ok' )
-> write('!! expected ok, got not_ok !! Pre-lexical form = '),
write(Content), nl,
write(' Lerr = '),
write(Lerr)
; ( Lerr = [_|_], Expected = 'not_ok' )
-> write('not_ok / not_ok')
),
nl
This code is used in < Write out result of this test 172 >
( ( Lerr = [], Expected = 'ok' )
-> true
; ( Lerr = [], Expected = 'not_ok' )
-> write('!! expected error, got none !! Type = '),
write(Val),
write(', pre-lexical form = '),
write(Content),
nl
; ( Lerr = [_|_], Expected = 'ok' )
-> write('!! expected ok, got not_ok !! Type = '),
write(Val),
write(', pre-lexical form = '),
write(Content), nl,
write(' Lerr = '),
write(Lerr), nl
; ( Lerr = [_|_], Expected = 'not_ok' )
-> true
)
This code is used in < Write out result of this test 172 >
4.3. Validation of elements
4.3.1. Basic pattern for element rules
- In order to populate the validation context property of the element and its children, we pass the parsed node for the validation root down through all of these rules.
- In order to add the [in-scope namespaces] property for elements (it makes handling xsi:type easier), we also pass a list of inherited namespace bindings.
ELEMID(VRoot,Lnsb0) ::= [element(N:GI,Lras,Lre)],
{
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_ELEMID(Lras,Lre,Lnsb,Lerr0),
sva_atts_TYPEID(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_TYPEID(VRoot,Lnsb,Lre,Lpe,Lerr2)
}
<:> info_item(element)
&& attributes(Lpa)
... (as before) ...
&& schema_error_code(Lerr) ::-
flatten([Lerr0,Lerr1,Lerr2],Lerr)
&& validation_attempted(VA) ::-
calc_validation_attempted(Lpa,Lpe,VA)
&& validity(V) ::-
calc_validity(Lerr0,Lerr1,Lerr2,Lpa,Lpe,V)
&& validation_context(VRoot)
&& inscope_namespaces(Lnsb)
.
The inscope_namespaces predicate must be calculated
first, because we need to know what namespaces are in scope in order
to understand and check the value of an xsi:type
attribute; this in turn needs to happen before, not after, the
attributes and content are checked. So the inscope_namespaces
and sva_elemdecl_ELEMID predicates work with the
raw attribute-value pairs (Lras), not the parsed
ones (Lpa and Lpna).
4.3.2. Elements with complex types
/* e_purchaseOrder: grammatical rule for purchaseOrder element.
e_purchaseOrder(V,Lnsb,ParsedNode,L1,L2): holds if the
difference between L1 and L2 (difference lists) is a
purchase order element in SWI Prolog notation.
And so on for the other element types.
*/
e_purchaseOrder(VRoot,Lnsb0) ::= [
element('http://www.example.com/PO1':purchaseOrder,
Lras,Lre)],
{
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_purchaseOrder(Lras,Lre,Lnsb,Lerr0),
sva_atts_t_PurchaseOrderType(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_PurchaseOrderType(VRoot,Lnsb,Lre,Lpe,Lerr2)
}
<:> local_name(purchaseOrder)
&& namespace_name('http://www.example.com/PO1')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('PurchaseOrderType')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for complex elements (PV) 181}
.
e_shipTo_t_PurchaseOrderType(VRoot,Lnsb0) ::= [element(shipTo,Lras,Lre)],
{
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_shipTo_t_PurchaseOrderType(Lras,Lre,Lnsb,Lerr0),
sva_atts_t_USAddress(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_USAddress(VRoot,Lnsb,Lre,Lpe,Lerr2)
}
<:> local_name(shipTo)
&& namespace_name('')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('USAddress')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for complex elements (PV) 181}
.
e_billTo_t_PurchaseOrderType(VRoot,Lnsb0) ::= [element(billTo,Lras,Lre)],
{
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_billTo_t_PurchaseOrderType(Lras,Lre,Lnsb,Lerr0),
sva_atts_t_USAddress(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_USAddress(VRoot,Lnsb,Lre,Lpe,Lerr2)
}
<:> local_name(billTo)
&& namespace_name('')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('USAddress')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for complex elements (PV) 181}
.
e_items_t_PurchaseOrderType(VRoot,Lnsb0) ::= [element(items,Lras,Lre)],
{
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_items_t_PurchaseOrderType(Lras,Lre,Lnsb,Lerr0),
sva_atts_t_Items(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_Items(VRoot,Lnsb,Lre,Lpe,Lerr2)
}
<:> local_name(items)
&& namespace_name('')
&& type_definition_anonymous('false')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('Items')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for complex elements (PV) 181}
.
e_item_t_Items(VRoot,Lnsb0) ::= [element(item,Lras,Lre)],
{
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_item_t_Items(Lras,Lre,Lnsb,Lerr0),
sva_atts_t_e_item_t_Items(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_e_item_t_Items(VRoot,Lnsb,Lre,Lpe,Lerr2)
}
<:> local_name(item)
&& namespace_name('')
&& type_definition_anonymous('true')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('t_e_item_t_Items')
&& type_definition_type(complex)
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for complex elements (PV) 181}
.
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
&& info_item(element)
&& attributes(Lpa)
&& namespace_attributes(Lpna)
&& inscope_namespaces(Lnsb)
&& children(Lpe)
&& schema_error_code(Lerr) ::-
flatten([Lerr0,Lerr1,Lerr2],Lerr)
&& validity(V) ::-
calc_validity(Lerr0,Lerr1,Lerr2,Lpa,Lpe,V)
{Additional PSVI properties for elements (PV) 205}
This code is used in < Rules for elements with complex types (PV) 179 > < Rules for elements with simple types (PV) 183 >
&& validation_attempted(VA) ::-
calc_validation_attempted(Lpa,Lpe,VA)
This code is used in < Rules for elements with complex types (PV) 179 >
&& validation_attempted(full)
This code is used in < Rules for elements with simple types (PV) 183 >
4.3.3. Elements with simple types
e_comment(VRoot,Lnsb0) ::=
[element('http://www.example.com/PO1':comment,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_comment(Lras,Lre,Lnsb,Lerr0),
{Guard to check attributes and content of strings (PV) 184} }
<:> local_name(comment)
&& namespace_name('http://www.example.com/PO1')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for strings 5}
.
e_name_t_USAddress(VRoot,Lnsb0) ::= [element(name,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_name_t_USAddress(Lras,Lre,Lnsb,Lerr0),
{Guard to check attributes and content of strings (PV) 184} }
<:> local_name(name)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for strings 5}
.
e_street_t_USAddress(VRoot,Lnsb0) ::= [element(street,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_street_t_USAddress(Lras,Lre,Lnsb,Lerr0),
{Guard to check attributes and content of strings (PV) 184} }
<:> local_name(street)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for strings 5}
.
e_city_t_USAddress(VRoot,Lnsb0) ::= [element(city,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_city_t_USAddress(Lras,Lre,Lnsb,Lerr0),
{Guard to check attributes and content of strings (PV) 184} }
<:> local_name(city)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for strings 5}
.
e_state_t_USAddress(VRoot,Lnsb0) ::= [element(state,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_state_t_USAddress(Lras,Lre,Lnsb,Lerr0),
{Guard to check attributes and content of strings (PV) 184} }
<:> local_name(state)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for strings 5}
.
e_zip_t_USAddress(VRoot,Lnsb0) ::= [element(zip,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_zip_t_USAddress(Lras,Lre,Lnsb,Lerr0),
sva_atts_simpletype(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_xsd_decimal(Lre,Lpe,Lerr2) }
<:> local_name(zip)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for decimals 6}
.
e_productName_t_e_item_t_Items(VRoot,Lnsb0) ::= [element(productName,
Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_productName_t_e_item_t_Items(Lras,Lre,Lnsb,Lerr0),
{Guard to check attributes and content of strings (PV) 184} }
<:> local_name(productName)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for strings 5}
.
e_quantity_t_e_item_t_Items(VRoot,Lnsb0) ::= [element(quantity,
Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_quantity_t_e_item_t_Items(Lras,Lre,Lnsb,Lerr0),
sva_atts_simpletype(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_e_quantity_t_e_item_t_Items(Lre,Lpe,Lerr2) }
<:> local_name(quantity)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
&& type_definition_anonymous('true')
&& type_definition_namespace('http://www.example.com/PO1')
&& type_definition_name('t_e_quantity_t_e_item_t_Items')
&& type_definition_type(simple)
.
e_USPrice_t_e_item_t_Items(VRoot,Lnsb0) ::=
[element('USPrice',Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_USPrice_t_e_item_t_Items(Lras,Lre,Lnsb,Lerr0),
sva_atts_simpletype(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_xsd_decimal(Lre,Lpe,Lerr2) }
<:> local_name('USPrice')
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
{PSVI properties for decimals 6}
.
e_shipDate_t_e_item_t_Items(VRoot,Lnsb0) ::=
[element(shipDate,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_e_shipDate_t_e_item_t_Items(Lras,Lre,Lnsb,Lerr0),
sva_atts_simpletype(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_xsd_date(Lre,Lpe,Lerr2) }
<:> local_name(shipDate)
&& namespace_name('')
{Common infoset properties for elements in po namespace (PV) 180}
{Validation attempted property for simple elements (PV) 182}
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('date')
&& type_definition_type(simple)
.
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
sva_atts_simpletype(Lras,VRoot,Lpa,Lpna,Lerr1),
sva_content_t_xsd_string(Lre,Lpe,Lerr2)
This code is used in < Rules for elements with simple types (PV) 183 >
4.3.4. Maintaining the list of inscope namespaces
- Lnsb0 is the list of inherited namespace bindings.
- Lras is the list of raw attribute-value specifications in Anjewierden/Wielemaker form.
- Lnsb is the resulting list of active namespace bindings.
inscope_namespaces(Lnsb,[],Lnsb).Continued in <Calculating in-scope namespaces, cont'd (PV) 186>, <Calculating in-scope namespaces, cont'd (PV) 187>, <Removing a namespace binding (PV) 188>
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Calculating in-scope namespaces (2L) 351 >
inscope_namespaces(Lnsb0,[xmlns=DefaultNS|Lras],
[ns('',DefaultNS) | Lnsb]) :-
remove_binding(Lnsb0,'',Lnsb1),
inscope_namespaces(Lnsb1,Lras,Lnsb).
inscope_namespaces(Lnsb0,[xmlns:Prefix=NS|Lras],
[ns(Prefix,NS) | Lnsb]) :-
remove_binding(Lnsb0,Prefix,Lnsb1),
inscope_namespaces(Lnsb1,Lras,Lnsb).
inscope_namespaces(Lnsb0,[AN=_AV|Lras],Lnsb) :- AN \= xmlns, AN \= xmlns:_Prefix, inscope_namespaces(Lnsb0,Lras,Lnsb).
/* remove_binding(+Lnsb0,+Prefix,-Lnsb): true if Lnsb is the
* result of removing any binding for Prefix from Lnsb0.
* In principle, there should be at most one such
* binding, but we check for accidental doubles.
* If this proves expensive, we can revisit this decision.
*/
/* Base case: no more bindings to check. */
remove_binding([],_Prefix,[]).
/* Match case: remove head, check in tail. */
remove_binding([ns(P,_NS) | Lnsb0], P, Lnsb) :-
remove_binding(Lnsb0,P,Lnsb).
/* Keep-looking case: head does not match, check in tail
* and put head back on. */
remove_binding([ns(P1,NS1)|Lnsb0], Prefix,
[ns(P1,NS1) | Lnsb]) :-
P1 \= Prefix,
remove_binding(Lnsb0,Prefix,Lnsb).
4.3.5. Checking elements against their element declarations
4.3.5.1. Requirements
- cvc-elt.1: The element declaration is present in the schema.
- cvc-elt.2: The element declaration has {abstract} = false.
- cvc-elt.3.1: If the element is not nillable (i.e. if the element declaration has {nillable} = false) then there is no xsi:nil attribute on the element instance (it seems odd to forbid the document author to specify xsi:nil="false", but the spec does so).
- cvc-elt.3.2, If the element is nillable and the element instance has xsi:nil="true", then (a) the element has no fixed value constraint, and (b) the element instance is empty (has no character or element children).
- cvc-elt.4: If the element instance has an xsi:type attribute, then (a) the attribute value is a QName, (b) the QName resolves to a type definition T, and (c) type definition T is validly derived from the type definition declared for the element in the schema. Type definition T should be used in validation in place of the declared type.
- cvc-elt.5.1: If (a) the element has a value constraint, (b) the element is empty, and (c) the element has not been nilled out, then the canonical lexical representation of the value given in the value constraint is valid against the appropriate type.
- cvc-elt.5.2: If (a) the element has no value
constraint, or (b) the element is not empty, or (c) the element has
been nilled out, then
- cvc-elt.5.2.1 The element is valid against the appropriate type definition.
- cvc-elt.5.2.2 If the element has a value constraint
and has not been nilled out, then
- cvc-elt.5.2.2.1 The element has no element children.
- cvc-elt.5.2.2.2.1 If the element is declared as having mixed content, then the initial value of the element instance — i.e. the sequence of characters in the element instance, without whitespace normalization — must match the canonical lexical representation (sic) of the value in the value constraint.
- cvc-elt.5.2.2.2.2 If the element is declared as having a simple type, then the actual value of the element instance — i.e. the value mapped to by the whitespace-normalized string in the instance — must match the canonical lexical representation (sic!) of the value in the value constraint.
- cvc-elt.6: The element instance is valid against the applicable identity constraints.
- cvc-elt.7: If the element instance is the validation
root, then
- cvc-id.1 Every ID or IDREF validated under this validation root identifies at least one element carrying that ID.
- cvc-id.2 Each ID or IDREF validated under this validation root identifies at most one element carrying that ID.
- The schema is closed under reference to element declarations: All element declarations referred to anywhere in the schema are present in the schema.
- No element declarations are abstract.
- No elements are nillable.
- No elements have value constraints.
- No elements have identity constraints.
- Types ID, IDREF, and IDREFs are not used.
- cvc-elt.3.1: There is no xsi:nil attribute on the element instance.
- cvc-elt.4: If the element instance has an xsi:type attribute, then (4.1) the attribute value is a QName, (4.2) the QName resolves to a type definition T, and (4.3) type definition T is validly derived from the type definition declared for the element in the schema. Type definition T should be used in validation in place of the declared type.
- cvc-elt.5.2.1 The element is valid against the appropriate type definition.
4.3.5.2. General pattern
/* sva_elemdecl_ELEMID(+Lras, +Lre, +Lnsb, -Lerr) */
sva_elemdecl_ELEMID(Lras,Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(ELEMID), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(ELEMID, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
4.3.5.3. The sva_xsitype predicate
/* sva_xsitype(+Elemid, +QN_LocalType, +Lnsb, -TypeID, -Lerr): true if
Lerr is the list of errors involved if QN_LocalType is
the value of an xsi:type attribute on an element of type
Elemid, with Lnsb the list of active namespace bindings.
*/
sva_xsitype(Elemid, QN_LocalType, Lnsb, Typeid, Lerr) :-
/* First, check that it's a legal QName */
( sva_plf_t_xsd_QName(QN_LocalType,LF,PN,Lerr0)
-> {Check return from QName check (PV) 190}
; Lerr = [error('cvc-elt.4.1',
'xsi:type attribute should have a legal QName as its value',
[element(Elemid),localtype(QN_LocalType),
trace('sva_plf_t_xsd_QName did not return')])]).
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
(Lerr0 = []
-> {Resolve QName reference to type (PV) 191}
; Lerr = [error('cvc-elt.4.1',
'xsi:type attribute should have a legal QName as its value',
[element(Elemid),localtype(QN_LocalType),lf(LF),
ce(Lerr0)])])
This code is used in < Check value given in xsi:type (PV) 189 > < Check value given in xsi:type (2L) 352 >
/* Second, check that it resolves to a known type definition */
(sva_xsitype_resolve(PN, Lnsb, Typeid, Lerr1)
-> {Check return from QName resolution (PV) 192}
; Lerr = [error('cvc-elt.4.2','xsi:type failed to resolve',
[element(Elemid), localtype(QN_LocalType),
trace('sva_xsitype_resolve did not return')])])
This code is used in < Check return from QName check (PV) 190 >
(Lerr1 = []
-> {Check that type reference is legal (PV) 193}
; Lerr = [error('cvc-elt.4.2','xsi:type must name a type',
[element(Elemid), localtype(QN_LocalType),ce(Lerr1)])])
This code is used in < Resolve QName reference to type (PV) 191 >
/* Third, check that the named type is substitutable for the declared
* type; this depends both on the type definitions and on the element
* declaration */
(type_substitutable(Elemid, Typeid, Lerr2)
-> {Check return from Type Derivation OK (PV) 194}
; Lerr = [error('cvc-elt.4.3',
'failure checking legal derivation of xsi:type from declared type',
[element(Elemid), type(Typeid),
trace('type_substitutable did not return')])])
This code is used in < Check return from QName resolution (PV) 192 >
(Lerr2 = []
-> Lerr = []
; Lerr = [error('cvc-elt.4.3',
'xsi:type must name a type legally derived from declared type',
[element(Elemid), localtype(QN_LocalType), type(Typeid),
ce(Lerr2)])])
This code is used in < Check that type reference is legal (PV) 193 >
4.3.5.4. Auxiliary predicates for checking xsi:type
- sva_plf_t_xsd_QName(QN_LocalType, LF, PN, Lerr0): this is the standard rule for validating a pre-lexical form as a QName; it was defined in section 4.2.9
- sva_xsitype_resolve(Elemid, QN_LocalType, Lnsb, Typeid, Lerr1)
- type_substitutable(Elemid, Typeid, Lerr2)
4.3.5.5. Resolving the type name
/* was: sva_xsitype_resolve(+Elemid, +QN_LocalType, +Lnsb, -Typeid, -Lerr): */ /* sva_xsitype_resolve(+PN, +Lnsb, -Typeid, -Lerr): true iff the parsed QName PN resolves, in the context of the current list of namespace bindings Lnsb and the current schema, to type Typeid, or else we get the errors in Lerr. */ sva_xsitype_resolve(PN, Lnsb, Typeid, Lerr) :- qname_expand(PN, Lnsb, EName, Lerr0), ename_typeid(EName, Typeid, Lerr1), append(Lerr0, Lerr1, Lerr).
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
/* qname_expand(PNodeQN, Lnsb, EName, Lerr) */
qname_expand(PNodeQN, Lnsb, EName, Lerr) :-
PNodeQN ^^ prefix(Prefix),
PNodeQN ^^ local_name(Name),
( member(ns(Prefix,NS), Lnsb)
-> (EName = expqname(NS,Name,Prefix),
Lerr = [])
; (EName = error,
Lerr = [error(pv_nsb,'no namespace binding found',
[name(Name), prefix(Prefix)])])
).
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Expand Qname to expanded name triple (2L) 355 >
/* ename_typeid(expqname(NS,Name,Pre), Typeid, Lerr):
true iff Typeid is the atom used as type ID for the type
named by the expanded QName. This is just a specialized
form of generic QName resolution, for types, but it's
guaranteed to succeed.
*/
ename_typeid(expqname(NS,Name,_Pre), Typeid, Lerr) :-
( qname_resolve(type,NS,Name,Typeid)
-> Lerr = []
; Lerr = [error(pv_ename_typeid, 'expanded name does not map to a type',
[ns(NS), ln(Name)])]).
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
/* Schema-specific types */ qname_resolve(type,'http://www.example.com/PO1','PurchaseOrderType', 't_PurchaseOrderType'). qname_resolve(type,'http://www.example.com/PO1','USAddress', 't_USAddress'). qname_resolve(type,'http://www.example.com/PO1','Items', 't_Items'). qname_resolve(type,'http://www.example.com/PO1','SKU', 't_SKU'). /* Builtin types (selective) */ qname_resolve(type,'http://www.w3.org/2001/XMLSchema','string', 't_xsd_string'). qname_resolve(type,'http://www.w3.org/2001/XMLSchema','integer', 't_xsd_integer'). qname_resolve(type,'http://www.w3.org/2001/XMLSchema','decimal', 't_xsd_decimal'). qname_resolve(type,'http://www.w3.org/2001/XMLSchema','date', 't_xsd_date'). /* For now, we have no need to resolve element references. But for completeness, we'll list them anyway. */ qname_resolve(element,'http://www.example.com/PO1','purchaseOrder', 'e_purchaseOrder'). qname_resolve(element,'http://www.example.com/PO1','comment', 'e_comment').
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
4.3.5.6. Checking type subsitutability
/* type_subsitutable(Elemid, Typeid, Lerr): true iff type Typeid
* may legally be substituted for the declared type of Elemid
* (e.g. via an xsi:type attribute).
* Both the element and the type are denoted by IDs.
*/
type_substitutable(E,T,Lerr) :-
( elem_type(E,Tdecl),
type_derivation_ok(Tdecl,T)
-> Lerr = []
; Lerr = [error('cos-tt-derived-ok','Type derivation not OK',
[element(E), declaredtype(Tdecl), xsitype(T)])]).
/* N.B. the type_derivation_ok predicate given here is specialized
for the purchase-order schema. It needs to be generalized
before it's correct for the general case. */
/* Generic rule: every named type is substitutable for itself. */
type_derivation_ok(T,T).
/* Recursive rule: every named type is substitutable for its base
type (unless the base type has blocked subsitutions),
or for anything its base type is substitutable for. */
type_derivation_ok(P,C) :-
P \= C,
type_base(C,D),
( P = D
; type_derivation_ok(P,D)).
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Checking type derivations (2L) 353 >
/* Schema-specific derivations: */ /* For purchase-order schema, there are none: all of the * elements are declared with leaf types */ type_base(t_PurchaseOrderType, t_anyType). type_base(t_USAddress, t_anyType). type_base(t_Items, t_anyType). type_base(t_e_item_t_Items, t_anyType). type_base(t_e_quantity_t_e_item_t_Items, t_xsd_positiveInteger). type_base(t_SKU, t_xsd_string).
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
/* Some derivations common to all schemas. Here we list
only those which would be theoretically relevant for
checking xsi:type in the purchase-order schema.
(But since we don't actually have full definitions
of them, the PV grammar doesn't actually check them;
its support for xsi:type is thus incomplete.) */
/* Types derived from string */
type_base(t_xsd_string, t_xsd_anySimpleType).
type_base(t_xsd_normalizedString,t_xsd_string).
type_base(t_xsd_token,t_xsd_normalizedString).
type_base(t_xsd_language,t_xsd_token).
type_base(t_xsd_Name,t_xsd_token).
type_base(t_xsd_NCName,t_xsd_Name).
type_base(t_xsd_ID,t_xsd_NCName).
type_base(t_xsd_IDREF,t_xsd_NCName).
type_base(t_xsd_ENTITY,t_xsd_NCName).
type_base(t_xsd_NMTOKEN,t_xsd_token).
/* Types derived from decimal */
type_base(t_xsd_decimal, t_xsd_anySimpleType).
type_base(t_xsd_integer,t_xsd_decimal).
type_base(t_xsd_nonPositiveInteger,t_xsd_integer).
type_base(t_xsd_negativeInteger,t_xsd_nonPositiveInteger).
type_base(t_xsd_long,t_xsd_integer).
type_base(t_xsd_int,t_xsd_long).
type_base(t_xsd_short, t_xsd_int).
type_base(t_xsd_byte, t_xsd_short).
type_base(t_xsd_nonNegativeInteger,t_xsd_integer).
type_base(t_xsd_positiveInteger,t_xsd_nonNegativeInteger).
type_base(t_xsd_unsignedLong,t_xsd_nonNegativeInteger).
type_base(t_xsd_unsignedInt,t_xsd_nonNegativeInteger).
type_base(t_xsd_unsignedShort,t_xsd_nonNegativeInteger).
type_base(t_xsd_unsignedByte,t_xsd_nonNegativeInteger).
/* Types derived from date (none in this schema) */
type_base(t_xsd_date, t_xsd_anySimpleType).
/* Hmm. I wonder if this should be done with ENames rather
than with type ids.
base_type('http://www.w3.org/2001/XMLSchema':anySimpleType,
'http://www.w3.org/2001/XMLSchema':duration).
base_type('http://www.w3.org/2001/XMLSchema':anySimpleType,
'http://www.w3.org/2001/XMLSchema':dateTime).
base_type('http://www.w3.org/2001/XMLSchema':anySimpleType,
'http://www.w3.org/2001/XMLSchema':time).
base_type('http://www.w3.org/2001/XMLSchema':anySimpleType,
'http://www.w3.org/2001/XMLSchema':date).
base_type('http://www.w3.org/2001/XMLSchema':anySimpleType,
'http://www.w3.org/2001/XMLSchema':date).
*/
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
4.3.5.7. Element-type bindings
elem_type(e_purchaseOrder,t_PurchaseOrderType). elem_type(e_comment,t_xsd_string). elem_type(e_shipTo_t_PurchaseOrderType,t_USAddress). elem_type(e_billTo_t_PurchaseOrderType,t_USAddress). elem_type(e_items_t_PurchaseOrderType,t_Items). elem_type(e_name_t_USAddress,t_xsd_string). elem_type(e_street_t_USAddress,t_xsd_string). elem_type(e_city_t_USAddress,t_xsd_string). elem_type(e_state_t_USAddress,t_xsd_string). elem_type(e_zip_t_USAddress,t_xsd_decimal). elem_type(e_item_t_Items,t_e_item_t_Items). elem_type(e_productName_t_e_item_t_Items,t_xsd_string). elem_type(e_quantity_t_e_item_t_Items,t_e_quantity_t_e_item_t_Items). elem_type(e_USPrice_t_e_item_t_Items,t_xsd_decimal). elem_type(e_shipDate_t_e_item_t_Items,t_xsd_date).
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
4.3.5.8. Top-level rules for checking elements against their declarations
sva_elemdecl_e_purchaseOrder(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_purchaseOrder), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_purchaseOrder, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_comment(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_comment), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_comment, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_shipTo_t_PurchaseOrderType(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_shipTo_t_PurchaseOrderType), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_shipTo_t_PurchaseOrderType, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_billTo_t_PurchaseOrderType(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_billTo_t_PurchaseOrderType), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_billTo_t_PurchaseOrderType, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_items_t_PurchaseOrderType(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_items_t_PurchaseOrderType), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_items_t_PurchaseOrderType, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_name_t_USAddress(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_name_t_USAddress), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_name_t_USAddress, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_street_t_USAddress(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_street_t_USAddress), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_street_t_USAddress, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_city_t_USAddress(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_city_t_USAddress), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_city_t_USAddress, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_state_t_USAddress(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_state_t_USAddress), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_state_t_USAddress, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_zip_t_USAddress(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_zip_t_USAddress), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_zip_t_USAddress, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_item_t_Items(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_item_t_Items), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_item_t_Items, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_productName_t_e_item_t_Items(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_productName_t_e_item_t_Items), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_productName_t_e_item_t_Items, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_quantity_t_e_item_t_Items(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_quantity_t_e_items_t_Items), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_quantity_t_e_items_t_Items, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_USPrice_t_e_item_t_Items(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_USPrice_t_e_item_t_Items), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_USPrice_t_e_item_t_Items, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
sva_elemdecl_e_shipDate_t_e_item_t_Items(Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(e_shipDate_t_e_item_t_Items), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(e_shipDate_t_e_item_t_Items, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
sva_elemdecl(Elemid,Lras,_Lre,Lnsb,Lerr) :-
(member('http://www.w3.org/2001/XMLSchema-instance':nil=_Value,
Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(Elemid), atts(Lras)])]
; Lerr0 = []),
(member(
'http://www.w3.org/2001/XMLSchema-instance':type=QN_LocalType,
Lras)
-> sva_xsitype(Elemid, QN_LocalType, Lnsb, TypeID, Lerr1)
; Lerr1 = []),
append(Lerr0,Lerr1,Lerr).
This code is not used elsewhere.
4.3.6. Adding properties to the PSVI
- [local name]
- [namespace name]
- [attributes]
- [namespace attributes]
- [children]
- [type definition name] (Element Validated by Type)
- [type definition namespace] (Element Validated by Type) — for this schema, this will always be either the purchase-order namespace or nothing (‘absent’)
- [type definition anonymous] (Element Validated by Type) — true or false
- [type definition type] (Element Validated by Type) — simple or complex
- [validation attempted] (Assessment Outcome (Element)) — full, none, or partial
- [validity] (Assessment Outcome (Element)) — valid, invalid, or notKnown
- [nil] (Element Declaration) — true if the type is nillable and the element is nil in fact, false otherwise (the spec introduces this as an alternative to [element declaration]; if [element declaration] is provided, this information is redundant, although perhaps inconvenient to obtain otherwise).Since no element types in the purchase order schema are nillable, we can hard-code the value:< 205 Additional PSVI properties for elements (PV) > ≡
&& nil(false)
Continued in <Validation-context property for elements (PV) 209>
This code is used in < Common infoset properties for elements in po namespace (PV) 180 > - [schema error code] (Validation Failure (Element)) — either absent or a list of error codes.This has been provided above in the element rules.
- [schema information] (Schema Information) — attached to the element at which schema-validity assessment began (for us, always the purchaseOrder element); value is a set of namespace schema information items, which are triplets of (namespace, components, documents); lightweight processors are expected to leave the lists of components empty, but I propose to put in at least a list of schema-component designators.The schema information property has some sub-properties:
- namespace schema information information item properties
- [schema namespace] (Schema Information)
- [schema components] (Schema Information)
- [schema documents] (Schema Information); these in turn have properties of their own:
- [document] (Schema Information)
- [document location] (Schema Information)
Since this is a hard-coded schema, it's not clear that it makes sense to provide a document location for the schema document we worked from. But as a way of illustrating how it should work and where it should go, we will provide an accurate hard-coded value. If we use an ad-hoc predicate pv_schemainfo to initialize the variable Builtins with the list of built-in types, and POSchemainfo with the schema-specific information, then we can write the rule this way:< 206 Schema information property for root element (PV) > ≡&& schema_information([Builtins, POSchemainfo]) ::- pv_schemainfor(Builtines,POSchemainfo)
This code is not used elsewhere.The predicate pv_schemainfo is straightforward to write:< 207 Schema-information predicate (PV) > ≡pv_schemainfo(Builtins, POSchemainfo) :- Builtins = ns_triple( ns('http://www.w3.org/2001/XMLSchema'), components(['/simpleType(xsd:string)', '/simpleType(xsd:integer)', '/simpleType(xsd:decimal)', '/simpleType(xsd:date)', '/simpleType(xsd:QName)', '/simpleType(xsd:boolean)', '/simpleType(xsd:t_a_schemaLocation)', '/complexType(xsd:anyType)']), documents([])), POSchemainfo = ns_triple( ns('http://www.example.com/PO1'), components(['/simpleType(po:SKU)', '/complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(quantity) /simpleType()', '/complexType(po:PurchaseOrderType)', '/complexType(po:USAddress)', '/complexType(po:Items)', '/complexType(po:Items)/sequence() /element(item)/complexType()', '/element(po:purchaseOrder)', '/element(po:comment)', '/complexType(po:PurchaseOrderType) /sequence() /element(shipTo)', '/complexType(po:PurchaseOrderType) /sequence() /element(billTo)', '/complexType(po:PurchaseOrderType) /sequence() /element(items)', '/complexType(po:USAddress) /sequence() /element(name)', '/complexType(po:USAddress) /sequence() /element(street)', '/complexType(po:USAddress) /sequence() /element(city)', '/complexType(po:USAddress) /sequence() /element(state)', '/complexType(po:USAddress) /sequence() /element(zip)', '/complexType(po:Items) /sequence() /element(item)', '/complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(productName)', '/complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(quantity)', '/complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(USPrice)', '/complexType(po:Items) /sequence() /element(item) /complexType() /sequence() /element(shipDate)']), documents([schema_document([], 'file:///mnt/pidgin/usr/lib/xmlschema/po/po1.xsd')])).
This code is used in < [File load_pv.pl] 257 > < Initiating schema-validity assessment, po-specific (2L) 318 >The next question is how to attach the property to the parsed node for the root element. Two solutions offer themselves:- Add the property to the rule for purchaseOrder; this only ever appears as the root element. For the case where the root is not a locally valid purchase-order element, add a new rule to the simple fallback grammar defined in section 4.5.3, which distinguishes the root element from other elements.
- Add the property outside the grammar mechanism: do normal parsing, and then add the schema information property to the top-level node's list of properties.
< 208 Identify a parsed node as the validation root (PV) > ≡anoint_root(Node,Rootnode) :- Node = node(NT,RHS,Props), pv_schemainfo(BI,SI), Rootnode = node(NT,RHS, [schema_information([BI,SI])|Props]).
This code is used in < [File load_pv.pl] 257 > < Initiating schema-validity assessment, generic (2L) 317 > - namespace schema information information item properties
- [validation context] (Assessment Outcome (Element)) — the element at which validation began.To make this work, we need to pass some representation of the validation root as an inherited attribute down through all parsed elements. Thus VRoot has been visible as a new parameter in the sva_content predicates above and will be visible in the complex-content grammar rules below. We always use the same variable name, so that we can use the same scrap of code to specify the root for all elements:< 209 Validation-context property for elements (PV) [continues 205 Additional PSVI properties for elements (PV)] > ≡
&& validation_context(VRoot)
- [schema default] (Element Validated by Type) — the canonical lexical representation of a default or fixed value (provided whether the value is defaulted or not). No elements in the purchase-order have default values, so there is nothing to put this on.
- [schema normalized value] (Element Validated by Type) — if the element is not nilled, and did not default to a default value,[17] then this is the normalized value as validated, otherwise it's absent. There are no elements in the purchase-order schema to which this could apply.
- [schema specified] (Element Default Value) — schema or infoset.
- [element declaration] (Element Declaration) — since this schema does not provide PSVI-style access to the schema components themselves, we have nothing to provide here. There are in any case no elements in the purchase-order schema to which this could apply.
- [ID/IDREF table] (ID/IDREF Table) — a set of (id, binding) pairs showing all the IDs used or referred to in a document and the elements to which they are bound (an empty binding reveals an IDREF to a non-existent ID); the purchase order schema has no IDs, and exposing this property is in any case optional for any processor
- [identity-constraint table] (Identity-constraint Table) — since there are no identity constraints in the purchase-order schema used here as an example, this would in any case be empty
- [type definition] (Element Validated by Type) — we are not exposing the schema components yet
- [member type definition] (Element Validated by Type) — we are not exposing the schema components yet
- [member type definition anonymous] (Element Validated by Type) — the purchase-order schema has no simple union types
- [member type definition name] (Element Validated by Type) — the purchase-order schema has no simple union types
- [member type definition namespace] (Element Validated by Type) — the purchase-order schema has no simple union types
- [notation] (Validated with Notation) — we are not exposing the schema components yet
- [notation public] (Validated with Notation) — the purchase-order schema does not have any declared notations
- [notation system] (Validated with Notation) — the purchase-order schema does not have any declared notations
4.3.7. Calculating the validity and validation attempted properties
calc_validation_attempted(Lpa,Lpe,VA) :- append(Lpa,Lpe,Lpall), calc_validation_attempted(Lpall,VA). calc_validation_attempted([],full). calc_validation_attempted([Pnode | LPnode],VA) :- Pnode ^^ validation_attempted(VA0), (VA0 = full -> calc_validation_attempted(LPnode,VA) ; VA = partial). /* two additional rules, slightly ad hoc, for the * lexical representations of simple types, which * show up here as atoms. */ /* I believe this are unnecessary if elements with * simple types use the correct rule to set v_a. * Let's put this belief to the test and comment them * both back out. */ /* calc_validation_attempted([Atom | LPnode],VA) :- atom(Atom), calc_validation_attempted(LPnode,VA). */ /* calc_validation_attempted(Atom,full) :- atom(Atom). */Continued in <Calculating element validity (PV) 211>, <Invalid child (PV) 212>, <Invalid attribute (PV) 213>
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Calculating validation-attempted property (2L) 356 >
- It was strictly assessed.
- It was valid against its element declaration.
- It was valid against its type definition.
- It has no invalid children and no invalid attributes.
- It has no child or attribute whose declaration we were required to find but did not find (i.e. no child or attribute which matched a strict wildcard but had no declaration).
- it was invalid against its element declaration, or
- it was invalid against its type definition, or
- it has an invalid child or an invalid attribute, or
- it has some child or attribute whose declaration we were required to find but did not find (i.e. no child or attribute which matched a strict wildcard but had no declaration)
- We don't call call the calc_validity predicate in grammar PV except when we have assessed an element against both its element declaration and the relevant type definition. If we have locally assessed an element against either a type definition or an element declaration, then we have ‘strictly assessed’ the element, as that term is defined by [W3C 2001b]. So we will always return either valid or invalid, never notKnown.
- Elements are valid against their element declaration if and only if the sva_elemdecl_ELEMID predicate returns an empty list of errors. This will almost always be the case for the PV grammar, since few of the conditions which can make an element invalid against an element declaration apply in our schema: we don't have missing or abstract element declarations, no elements are nillable, and the only value constraint is on an attribute, not an element.
- Elements are valid against their type definition if and only if the sva_content_TYPEID and sva_atts_TYPEID predicates succeed with empty error lists.
- To check for invalid children and invalid attributes, we must examine the validity property on the children and attributes.
- There are no wildcards (strict or otherwise) in the purchase-order schema, so it's not possible to have any element or attribute whose declaration we were required to find but did not find (i.e. no child or attribute which matched a strict wildcard but had no declaration).
if sva_elemdecl(EII, ED) = invalid then invalid else if sva_eii_type(EII, Type) = invalid then invalid else if has_invalid_child(EII) then invalid else if has_invalid_att(EII) then invalid else valid
/* calc_validity(Lerr0, Lerr1, Lerr2, Lpa, Lpe, Validity): true
if the error lists, children, and attributes given produce
Validity when we calculate the [validity] property of the
element information item. */
calc_validity(Lerr0, Lerr1, Lerr2, Lpa, Lpe, V) :-
(Lerr0 \= []
-> V = invalid % error vis a vis element declaration
; (Lerr1 \= []
-> V = invalid % error parsing the attributes
; (Lerr2 \= []
-> V = invalid % error parsing the children
; (invalid_child(Lpe)
-> V = invalid % there is at least one invalid child
; (invalid_att(Lpa)
-> V = invalid % there is at least one invalid attribute
; V = valid % OK against element declaration,
% OK against type (both atts and children)
% all children and atts OK
))))).
invalid_child([]) :- !, fail. invalid_child([Ch|_Lch]) :- Ch ^^ validity(invalid), !. invalid_child([Ch|Lch]) :- Ch ^^ validity(V), V \= invalid, invalid_child(Lch).
invalid_att([]) :- !, fail. invalid_att([Att|_Latt]) :- Att ^^ validity(invalid), !. invalid_att([Att|Latt]) :- Att ^^ validity(V), V \= invalid, invalid_att(Latt).
4.4. Validation of attributes
- [schema default] (Attribute Validated by Type) — canonical form of the default value, if any
- [schema error code] (Validation Failure (Attribute)) — a list of error diagnostics, or else absent
- [schema normalized value] (Attribute Validated by Type) — the normalized value as validated
- [validation context] (Assessment Outcome (Attribute))
- [attribute declaration] (Attribute Declaration) — we are not exposing the schema components yet
- [member type definition] (Attribute Validated by Type) — the purchase-order schema has no union types
- [member type definition anonymous] (Attribute Validated by Type) — the purchase-order schema has no union types
- [member type definition name] (Attribute Validated by Type) — the purchase-order schema has no union types
- [member type definition namespace] (Attribute Validated by Type) — the purchase-order schema has no union types
- [type definition] (Attribute Validated by Type) — we are not exposing the schema components yet
4.4.1. Attribute rules for complex types
sva_atts_TYPEID(Lras,VRoot,Lpa,Lpna,Lerr) :- lras_TYPEID(VRoot,LpaAll,Lras,[]), LpaAll^^errors(Lerr0), partition(LpaAll,LpaPres,Lpna), attocc_TYPEID(LpaPres,Lpa,Lerr1), append(Lerr0, Lerr1, Lerr).We must ensure that the rule succeeds even if the element's attributes are not all valid or declared. We do this by adding a failsafe rule to each grammar for attributes, which will match any attribute at all other than a namespace declaration, an attribute in the xsi namespace, or a declared attribute.
/* Rules for validating attributes against complex types */
{Attribute rules for purchase-order type (PV) 218}
{Attribute rules for US address type (PV) 227}
{Attribute handling for Items type (PV) 230}
{Attribute handling for t_e_item_t_Items (PV) 231}
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
/* Generic rules for validating attributes against complex types */
{attribute_unknown predicate (PV) 223}
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Generic rules for attribute validation (2L) 408 >
4.4.1.1. The type PurchaseOrderType
sva_atts_t_PurchaseOrderType(Lras,VRoot,Lpa,Lpna,Lerr) :- lras_t_PurchaseOrderType(VRoot,LpaAll,Lras,[]), LpaAll^^errors(Lerr0), partition(LpaAll,LpaPres,Lpna), attocc_t_PurchaseOrderType(LpaPres,Lpa,Lerr1), append(Lerr0, Lerr1, Lerr).
This code is not used elsewhere.
attocc_t_PurchaseOrderType(L,L,[]).
This code is not used elsewhere.
sva_atts_t_PurchaseOrderType(Lras,VRoot,Lpa,Lpna,Lerr) :- lras_t_PurchaseOrderType(VRoot,LpaAll,Lras,[]), LpaAll^^errors(Lerr), partition(LpaAll,Lpa,Lpna).Continued in <DCTG rules for purchase-order attributes (PV) 219>, <The orderDate attribute (PV) 220>, <The unknown attribute (PO) (PV) 222>
This code is used in < Attribute rules for complex types (PV) 214 >
lras_t_PurchaseOrderType(_VRoot) ::= []
{Grammatical attributes for empty attribute list (PV) 225}.
lras_t_PurchaseOrderType(VRoot) ::=
ras_t_PurchaseOrderType(VRoot)^^Pa,
lras_t_PurchaseOrderType(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_PurchaseOrderType(VRoot) ::=
ras_nsd(VRoot)^^Pa,
lras_t_PurchaseOrderType(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_PurchaseOrderType(VRoot) ::=
ras_xsi(VRoot)^^Pa,
lras_t_PurchaseOrderType(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
ras_t_PurchaseOrderType(VRoot) ::= [orderDate=Value],
{ sva_plf_t_xsd_date(Value,LF,_PN,Lerr) }
{Properties for orderDate attribute (PV) 221}.
<:> info_item(attribute)
&& local_name('orderDate')
&& namespace_name('')
&& normalized_value(Value)
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('date')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid) ::- Lerr = []
&& validity(invalid) ::- Lerr \= []
&& schema_error_code(Lerr)
&& schema_normalized_value(LF)
&& validation_context(VRoot)
&& errors([])
This code is used in < The orderDate attribute (PV) 220 > < DCTG rules for purchase-order attributes (2L) 399 >
ras_t_PurchaseOrderType(VRoot) ::= [Name=Value],
{ attribute_unknown(Name,[orderDate]) }
{Properties of unknown attributes (PV) 224}.
4.4.1.2. Some generic rules for attributes
attribute_unknown(Name,DeclaredAtts) :- not(member(Name,DeclaredAtts)), Name \= xmlns, Name \= xmlns:_Prefix, Name \= 'http://www.w3.org/2001/XMLSchema-instance':type, Name \= 'http://www.w3.org/2001/XMLSchema-instance':nil, Name \= 'http://www.w3.org/2001/XMLSchema-instance':schemaLocation, Name \= 'http://www.w3.org/2001/XMLSchema-instance':noNamespaceSchemaLocation.
This code is used in < Generic rules for attribute validation (PV) 215 >
<:> info_item(attribute)
&& local_name(Localname) ::- Name = _NSName:Localname
&& local_name(Name) ::- Name \= _NSName:Localname
&& namespace_name(NSName) ::- Name = NSName:_Localname
&& namespace_name('') ::- Name \= NSName:_Localname
&& normalized_value(Value)
&& schema_specified(infoset)
&& validation_attempted(none)
&& validity('notKnown')
&& schema_error_code([])
&& schema_normalized_value('')
&& validation_context(VRoot)
&& errors([error('cvc-assess-attr.1','undeclared attribute',
[attname(Name), attval(Value)])])
This code is used in < The unknown attribute (PO) (PV) 222 > < The unknown attribute (USAddress) (PV) 229 > < Attribute handling for Items type (PV) 230 > < PartNum attribute (PV) 232 > < Attribute handling for simple types (PV) 233 > < Generic attribute rules, cont'd (2L) 395 >
<:> attributes([]) && errors([])
This code is used in < DCTG rules for purchase-order attributes (PV) 219 > < Attribute rules for US address type (PV) 227 > < Attribute handling for Items type (PV) 230 > < Attribute handling for t_e_item_t_Items (PV) 231 > < Attribute handling for simple types (PV) 233 >
<:> attributes([Pa|L]) ::- Lpa^^attributes(L)
&& errors(Lerr) ::- Pa^^errors(Lerr0),
Lpa^^errors(Lerr1),
append(Lerr0, Lerr1, Lerr)
This code is used in < DCTG rules for purchase-order attributes (PV) 219 > < Attribute rules for US address type (PV) 227 > < Attribute handling for Items type (PV) 230 > < Attribute handling for t_e_item_t_Items (PV) 231 > < Attribute handling for simple types (PV) 233 > < Generic attribute rules, cont'd (2L) 394 >
4.4.1.3. The type USAddress
sva_atts_t_USAddress(Lras,VRoot,Lpa,Lpna,Lerr) :-
lras_t_USAddress(VRoot,LpaAll,Lras,[]),
LpaAll^^errors(Lerr0),
partition(LpaAll,LpaPres,Lpna),
attocc_t_USAddress(LpaPres,Lpa,Lerr1),
append(Lerr0, Lerr1, Lerr).
lras_t_USAddress(_VRoot) ::= []
{Grammatical attributes for empty attribute list (PV) 225}.
lras_t_USAddress(VRoot) ::=
ras_t_USAddress(VRoot)^^Pa,
lras_t_USAddress(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_USAddress(VRoot) ::=
ras_nsd(VRoot)^^Pa,
lras_t_USAddress(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_USAddress(VRoot) ::=
ras_xsi(VRoot)^^Pa,
lras_t_USAddress(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
ras_t_USAddress(VRoot) ::= [country=Value],
{ sva_plf_t_xsd_NMTOKEN(Value,LF,_PN,Lerr0),
(LF = ['U', 'S']
-> Lerr = Lerr0
; Lerr = [error('cvc-attribute.4','Value does not match fixed value',
[val(Value), lf(LF), fixed('US')]) | Lerr0]) }
<:> info_item(attribute)
&& local_name('country')
&& namespace_name('')
&& normalized_value('US')
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('NMTOKEN')
&& type_definition_type(simple)
&& schema_default('US')
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid) ::- Lerr = []
&& validity(invalid) ::- Lerr \= []
&& schema_error_code(Lerr)
&& schema_normalized_value(LF)
&& validation_context(VRoot)
&& errors([])
.
{The unknown attribute (USAddress) (PV) 229}
Continued in <Attribute occurrence checking for USAddress (PV) 228>This code is used in < Attribute rules for complex types (PV) 214 >
attocc_t_USAddress(LpaPres,LpaAll,Lerr) :-
CountryAtt = node(
attribute(country),
[],
[ (info_item(attribute)),
(namespace_name('')),
(local_name('country')),
(normalized_value('US')),
(type_definition_anonymous('false')),
(type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')),
(type_definition_name('NMTOKEN')),
(type_definition_type(simple)),
(schema_default('US')),
(schema_specified(schema)),
(validation_attempted(full)),
(validity(valid)),
(schema_error_code([])),
(schema_normalized_value(['U', 'S']))
]),
atts_defaulted(LpaPres,[CountryAtt],LpaAll,Lerr).
ras_t_USAddress(VRoot) ::= [Name=Value],
{ attribute_unknown(Name,[country]) }
{Properties of unknown attributes (PV) 224}.
This code is used in < Attribute rules for US address type (PV) 227 >
4.4.1.4. The type Items
sva_atts_t_Items(Lras,VRoot,Lpa,Lpna,Lerr) :-
lras_t_Items(VRoot,LpaAll,Lras,[]),
LpaAll^^errors(Lerr),
partition(LpaAll,Lpa,Lpna).
lras_t_Items(_VRoot) ::= []
{Grammatical attributes for empty attribute list (PV) 225}.
lras_t_Items(VRoot) ::=
ras_nsd(VRoot)^^Pa,
lras_t_Items(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_Items(VRoot) ::=
ras_xsi(VRoot)^^Pa,
lras_t_Items(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_Items(VRoot) ::=
ras_t_Items(VRoot)^^Pa,
lras_t_Items(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
ras_t_Items(VRoot) ::= [Name=Value],
{ attribute_unknown(Name,[]) }
{Properties of unknown attributes (PV) 224}.
This code is used in < Attribute rules for complex types (PV) 214 >
4.4.1.5. The type of the item element
sva_atts_t_e_item_t_Items(Lras,VRoot,Lpa,Lpna,Lerr) :-
lras_t_e_item_t_Items(VRoot,LpaAll,Lras,[]),
LpaAll^^errors(Lerr0),
partition(LpaAll,LpaPres,Lpna),
attocc_t_e_item_t_Items(LpaPres,Lpa,Lerr1),
append(Lerr0, Lerr1, Lerr).
lras_t_e_item_t_Items(_VRoot) ::= []
{Grammatical attributes for empty attribute list (PV) 225}.
lras_t_e_item_t_Items(VRoot) ::=
ras_t_e_item_t_Items(VRoot)^^Pa,
lras_t_e_item_t_Items(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_e_item_t_Items(VRoot) ::=
ras_nsd(VRoot)^^Pa,
lras_t_e_item_t_Items(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_t_e_item_t_Items(VRoot) ::=
ras_xsi(VRoot)^^Pa,
lras_t_e_item_t_Items(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
Continued in <PartNum attribute (PV) 232>This code is used in < Attribute rules for complex types (PV) 214 >
ras_t_e_item_t_Items(VRoot) ::= [partNum=Value],
{ sva_plf_t_SKU(Value,LF,_PN,Lerr) }
<:> info_item(attribute)
&& local_name('partNum')
&& namespace_name('')
&& normalized_value(Value)
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.example.com/PO1')
&& type_definition_name('SKU')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid) ::- Lerr = []
&& validity(invalid) ::- Lerr \= []
&& schema_error_code(Lerr)
&& schema_normalized_value(LF)
&& validation_context(VRoot)
&& errors([])
.
ras_t_e_item_t_Items(VRoot) ::= [Name=Value],
{ attribute_unknown(Name,[]) }
{Properties of unknown attributes (PV) 224}.
/* one required attribute: partNum */
attocc_t_e_item_t_Items(LpaPres,LpaAll,Lerr) :-
atts_present(LpaPres,['':partNum],Lerr0),
atts_absent(LpaPres,[],Lerr1),
atts_defaulted(LpaPres,[],LpaAll,Lerr2),
flatten([Lerr0,Lerr1,Lerr2],Lerr).
4.4.2. Attribute rules for simple types
sva_atts_simpletype(Lras,VRoot,Lpa,Lpna,Lerr) :-
lras_sT(VRoot,LpaAll,Lras,[]),
LpaAll^^errors(Lerr),
partition(LpaAll,Lpa,Lpna).
lras_sT(_VRoot) ::= []
{Grammatical attributes for empty attribute list (PV) 225}.
lras_sT(VRoot) ::=
ras_nsd(VRoot)^^Pa,
lras_sT(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_sT(VRoot) ::=
ras_xsi(VRoot)^^Pa,
lras_sT(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
lras_sT(VRoot) ::=
ras_sT(VRoot)^^Pa,
lras_sT(VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}.
ras_sT(VRoot) ::= [Name=Value],
{ attribute_unknown(Name,[]) }
{Properties of unknown attributes (PV) 224}.
This code is used in < DCTG for purchase order schema, partial-validation layer 94 >
4.4.3. PV rules for namespace declarations and xsi attributes
/* ras_nsd: grammatical rule for namespace-attribute
* specifications */
ras_nsd(_VRoot) ::= [xmlns=DefaultNS]
<:> info_item(attribute)
&& local_name(xmlns)
&& namespace_name('http://www.w3.org/2000/xmlns/')
&& normalized_value(DefaultNS)
&& prefix('##NONE')
&& namespace(DefaultNS)
&& errors([]).
ras_nsd(_VRoot) ::= [xmlns:Prefix=NSName]
<:> info_item(attribute)
&& local_name(Prefix)
&& namespace_name('http://www.w3.org/2000/xmlns/')
&& normalized_value(NSName)
&& prefix(Prefix)
&& namespace(NSName)
&& errors([]).
Continued in <Grammar rules for XSI attributes (PV) 235>This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
/* ras_xsi: grammar rule for XSI attribute specifications */
ras_xsi(VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':type=Value],
{ sva_plf_t_xsd_QName(Value,LF,_PN,Lerr) }
<:> local_name(type)
&& type_definition_name('QName')
&& type_definition_anonymous('false')
{Common properties for xsi attributes (PV) 236}
ras_xsi(VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':nil=Value],
{ sva_plf_t_xsd_boolean(Value,LF,_PN,Lerr) }
<:> local_name(nil)
&& type_definition_name('boolean')
&& type_definition_anonymous('false')
{Common properties for xsi attributes (PV) 236}
ras_xsi(VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':schemaLocation=Value],
{ sva_plf_t_xsd_list_anyURI(Value,LF,_PN,Lerr) }
<:> local_name(schemaLocation)
&& type_definition_name('t_a_schemaLocation')
&& type_definition_anonymous('true')
{Common properties for xsi attributes (PV) 236}
ras_xsi(VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':noNamespaceSchemaLocation=Value],
{ sva_plf_t_xsd_anyURI(Value,LF,_PN,Lerr) }
<:> local_name(noNamespaceSchemaLocation)
&& type_definition_name('QName')
&& type_definition_anonymous('false')
{Common properties for xsi attributes (PV) 236}
&& info_item(attribute)
&& namespace_name('http://www.w3.org/2001/XMLSchema-instance')
&& normalized_value(Value)
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid) ::- Lerr = []
&& validity(invalid) ::- Lerr \= []
&& schema_error_code(Lerr)
&& schema_normalized_value(LF)
&& validation_context(VRoot)
&& errors([])
.
This code is used in < Grammar rules for XSI attributes (PV) 235 > < Grammar rules for XSI attributes (2L) 397 >
4.4.4. Generic utilities for checking attributes
/* atts_present(Lpa,Lreq,Lerr): true if a parsed attribute node
* is present in Lpa for each attribute name in Lreq, with errors
* Lerr */
atts_present(_LRAS,[],[]).
atts_present(LRAS,[HRA|RequiredTail],Lerr) :-
att_present(LRAS,HRA,Lerr0),
atts_present(LRAS,RequiredTail,Lerr1),
append(Lerr0, Lerr1, Lerr).
/* An attribute name matches if namespace name and local
* name part match */
/* att_present(Lpa,Attname): true if a parsed attribute node
* is present in Lpa which has name Attname */
att_present([Pa|_Lpa],NS:NCName,[]) :-
Pa^^local_name(NCName),
Pa^^namespace_name(NS).
att_present([_Pa|Lpa],Attname,Lerr) :-
att_present(Lpa,Attname,Lerr).
/* base step: when we reach att_present([],Attname) we issue
* an error message. */
att_present([],Attname,
[error('cvc-complex-type.4','required attribute is missing',
[attname(Attname)])]).
Continued in <Utility for checking absent attributes (PV) 238>, <Utility for providing defaulted attributes (PV) 239>This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Utilities for checking attribute occurrences (2L) 409 >
/* atts_absent(Lpa,Ltabu): true if no attribute named in
* Ltabu is present in Lpa */
atts_absent(_LRAS,[],[]).
atts_absent(LRAS,[H|T],Lerr) :-
att_present(LRAS,H,[error('cvc-complex-type.4',_,_)]),
atts_absent(LRAS,T,Lerr).
atts_absent(LRAS,[H|T],
[error('cvc-complex-type.3','attribute not allowed',[attname(H)])|Lerr0]) :-
att_present(LRAS,H,[]),
atts_absent(LRAS,T,Lerr0).
/* atts_defaulted(L1,L2,L3,Lerr): true if L3 has all the
* attributes in L1, plus all of the attributes in L2 which
* are not also in L1, with any errors in Lerr. */
atts_defaulted(L1,L2,L3,Lerr) :-
( atts_defaulted(L1,L2,L3)
-> Lerr = []
; Lerr = [error('pv-atts-defaulted', 'error providing default values for attributes',
[lpa(L1), ldft(L2)])]).
{Utility for providing defaulted attributes 14}
4.5. Validation of complex content
4.5.1. Content-model rules
content_t_PurchaseOrderType(VRoot,Lnsb) ::=
e_shipTo_t_PurchaseOrderType(VRoot,Lnsb)^^S,
e_billTo_t_PurchaseOrderType(VRoot,Lnsb)^^B,
opt_e_comment(VRoot,Lnsb)^^C,
e_items_t_PurchaseOrderType(VRoot,Lnsb)^^I
{Children attribute of t_PurchaseOrder 36}
.
opt_e_comment(_VRoot,_Lnsb) ::= []
{Empty list of children for opt_e_comment nonterminal 34}
.
opt_e_comment(VRoot,Lnsb) ::= e_comment(VRoot,Lnsb)^^Comm
{Children for opt_e_comment nonterminal 35}
.
content_t_USAddress(VRoot,Lnsb) ::=
e_name_t_USAddress(VRoot,Lnsb)^^N,
e_street_t_USAddress(VRoot,Lnsb)^^S,
e_city_t_USAddress(VRoot,Lnsb)^^C,
e_state_t_USAddress(VRoot,Lnsb)^^ST,
e_zip_t_USAddress(VRoot,Lnsb)^^Z
{Children attribute of t_USAddress 33}
.
content_t_Items(VRoot,Lnsb) ::=
star_e_item_t_Items(VRoot,Lnsb)^^L
{Children attribute of content_t_Items 40}
.
star_e_item_t_Items(_VRoot,_Lnsb) ::= []
{Empty list of children for star_e_item_t_Items nonterminal 41}
.
star_e_item_t_Items(VRoot,Lnsb) ::=
e_item_t_Items(VRoot,Lnsb)^^I,
star_e_item_t_Items(VRoot,Lnsb)^^L
{Children for star_e_item_t_Items nonterminal 42}
.
content_t_e_item_t_Items(VRoot,Lnsb) ::=
e_productName_t_e_item_t_Items(VRoot,Lnsb)^^PN,
e_quantity_t_e_item_t_Items(VRoot,Lnsb)^^Q,
e_USPrice_t_e_item_t_Items(VRoot,Lnsb)^^USP,
opt_e_comment(VRoot,Lnsb)^^C,
opt_e_shipDate_t_e_item_t_Items(VRoot,Lnsb)^^S
{Children attribute of t_e_item_t_Items 37}
.
opt_e_shipDate_t_e_item_t_Items(_VRoot,_Lnsb) ::= []
{Empty list of children for opt_e_shipdate nonterminal 38}
.
opt_e_shipDate_t_e_item_t_Items(VRoot,Lnsb) ::=
e_shipDate_t_e_item_t_Items(VRoot,Lnsb)^^S
{Children for opt_e_shipdate nonterminal 39}
.
This code is used in < Complex-content rules (PV) 240 >
4.5.2. Succeeding on invalid content
sva_content_TYPEID(Lre,Lpe) :- content_TYPEID(Topnode,Lre,[]), Topnode ^^ children(Lpe).which simply fails if the sequence of children Lre is not legal according to the grammar. We need a fallback, something along the lines of:
sva_content_TYPEID(Lre,Lpe,Lerrors) :-
(content_TYPEID(Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; Lpe = Lre,
Lerrors = [error('cvc-elt.5.2.1',
'element not locally valid, failed type validation',
[])]).
i.e. try calling the grammar (content_TYPEID); if it
succeeds, extract the list of parsed-element children
(Lpe) and we're done; otherwise, bind
Lpe to the raw unparsed input, and provide an
appropriate list of errors.sva_content_TYPEID(Lre,Lpe,Lerrors) :-
(content_TYPEID(Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lre,Lpe,Lerrors0),
Lerrors = append([error('cvc-elt.5.2.1',
'element not locally valid, failed type validation',
[ type(TYPEID), ce([error('cvc-type.3.2',
'element not locally valid wrt complex type',
[ type(TYPEID), ce([error('cvc-complex-type.2.4',
'sequence of children does not match content model',
[ type(TYPEID), ce([])])])])])])],
Lerrors0,
Lerrors)).
Note that we can take this only so far. Our DCTG mechanisms do not
allow us a convenient way to identify the cause of a content-model
failure any more specifically, so we do not use any of the
cvc-particle or cvc-model-group error codes.sva_content_TYPEID(Lre,Lpe,Lerrors) :-
(content_TYPEID(Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lre,Lpe,Lerrors0),
content_seq_mixed(Lre,Ismixed),
(Ismixed = true
-> E = error('cvc-complex-type.2.3',
'mixed content in element-only element',
[ type(TYPEID), ce([])])
; E = error('cvc-complex-type.2.4',
'sequence of children does not match content model',
[ type(TYPEID), ce([])])),
Lerrors = append([error('cvc-elt.5.2.1',
'element not locally valid, failed type validation',
[ type(TYPEID), ce([error('cvc-type.3.2',
'element not locally valid wrt complex type',
[ type(TYPEID), ce([E])])])])],
Lerrors0,
Lerrors)).
The number of lines taken up by error identification seems
disproportionate; if we factor them out into a separate
predicate, we get something more plausible:
sva_content_TYPEID(Lre,Lpe,Lerrors) :-
(content_TYPEID(Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lre,Lpe,Lerrors0),
content_error(Lre,TYPEID,Lerrors1),
append(Lerrors0,Lerrors1,Lerrors)).
sva_content_TYPEID(VRoot,Lre,Lpe,Lerrors) :-
(content_TYPEID(VRoot,Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(VRoot,Lre,Lpe,Lerrors0),
content_error(Lre,TYPEID,Lerrors1),
append(Lerrors0,Lerrors1,Lerrors)).
content_error(Lre,TYPEID,Lerrors) :-
content_seq_mixed(Lre,Ismixed),
(Ismixed = true
-> E = error('cvc-complex-type.2.3',
'mixed content in element-only element',
[ type(TYPEID), ce([])])
; E = error('cvc-complex-type.2.4',
'sequence of children does not match content model',
[ type(TYPEID), ce([])])),
Lerrors = [error('cvc-elt.5.2.1',
'element not locally valid, failed type validation',
[ type(TYPEID), ce([error('cvc-type.3.2',
'element not locally valid wrt complex type',
[ type(TYPEID), ce([E])])])])].
Continued in <Checking child sequence for mixed content (PV) 243>This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Generic utilities for DCTG-encoded schemas (2L) 269 >
/* a content sequence is mixed if it contains any atom which * contains non-whitespace characters, or an entity() structure. * element() and pi() structures are OK. */ content_seq_mixed([],false). content_seq_mixed([entity(_)|_T],true). content_seq_mixed([H|T],Ismixed) :- atom(H), atom_chars(H,Lc), ws_normalize(collapse,Lc,Lnormalized,[]), (Lnormalized = [] -> content_seq_mixed(T,Ismixed) ; Ismixed = true). content_seq_mixed([H|T],Ismixed) :- not(atom(H)), H \= entity(_), content_seq_mixed(T,Ismixed).
sva_content_t_PurchaseOrderType(VRoot,Lnsb,Lre,Lpe,Lerrors) :-
(content_t_PurchaseOrderType(VRoot,Lnsb,Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lnsb,Lre,Lpe,Lerrors0),
content_error(Lre,t_PurchaseOrderType,Lerrors1),
append(Lerrors0,Lerrors1,Lerrors)).
sva_content_t_USAddress(VRoot,Lnsb,Lre,Lpe,Lerrors) :-
(content_t_USAddress(VRoot,Lnsb,Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lnsb,Lre,Lpe,Lerrors0),
content_error(Lre,t_USAddress,Lerrors1),
append(Lerrors0,Lerrors1,Lerrors)).
sva_content_t_Items(VRoot,Lnsb,Lre,Lpe,Lerrors) :-
(content_t_Items(VRoot,Lnsb,Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lnsb,Lre,Lpe,Lerrors0),
content_error(Lre,t_Items,Lerrors1),
append(Lerrors0,Lerrors1,Lerrors)).
sva_content_t_e_item_t_Items(VRoot,Lnsb,Lre,Lpe,Lerrors) :-
(content_t_e_item_t_Items(VRoot,Lnsb,Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lnsb,Lre,Lpe,Lerrors0),
content_error(Lre,t_e_item_t_Items,Lerrors1),
append(Lerrors0,Lerrors1,Lerrors)).
This code is used in < Complex-content rules (PV) 240 >
4.5.3. Simple fallback processing
/* content_skip(+Lnsb, +Lre, -Lpe, -Lerrors): * true iff Lpe is the list * of parsed elements corresponding the the raw list Lre, * with the errors noted in Lerrors. */ content_skip(Lnsb,Lre,Lpe,Lerrors) :- content_sequence(Lnsb,TopNode,Lre,[]), TopNode ^^ children(Lpe), TopNode ^^ errors(Lerrors).Continued in <The grammar rule content_sequence (PV) 246>, <The grammar rule infoitem (PV) 247>, <The name_parts predicate (for unparsed names) (PV) 248>
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 > < Generic utilities for DCTG-encoded schemas (2L) 269 >
content_sequence(_Lnsb) ::= []
<:> errors([])
&& children([]).
content_sequence(Lnsb) ::= infoitem(Lnsb)^^I, content_sequence(Lnsb)^^S
<:> errors(E) ::-
I^^errors(Ei),
S^^errors(Es),
append(Ei,Es,E)
&& children([I | Tail]) ::- S^^children(Tail).
infoitem(_Lnsb) ::= [Atom],
{ atom(Atom) }
<:> errors([])
&& children([Atom])
&& info_item(textnode).
/* or children(L) ::- atom_chars(Atom,L) ? */
infoitem(_Lnsb) ::= [entity(Arg)]
<:> errors([])
&& children([entity(Arg)])
&& info_item(textnode).
infoitem(_Lnsb) ::= [pi(Arg)]
<:> errors([])
&& children([pi(Arg)])
&& info_item(pi).
infoitem(Lnsb0) ::= [element(GI,Lras,Lre)],
{ inscope_namespaces(Lnsb0, Lras, Lnsb),
name_parts(GI,NsName,LocName),
content_skip(Lnsb,Lre,Lpe,Lerr),
atts_skip(Lnsb,Lras,Lpa,Lpna)
}
<:> errors(Lerr)
&& info_item(element)
&& attributes(Lpa)
&& namespace_attributes(Lpna)
&& children(Lpe)
&& local_name(LocName)
&& namespace_name(NsName)
&& validation_attempted(none)
&& validity(notKnown).
name_parts(NS:GI,NS,GI). name_parts(Name,'',Name) :- Name \= _NS:_GI.
atts_skip(Lnsb,Lras,Lpa,Lpna) :-
lras_skip(Lnsb,LpaAll,Lras,[]),
partition(LpaAll,Lpa,Lpna).
lras_skip(_Lnsb) ::= []
<:> attributes([]).
lras_skip(Lnsb) ::=
ras_skip(Lnsb)^^Pa,
lras_skip(Lnsb)^^Lpa
<:> attributes([Pa|L]) ::- Lpa^^attributes(L).
lras_skip(Lnsb) ::=
ras_nsd(Lnsb)^^Pa,
lras_skip(Lnsb)^^Lpa
<:> attributes([Pa|L]) ::- Lpa^^attributes(L).
ras_skip(_Lnsb) ::= [Attname=Attval],
{ Attname \= xmlns,
Attname \= xmlns:_Prefix,
name_parts(Attname,NS,Local)
}
<:> local_name(Local)
&& info_item(attribute)
&& namespace_name(NS)
&& normalized_value(Attval)
&& validation_attempted(none)
&& validity(notKnown)
.
This code is used in < Generic utilities for DCTG-encoded schemas (PV) 95 >
4.6. Miscellaneous
4.6.1. Starting schema-validity assessment
sva_po(Infoset,PSVI,Valid,Attempted) :-
/* find the root element in the infoset */
infoset_root(Infoset,Root),
/* invoke e_purchaseOrder with the root element as validation root
* and an empty set of namespace bindings. */
( e_purchaseOrder(Root,[ns('##NONE','')],PN,[Root],[])
-> (anoint_root(PN,PSVI),
PSVI^^validity(Valid),
PSVI^^validation_attempted(Attempted)
)
; /* if e_purchaseOrder fails, fall back to infoitem rule */
(infoitem([ns('##NONE','')],PN,[Root],[]),
anoint_root(PN,PSVI),
Valid = invalid,
Attempted = partial)).
Continued in <Schema-validity assessment on a file (PV) 251>This code is used in < [File load_pv.pl] 257 >
sva_po_file(File,PSVI,Valid,Attempted) :- /* open the file and make an infoset */ load_structure(File,Infoset,[dialect(xmlns),space(remove)]), sva_po(Infoset,PSVI,Valid,Attempted).
infoset_root([Root|_Epilog],Root) :- Root = element(_GI,_Atts,_Content). infoset_root([Prolog|Rest],Root) :- Prolog \= element(_GI,_Atts,_Content), infoset_root(Rest,Root).
This code is used in < [File load_pv.pl] 257 > < Initiating schema-validity assessment, generic (2L) 317 >
4.6.2. PSVI output in XML form
sva_po_psvi(Infoset,PSVI,Valid,Attempted) :- sva_po(Infoset,PSVI,Valid,Attempted), write_psvi(PSVI). sva_po_psvi_file(File,PSVI,Valid,Attempted) :- load_structure(File,Infoset,[dialect(xmlns),space(remove)]), sva_po(Infoset,PSVI,Valid,Attempted), make_psvi_filename(File,PFile), telling(Stdout), tell(PFile), write_psvi(PSVI), told, tell(Stdout), !.
This code is used in < [File load_pv.pl] 257 >
make_psvi_filename(File,PFile) :- file_base_name(File,Filename0), atom_concat(Stem,'.xml',Filename0), atom_concat(Stem,'.psvi.pv.xml',Filename1), absolute_file_name(po_out(Filename1),PFile).
This code is used in < [File load_pv.pl] 257 >
psvi_snf_errorcodes([]).
psvi_snf_errorcodes([error(Code,Desc,Details) | Lerr]) :-
write(Code),
write('('),
write(Desc),
( Details = []
-> true
; atom(Details) /* should never happen */
-> ( write(' :: NB pigs are flying! : '),
write(Details) )
; /* Details is a non-empty list */
( write(' :: '),
psvi_snf_errordetails(Details) )
),
write(')'),
psvi_snf_errorcodes(Lerr).
psvi_snf_errordetails([]).
psvi_snf_errordetails([H|T]) :-
H =.. [Name, Value],
( atomic(Value)
-> write(H)
; Value = []
-> write(H)
; Name = attname
-> write(H)
; member(Name,[atts,lpa,ldft])
/* These are complex, suppress them for now */
-> true
; Name = lf
-> write(H)
; Name = ce
-> ( write('ce('),
psvi_snf_ce(Value),
write(')')
)
),
write(' '),
psvi_snf_errordetails(T).
psvi_snf_ce([]) :-
write('[none]').
psvi_snf_ce([H|T]) :-
psvi_snf_errorcodes([H|T]).
psvi_snf_ce(Atom) :-
atom(Atom),
write(Atom).
psvi_snf([]) :- write('""').
psvi_snf([H|T]) :-
H = error(_Code,_Desc,_Details),
write('"'),
psvi_snf_errorcodes([H|T]),
write('"').
This code is used in < Writing out an attribute value in PSVI 68 >
psvi_schemainfo([]).
psvi_schemainfo([ns_triple(NS,Components,Docs)|Rest]) :-
psvi_schemainfo(ns_triple(NS,Components,Docs)),
psvi_schemainfo(Rest).
psvi_schemainfo([schema_document(EII,URI)|Rest]) :-
psvi_schemainfo(schema_document(EII,URI)),
psvi_schemainfo(Rest).
psvi_schemainfo(ns_triple(ns(NS),_Components,documents(Docs))) :-
write(NS), write(' from ('),
psvi_schemainfo(Docs),
write(') ').
psvi_schemainfo(schema_document(_EII,URI)) :-
write(URI), write(' ').
4.6.3. Convenience files for the PV grammar
4.6.3.1. The load_pv.pl program
/* load_pv.pl: load the PV DCTG grammar and other
* auxiliary material. */
{W3C copyright notice 86}
?- prolog_load_context(directory,Dir),
assert(file_search_path(po_bin,Dir)).
file_search_path(dctg,po_bin('..')).
file_search_path(po_tests,dctg('testdata/tests')).
file_search_path(po_out,dctg('testdata/tmp')).
file_search_path(po_lib,dctg('lib')).
?- ensure_loaded(po_lib('dctg_native.pl')).
?- ensure_loaded(po_bin('xsd_lib_pv.pl')).
?- ensure_loaded(po_bin('po_pv.pl')).
{Start schema-validity assessment (PV) 250}
{Calculate name for PSVI file (PV) 254}
{Start schema-validity assessment and dump PSVI (PV) 253}
{Find root element in infoset (PV) 252}
{Identify a parsed node as the validation root (PV) 208}
{Schema-information predicate (PV) 207}
4.6.3.2. The test_pv.pl program
/* test_pv.pl: run tests on the pv DCTG grammar */
{W3C copyright notice 86}
/* Consult this file, then run
*
* ?- run_tests.
*
* Use the predicates 'good', 'bad', 'ugly' to run valid, invalid, all.
* Use good(PSVI,Msglvl) etc. to control output:
* PSVI = psvi | nopsvi
* Msglvl = verbose | terse | silent
*/
?- prolog_load_context(directory,Dir),
assert(file_search_path(po_bin,Dir)).
?- ensure_loaded(po_bin('load_pv.pl')).
?- ensure_loaded(po_bin('coretests.pl')).
Continued in <Predicates to load and run test files (PV) 259>, <Error reports (PV) 266>, <Running all tests (PV) 267>
/* run_test(File,Flag,Msglvl): parse File, write psvi,
* check top-level output, report */
run_test(File,Flag,Msglvl) :-
{Report at start of test (PV) 260},
potestfile(File,ExpectedRC),
absolute_file_name(po_tests(File),Testfile),
(Flag = psvi
-> sva_po_psvi_file(Testfile,PSVI,Valid,Attempted)
; sva_po_file(Testfile,PSVI,Valid,Attempted)
),
report_rc(Msglvl,ExpectedRC,Valid,File,PSVI)
.
{Report at end of test (PV) 261}
( Msglvl = verbose
-> ( write('Testing '), writeq(File), write(': '), nl )
; ( Msglvl = terse
-> ( write('Testing '), writeq(File) )
; true ) )
This code is used in < Predicates to load and run test files (PV) 259 > < Running one test (2L) 412 >
/* report_rc: report the result appropriately */
{Report at end of test (verbose) (PV) 262}
{Report at end of test (terse) (PV) 263}
{Report at end of test ('silent' mode) (PV) 264}
This code is used in < Predicates to load and run test files (PV) 259 > < Running one test (2L) 412 >
report_rc(verbose,ExpectedRC,Valid,_File,PSVI) :-
write(' Expected result: '),
write(ExpectedRC), nl,
write(' Actual result: '),
write(Valid), nl,
( Valid = invalid
-> ( PSVI^^schema_error_code(Lerr)
-> error_report(verbose,Lerr)
; write('No schema error code') )
; true
).
This code is used in < Report at end of test (PV) 261 >
report_rc(terse,ExpectedRC,Valid,_File,PSVI) :-
write(' ('),
write(ExpectedRC),
write('): '),
write(Valid),
write(' '),
( Valid = invalid
-> ( PSVI^^schema_error_code(Lerr)
-> error_report(terse,Lerr)
; write('no schema error code') )
; true ),
( (Valid = notKnown, ExpectedRC = invalid)
-> true
; Valid \= ExpectedRC
-> write(' !! NOT OK !! result not as expected !!')
; true
),
nl.
This code is used in < Report at end of test (PV) 261 >
report_rc(silent,ExpectedRC,Valid,File,_PSVI) :-
( ExpectedRC = Valid
-> true
; (ExpectedRC = invalid, Valid = notKnown)
-> true
; write('!! NOT OK !! Error in file '),
writeq(File),
write(', expected '),
write(ExpectedRC),
write(', got '),
write(Valid)
).
This code is used in < Report at end of test (PV) 261 >
report(notKnown,invalid) :-
write('ok (expected invalid, got notKnown)'), nl.
report(notKnown,valid) :-
write('!!! NOT OK: expected valid, got invalid !!!'), nl.
report(valid,invalid) :-
write('!!! NOT OK: expected invalid, got valid !!!'), nl.
report(invalid,valid) :-
write('!!! NOT OK: expected valid, got invalid !!!'), nl.
This code is not used elsewhere.
error_report(_Msglvl,[]).
error_report(terse,[error(KW,Desc,_Details)|Lerr]) :-
write(KW),
write(' ('),
write(Desc),
write(')'),
(Lerr = [_|_]
-> write(', ')
; true),
error_report(terse,Lerr).
error_report(verbose,[error(KW,Desc,Details)|Lerr]) :-
write(' '),
write(KW),
write(': '),
write(Desc),
nl,
details_report(Details),
error_report(terse,Lerr).
details_report([]).
details_report([Item|Litems]) :-
write(' - '),
( Item = ce(Lerr)
-> ( write('Contributing error(s): '), nl,
error_report(verbose,Lerr),
write(' End contributing error(s).') )
; write(Item) ),
nl,
details_report(Litems).
This code is used in < [File test_2l.pl] 411 >
good :- good(nopsvi,terse). bad :- bad(nopsvi,terse). ugly :- ugly(nopsvi,terse). good(Option,Msglvl) :- run_tests(valid,Option,Msglvl). bad(Option,Msglvl) :- run_tests(invalid,Option,Msglvl). ugly(Option,Msglvl) :- run_tests(valid,Option,Msglvl), run_tests(invalid,Option,Msglvl). run_tests :- ugly. run_tests(RC,Option,Msglvl) :- bagof(File,potestfile(File,RC),Files), member(F,Files), run_test(F,Option,Msglvl), fail. run_tests(_RC,_Option,_Msglvl).
4.7. Evaluation
4.7.1. Problems, enhancements, correctness
- Numerous syntax errors not worth noting individually.
- Confusion about whether sva_content_TYPEID for simple types should take an atom as the pre-lexical form, or a list of atoms and entity structures. The testing code uses atoms, the sva_content_TYPEID predicates assume a list containing a single atom, which is true for many cases but won't be true if characters outside the Prolog range are used. For now, I've just made aelist_chars and aelist_codes accept an atom as well as a list.
- Failure of the PSVI dump routines from the core level to accommodate properties of attributes that take the form of rules rather than ground structures. I've added new code to detect rules; in the long run, though, I think I will prefer to put all the calculation into the main body of the grammar rule and use no rules in the grammatical attributes.
- Omission of provision for writing out schema error codes satisfactorily. In a later grammar we'll add routines to take the existing error structures and turn them into more human-readable error messages.
- Discrepancy between core and PV grammars over whether the schema_specified property of the country attribute on addresses should have the value “schema” (so the core grammar) or “infoset” (so PV).
- Two valid documents were reported as invalid, with the following
schema error code:
- (in po1v10a) cvc-elt.4.2(xsi:type failed to resolve :: element(e_purchaseOrder) localtype(apo:PurchaseOrderType) ce(sva_xsitype_resolve did not return) )
- (in po1v38) cvc-elt.4.2(xsi:type failed to resolve :: element(e_billTo_t_PurchaseOrderType) localtype(apo:USAddress) ce(sva_xsitype_resolve did not return) )
- Once the preceding xsi:type issue was resolved, the core and PV parsers differ in their treatment of the xsi:type attribute in po1v38.
- Erroneous invocation of fallback processing in sva_po: called content_skip on Infoset instead of infoitem on [Root]. Fixed.
- Errors in namespace prefix handling visible in po1e04.xml.
- Routines for writing PSVI assumed existence of type_definition_name and similar properties not present in skipped content.
- Error in write_psvi routines: failed to distinguish elements from text nodes.
- Dump inscope-namespaces.
- Provide convenient mechanism for passing options to top-level sva; use the method shown by [O'Keefe 1990] which supports a list of option terms as the last argument.
4.7.2. Timings
for f in $TESTDIR/po1*.xml; do
echo $f;
pl -f $TESTPROG -g "run_test('${f#*po/tests/}',nopsvi)" -t halt;
done > temp.dcgtests.stdout 2> temp.dcgtests.stderr
where in my current setup I have
TESTDIR=/mnt/pidgin/usr/lib/xmlschema/po/tests TESTPROG=~/2004/schema/dctg/Prolog/test_core.plBoth standard output and error output are directed to files, because experiment shows that sending them to the console imposes an overhead of about 100ms per instance document.
time bash runtests.sh corewhere the argument to runtests.sh identifies the loop to be run.
4.7.2.1. How fast is validation?
| Grammar | Collection | Per document |
|---|---|---|
| PV | 17.927s | 239ms |
| Core | 11.614s | 154ms |
| DCG | 8.48 | 113ms |
4.7.2.2. How much does it cost to write out the results?
4.7.2.3. How much does it cost to launch Prolog and load the grammar?
| Grammar | Collection (singly) | Per document | Collection (from Prolog) | Per document |
|---|---|---|---|---|
| PV | 17.927s | 239ms | 1.481s | 20ms |
| Core | 11.614s | 154ms | 0.614s | 8ms |
| DCG | 8.48 | 113ms | 0.304s | 4ms |
4.7.2.4. Does running the timing tests in a shell script matter?
4.7.2.5. Details
time bash ../Prolog/runtests.sh $g all diskthe mean results were as follows.
| Grammar | Type | time bash runtests.sh ... | time pl ... |
|---|---|---|---|
| DCG | user | 270ms | 255ms |
| DCG | elapsed | 304ms | 369ms |
| Core | user | 562ms | 548ms |
| Core | elapsed | 614ms | 683ms |
| PV | user | 1422ms | 1418ms |
| PV | elapsed | 1481ms | 1562ms |
- user time: 270ms (min 0.23s, max 0.29s)
- system time: 24ms (min 0.00s, max 0.07s)
- elapsed time: 304ms (min 0.29ms, max 00.33s)
time pl -f ../Prolog/dcgtests.pl -g "ugly(dcg)" -t haltthe mean timing results were:
- compile podcg3n.pl: ca 10 ms
- compile dcgtests.pl: ca 3 ms (too low to measure accurately)
- user time: 255 ms (min 0.24s, max .28s)
- system time: 15 ms (min 0.00s, max .03s)
- elapsed time: 369 ms (min 0.33s, max .38s)
- user time: 321 ms (min 0.28s, max .35s)
- system time: 26 ms (min 0.01s, max .05s)
- elapsed time: 745 ms (min 0.59s, max .92)
- user time: 562ms (min 0.53s, max 0.58s)
- system time: 32ms (min 0.01s, max 0.07s)
- elapsed time: 614ms (min 0.60ms, max 00.63s)
time pl -f ../Prolog/test_core.pl -g "ugly" -t haltgave the following means:
- compile msmdctg.pl: ca 5 ms
- compile xsd_lib_core.pl: ca 11 ms
- compile coretests.pl: ca 5 ms
- compile load_core.pl: ca 83 ms
- compile test_core.pl: ca 90 ms
- user time: 548ms (min 0.53s, max 0.59s)
- system time: 18ms (min 0.00s, max 0.04s)
- elapsed time: 683ms (min 00.66s, max 00.72s)
- user time: 1422ms (min 1.40s, max 1.45s)
- system time: 33ms (min 0.01s, max 0.06s)
- elapsed time: 1481ms (min 1.47s, max 1.50s)
time pl -f ../Prolog/test_pv.pl -g "ugly" -t haltthese:
- compile po_pv.pl: 40 ms (min 0.03s, max 0.05s)
- compile dctg_native.pl: ca 6ms (min 0.00s, max 0.01s)
- compile xsd_lib_pv.pl: 90ms (min 0.08s, max 0.10s)
- compile coretests.pl: ca 4ms (min 0.00s, max 0.01s)
- compile load_pv.pl: 140ms (min 0.12s, max 0.16s)
- compile test_pv.pl: 150ms (min 0.13s, max 0.17s)
- user time: 1418ms (min 1.39s, max 1.45s)
- system time: 20ms (min 0.00s, max 0.04s)
- elapsed time: 1562ms (min 01.55s max 01.60s)
5. Reification of schema components and the second-level interpreter
- Reify the most important component sorts.
- Reduce the redundancy of the grammar. Previous layers of the schema have had several predicates for each element declaration and each type definition, which have been virtually identical except that the unique identifier of the element or type has been inserted at various places into the basic skeleton. Rewrite these rules to make them capture the common processes of validation better, and use the names of elements and types as parameters.
- Formulate the translation of the purchase-order schema in such a way as to make it easier to combine it with another schema. For the moment, this means simply adding some indirection at some points rather than assuming that we already know exactly which type will be associated with each element in an instance.
5.1. Overview
5.1.1. Structure
 Figure 3: Abstract call graph for the 2L layer
Figure 3: Abstract call graph for the 2L layer
/* po_2l.pl: a definite-clause translation grammar
* representation of the sample purchase-order schema from
* the XML Schema tutorial.
* This is version 2L, which does partial validation.
*
* This DCTG was generated by a literate programming
* system; if maintenance is necessary, make changes
* to the source (podctg.xml) not to this output file.
*/
{W3C copyright notice 86}
/* no module directive, at least for now. */
:- multifile
simpletype/6.
/* 1 Initiating schema-validity assessment (po-specific) */
{Initiating schema-validity assessment, po-specific (2L) 318}
/* 2 single-element rules: e_ELEMID rules
* have been replaced by generic element() rule.
*/
/* 3 validating elements against their element declarations */
{Rules for validating against element declarations (2L) 350}
/* element declarations */
{Validating elements against element declarations (2L) 345}
{Element declarations in purchase-order schema (2L) 271}
/* 4 simple-type rules:
* sva_content(TYPEID,...), sva_plf(TYPEID,...), value checks */
{Checking (pre-)lexical forms against schema-specific types (2L) 375}
{Simple type definitions in purchase-order schema (2L) 288}
/* 5 content-model rules:
* sva_content(TYPEID), content(TYPEID) */
{Complex-content rules (2L) 391}
{Simple-type content rules for purchase-order types (2L) 359}
{Complex types for PO schema (2L) 309}
/* 6 attribute-list rules:
* sva_atts_TYPEID, lras_TYPEID, ras_TYPEID */
{Attribute rules for complex types (2L) 406}
{Attribute handling for simple types (2L) 407}
/* xsd_lib_2l.pl: library routines not specific to any one schema.
* This is version 2L, which reifies the schema components and uses
* a second-level interpreter.
*
* This code was generated by a literate programming system; if
* maintenance is necessary, make changes to the source (podctg.xml)
* not to this output file.
*/
{W3C copyright notice 86}
/* This list of exports seems long; it should
* probably be trimmed later, after more of 2L
* is finished. */
/* At the moment, it's more trouble than it's worth.
* Suppress it.
:- module(xsd_lib_2l,
[aelist_chars/3,
anoint_root/2,
attribute_unknown/2,
atts_absent/3,
atts_defaulted/4,
atts_present/3,
calc_validation_attempted/3,
calc_validity/6,
content_error/3,
content_skip/4,
default_sva_options/1,
digit/3,
digits/3,
hyphen/3,
in_infoset/3,
infoset_root/2,
inscope_namespaces/3,
option_value/3,
partition/3,
ras_nsd/4,
ras_xsi/4,
report_results/4,
set_sva_options/3,
sva_content_t_xsd_date/3,
sva_content_t_xsd_decimal/3,
sva_content_t_xsd_string/3,
sva_plf_t_xsd_date/4,
sva_plf_t_xsd_NMTOKEN/4,
sva_xsitype/4,
ws_normalize/4
]).
*/
:- multifile
simpletype/6.
:- multifile
type_value/3.
:- multifile
sva_type_content/6.
:- dynamic
sevastopol_global_option/2.
/* 1 Initiating schema-validity assessment (generic) */
{Initiating schema-validity assessment, generic (2L) 317}
/* Ugly hack, please forgive. I'll clean it up eventually. */
sevastopol_global_option(xsitype_fallback,true).
/* 2 Utilities for validation against element declarations */
/* Overall validation of an element */
{Validating an element (2L) 343}
/* Matching GI against element declaration */
{Matching elements against element declarations (2L) 344}
/* Maintaining in-scope namespaces property */
{Calculating in-scope namespaces (2L) 351}
/* Rules for checking xsi:type */
{Check value given in xsi:type (2L) 352}
{xsi:type fallback to declared type (2L) 349}
{The type_base relation (2L) 357}
/* Checking type derivations (incomplete implementation) */
{Checking type derivations (2L) 353}
/* Resolving QNames and finding types from element names */
{Resolve QName to type (2L) 354}
{Expand Qname to expanded name triple (2L) 355}
/* Rules for calculating validity of elements */
{Calculating validation-attempted property (2L) 356}
/* Consulting properties of element declarations */
{Extract properties from element declarations (2L) 287}
/* 3 Utilities for working with simple types and
* their values */
{Generic predicates for simple types (2L) 376}
{Built-in simple type definitions (2L) 289}
/* Rules for checking pre-lexical form of builtin types */
{Checking pre-lexical forms against built-in types (2L) 360}
/* DCTG rules for built-in simple types */
{Grammar rules for lexical forms of built-in types (2L) 374}
/* Rules for simple content */
{sva_content rules for built-in types (2L) 358}
/* 4 Utilities for working with complex content */
/* Rules for mixed content. The same as in PV. */
{Distinguishing mixed-content error from child-sequence error (PV) 242}
{The content_skip predicate (PV) 245}
{The grammar rule atts_skip (PV) 398}
/* 5 Utilities for working with attributes */
/* Generic rules for validating attributes */
{Generic rules for attribute validation (2L) 408}
/* Rules for attribute occurrence checking */
{Utilities for checking attribute occurrences (2L) 409}
/* Rules for xsi attributes and namespace declarations */
{Grammar rules for namespace and XSI attributes (2L) 396}
/* 6 Other utilities */
/* writing out the PSVI */
{Top-level predicate for writing PSVI 60}
/* Consulting properties of types */
{Extract properties from type definitions (2L) 315}
5.1.2. Naming and argument conventions
- element(+Elemdecl, +VRoot, +NSBindings): DCTG rule for validating one element against a given declaration and recursively validating children and attributes.
- sva_elemdecl_eii(+Element_declaration, +Element_info_item, +NSBindings, -TypeID, -RC) for checking an element information item against an element declaration and finding its type node and a list of errors
- sva_type_atts(+TypeID, +VRoot, -List_of_parsed_attribute_nodes, -List_of_parsed_nsdecl_nodes, -RC) for schema-validity assessment of an element information item against a type definition, resulting in lists of parsed attributes and namespace declarations and a list of errors
- sva_type_plf(+Simple_TYPEID, +Pre_lexical_form, -Lexical_form, -Parsed_node, -RC) for assessment of the validity of a lexical form with respect to a simple type, resulting in a keyword summary of the result and a list of errors
- sva_type_content(+TYPEID, +VRoot, +Lnsb, -Parsed_node, +-Lre, --Lpe): predicate true iff Lre is a list of raw items in Anjewierden/Wielemaker form, which when validated against complex type TYPEID yields Lpe (a list of parsed element and PCDATA nodes). Any errors are in the errors property on Parsed_node.
- element(ELEMID): parses one occurrence of the element type in question, producing parsed element node.
- content(TYPEID): parses the content of an element of type TYPEID; the rule is a translation of the content model and produces a list of parsed nodes.
- lras(TYPEID): a list of attributes legal for type TYPEID.
- ras(TYPEID): a single attribute legal for type TYPEID.
- ras(nsd): a single namespace attribute.
- ras(xsi): a single attribute in the XSI namespace.
- lexform(TYPEID): lexical form for type TYPEID.
5.2. Reification of major component types
- a unique identifier for the component,[20]
- its schema-component designator as defined in [Holstege/Vedamuthu 2003] (this is not currently used anywhere, but it's handy for navigation)
- its local name
- its target namespace
- whether it is global or local
- a list of properties, represented using the same list technique as is used to represent grammatical attributes in the DCTG, so the ^^ operator can be used to extract the property values. In this example, the properties are in fact all literals, but we could use the ::- pseudo-neck operator to specify a rule, if we needed to.In addition to the properties defined by the spec, a few additional properties (id, scd) are also specified. The ID and SCD thus occur twice in each fact: as fixed-position arguments for ease in lookup, and in the property list (so the property list can be passed around as a variable when necessary, without it being necessary to re-consult the fact from which it was derived).
5.2.1. Reifying element declarations
5.2.1.1. Pattern for element declarations
elemdecl(ELEMID, SCD,
Local_name, Target_namespace,
Scope, [
(id(ELEMID)),
(scd(SCD)),
(name(Local_name)),
(target_namespace(Target_namespace)),
(type_definition(TYPEID)),
(scope(keyword(Scope))),
(value_constraint(Value_constraint_or_absent)),
(nillable(Boolean)),
(identity_constraint_definitions(List_ID_constraints)),
(substitution_group_affiliation(List_subst_group)),
(disallowed_substitutions(List_Disallowed_subs)),
(substitution_group_exclusions(List_SubGroup_exclusions)),
(abstract(Boolean)),
(annotation(Infoset_or_absent))
]).
elemdecl(e_purchaseOrder, '/element(purchaseOrder)',
purchaseOrder, 'http://www.example.com/PO1',
global, [
(id(e_purchaseOrder)),
(scd('/element(po:purchaseOrder)')),
(name(purchaseOrder)),
(target_namespace('http://www.example.com/PO1')),
(type_definition(t_PurchaseOrderType)),
(scope(keyword(global))),
(value_constraint(keyword(absent))),
(nillable(false)),
(identity_constraint_definitions([])),
(substitution_group_affiliation(keyword(absent))),
(disallowed_substitutions([])),
(substitution_group_exclusions([])),
(abstract(false)),
(annotation(keyword(absent)))
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
- An NCName is represented by an atom. This suffices for the purchase-order schema, but a general schema processor will need to use a list of atoms and entity structures or some other structure.
- A namespace name is represented by an atom (which happens, when viewed as a string, to be a URI).
- An absent value is represented by the structure keyword(absent).
- A type definition is represented by the atom used as its unique identifier in this Prolog representation.
- The special values global, default, fixed are represented as structures: keyword(global), etc.
- Boolean values are represented by the atoms true and false.
- Sets are represented as lists; the empty set is represented by [].
- An element declaration is represented by the atom used as its unique identifier in this Prolog representation.
- An identity constraint definition is represented by the atom used as its unique identifier in this Prolog representation. There are none in the purchase order schema.
- The keywords extension, restriction, substitution are represented by Prolog atoms spelled the same way.
- Annotations are represented by copying the SWI Prolog representation. There are none in the purchase order schema.
5.2.1.2. Declarations for the elements of the purchase-order schema
{Element declaration: purchaseOrder (2L) 270}
{Element declaration: comment (2L) 273}
{Element declaration: shipTo (2L) 274}
{Element declaration: billTo (2L) 275}
{Element declaration: items (2L) 276}
{Element declaration: name (2L) 277}
{Element declaration: street (2L) 278}
{Element declaration: city (2L) 279}
{Element declaration: state (2L) 280}
{Element declaration: zip (2L) 281}
{Element declaration: item (2L) 282}
{Element declaration: productName (2L) 283}
{Element declaration: quantity (2L) 284}
{Element declaration: USPrice (2L) 285}
{Element declaration: shipDate (2L) 286}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
(value_constraint(keyword(absent))),
(nillable(false)),
(identity_constraint_definitions([])),
(substitution_group_affiliation(keyword(absent))),
(disallowed_substitutions([])),
(substitution_group_exclusions([])),
(abstract(false)),
(annotation(keyword(absent)))
This code is used in < Element declaration: comment (2L) 273 > < Element declaration: shipTo (2L) 274 > < Element declaration: billTo (2L) 275 > < Element declaration: items (2L) 276 > < Element declaration: name (2L) 277 > < Element declaration: street (2L) 278 > < Element declaration: city (2L) 279 > < Element declaration: state (2L) 280 > < Element declaration: zip (2L) 281 > < Element declaration: item (2L) 282 > < Element declaration: productName (2L) 283 > < Element declaration: quantity (2L) 284 > < Element declaration: USPrice (2L) 285 > < Element declaration: shipDate (2L) 286 >
elemdecl(e_comment, '/element(comment)',
comment, 'http://www.example.com/PO1',
global, [
(id(e_comment)),
(scd('/element(po:comment)')),
(target_namespace('http://www.example.com/PO1')),
(name(comment)),
(type_definition(t_xsd_string)),
(scope(keyword(global))),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_shipTo_t_PurchaseOrderType,
'/complexType(po:PurchaseOrderType)/sequence()/element(shipTo)',
shipTo, '',
local, [
(id(e_shipTo_t_PurchaseOrderType)),
(scd('/complexType(po:PurchaseOrderType)/sequence()/element(shipTo)')),
(name(shipTo)),
(target_namespace('')),
(type_definition(t_USAddress)),
(scope(t_PurchaseOrderType)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_billTo_t_PurchaseOrderType,
'/complexType(po:PurchaseOrderType)/sequence()/element(billTo)',
billTo, '',
local, [
(id(e_billTo_t_PurchaseOrderType)),
(scd('/complexType(po:PurchaseOrderType)/sequence()/element(billTo)')),
(name(billTo)),
(target_namespace('')),
(type_definition(t_USAddress)),
(scope(t_PurchaseOrderType)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_items_t_PurchaseOrderType,
'/complexType(po:PurchaseOrderType)/sequence()/element(items)',
items, '',
local, [
(id(e_items_t_PurchaseOrderType)),
(scd('/complexType(po:PurchaseOrderType)/sequence()/element(items)')),
(name(items)),
(target_namespace('')),
(type_definition(t_Items)),
(scope(t_PurchaseOrderType)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_name_t_USAddress,
'/complexType(po:USAddress)/sequence()/element(name)',
name, '',
local, [
(id(e_name_t_USAddress)),
(scd('/complexType(po:USAddress)/sequence()/element(name)')),
(name(name)),
(target_namespace('')),
(type_definition(t_xsd_string)),
(scope(t_USAddress)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_street_t_USAddress,
'/complexType(po:USAddress)/sequence()/element(street)',
street, '',
local, [
(id(e_street_t_USAddress)),
(scd('/complexType(po:USAddress)/sequence()/element(street)')),
(name(street)),
(target_namespace('')),
(type_definition(t_xsd_string)),
(scope(t_USAddress)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_city_t_USAddress,
'/complexType(po:USAddress)/sequence()/element(city)',
city, '',
local, [
(id(e_city_t_USAddress)),
(scd('/complexType(po:USAddress)/sequence()/element(city)')),
(name(city)),
(target_namespace('')),
(type_definition(t_xsd_string)),
(scope(t_USAddress)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_state_t_USAddress,
'/complexType(po:USAddress)/sequence()/element(state)',
state, '',
local, [
(id(e_state_t_USAddress)),
(scd('/complexType(po:USAddress)/sequence()/element(state)')),
(name(state)),
(target_namespace('')),
(type_definition(t_xsd_string)),
(scope(t_USAddress)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_zip_t_USAddress,
'/complexType(po:USAddress)/sequence()/element(zip)',
zip, '',
local, [
(id(e_zip_t_USAddress)),
(scd('/complexType(po:USAddress)/sequence()/element(zip)')),
(name(zip)),
(target_namespace('')),
(type_definition(t_xsd_decimal)),
(scope(t_USAddress)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)',
item, '',
local, [
(id(e_item_t_Items)),
(scd('/complexType(po:Items)/sequence()/element(item)')),
(name(item)),
(target_namespace('')),
(type_definition(t_e_item_t_Items)),
(scope(t_Items)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_productName_t_e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(productName)',
productName, '',
local, [
(id(e_productName_t_e_item_t_Items)),
(scd('/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(productName)')),
(name(productName)),
(target_namespace('')),
(type_definition(t_xsd_string)),
(scope(t_e_item_t_Items)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_quantity_t_e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(quantity)',
quantity, '',
local, [
(id(e_quantity_t_e_item_t_Items)),
(scd('/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(quantity)')),
(name(quantity)),
(target_namespace('')),
(type_definition(t_e_quantity_t_e_item_t_Items)),
(scope(t_e_item_t_Items)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_USPrice_t_e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(USPrice)',
'USPrice', '',
local, [
(id(e_USPrice_t_e_item_t_Items)),
(scd('/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(USPrice)')),
(name('USPrice')),
(target_namespace('')),
(type_definition(t_xsd_decimal)),
(scope(t_e_item_t_Items)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
elemdecl(e_shipDate_t_e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(shipDate)',
shipDate, '',
local, [
(id(e_shipDate_t_e_item_t_Items)),
(scd('/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(shipDate)')),
(name(shipDate)),
(target_namespace('')),
(type_definition(t_xsd_date)),
(scope(t_e_item_t_Items)),
{Common properties (2L) 272}
]).
This code is used in < Element declarations in purchase-order schema (2L) 271 >
5.2.1.3. Extracting properties of element declarations
elemdecl_property(scd,ED,SCD) :-
elemdecl(ED, SCD, _LN, _NS, _Level, _Properties).
elemdecl_property(namespace, ED, NS) :-
elemdecl(ED, _SCD, _LN, NS, _Level, _Properties).
elemdecl_property(local_name,ED,LN) :-
elemdecl(ED, _SCD, LN, _NS, _Level, _Properties).
elemdecl_property(level,ED,SCD) :-
elemdecl(ED, SCD, _LN, _NS, _Level, _Properties).
elemdecl_property(Prop,ED,Val) :-
Prop \= scd,
Prop \= local_name,
Prop \= namespace,
Prop \= level,
elemdecl(ED, _SCD, _LN, _NS, _Level, Properties),
Att =.. [Prop, Val],
Properties ^^ Att.
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.2.2. Reifying simple type definitions
5.2.2.1. Simple type definition pattern
simpletype(TypeID,
SCD,
TypeName, TargetNS, LocalGlobal [
(id(TypeID)),
(scd(SCD)),
(anonymous(true|false)),
(name(TypeName)),
(target_namespace(TargetNS)),
(variety( atomic|list|union )),
(primitive_type_definition( TypeID_P )),
(item_type_definition( TypeID_I )),
(member_type_definitions([ TypeID_M, TypeID_M2, ... ])),
(facets(ListOfFacets)),
(fundamental_facets(ListOfFundamentals)),
(base_type_definition(t_xsd_anySimpleType)),
(final([restriction, list, union])),
(annotation(keyword(absent)))
]).
length(value(V), fixed(Bool), annotation()),
minLength(value(V), fixed(Bool), annotation()),
maxLength(value(V), fixed(Bool), annotation()),
pattern(value(V), annotation(), dctg_rule()),
enumeration(value([Vs]), annotation()),
whiteSpace(
value(preserve|replace|collapse),
fixed(Bool),
annotation()),
maxInclusive(value(V), fixed(Bool), annotation()),
maxExclusive(value(V), fixed(Bool), annotation()),
minInclusive(value(V), fixed(Bool), annotation()),
minExclusive(value(V), fixed(Bool), annotation()),
totalDigits(value(V), fixed(Bool), annotation()),
fractionDigits(value(V), fixed(Bool), annotation())
ordered(false|partial|total), bounded(true|false), cardinality(finite|countable), numeric(true|false)
5.2.2.2. Specific simple type definitions
{Simple type: SKU (2L) 297}
{Simple type for quantities (2L) 302}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
{Simple type: anySimpleType (2L) 290}
{Simple type: string (2L) 293}
{Simple type: normalizedString (2L) 294}
{Simple type: token (2L) 295}
{Simple type: NMTOKEN (2L) 296}
{Simple type: decimal (2L) 298}
{Simple type: integer (2L) 299}
{Simple type: non-negative integer (2L) 300}
{Simple type: positive integer (2L) 301}
{Simple type: date (2L) 303}
{Simple type: integer (2L) 299}
{Simple type definition for QName (2L) 304}
{Simple type definitions for anyURI and list of anyURI (2L) 305}
{Simple type definition for boolean (2L) 306}
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.2.2.3. anySimpleType
simpletype(t_xsd_anySimpleType,
'simpleType(anySimpleType)',
anySimpleType, 'http://www.w3.org/2001/XMLSchema',
global, [
(id(t_xsd_anySimpleType)),
(scd('simpleType(xsd:anySimpleType)')),
(anonymous(true)),
(name(anySimpleType)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(base_type_definition(t_xsd_anyType)),
(facets([])),
(final([])),
(variety(keyword(absent))),
(primitive_type_definition(keyword(absent))),
(item_type_definition(keyword(absent))),
(member_type_definitions(keyword(absent))),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
complextype(t_xsd_anyType,
'/complexType(xsd:anyType)',
'anyType', 'http://www.w3.org/2001/XMLSchema',
global, [
(id(t_xsd_anyType)),
(scd('/complexType(xsd:anyType)')),
(anonymous(false)),
(name('anyType')),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(base_type_definition(keyword(absent))),
/* perhaps the base type definition should be t_xsd_anyType */
(derivation_method(keyword(absent))),
(final([])),
(abstract(false)),
(attribute_uses([
au(required(false),
attdecl(a_xsd_anyType_),
value_constraint(keyword(absent)))
])),
(attribute_wildcard(keyword(absent))),
(content_type(c_model(content_t_xsd_anyType,mixed))),
(prohibited_substitutions([])),
(annotations(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
attdecl(a_xsd_anyType_,
'/complexType(xsd:anyType)/anyAttribute()',
'keyword(any)', 'http://www.w3.org/2001/XMLSchema',
local, [
(name(partNum)),
(target_namespace('http://www.example.com/PO1')),
(type_definition(t_SKU)),
(scope(t_e_item_t_Items)),
(value_constraint(keyword(absent))),
(annotation(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
5.2.2.4. String
simpletype(t_xsd_string,
'/simpleType(xsd:string)',
string, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_string)),
(scd('/simpleType(xsd:string)')),
(anonymous(false)),
(name(string)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition( t_xsd_string )),
(item_type_definition( keyword(absent) )),
(member_type_definitions([])),
(facets([
whiteSpace(value(preserve),
fixed(false),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_anySimpleType)),
(final([])),
(annotation(keyword(absent)))
/* This is not true: like all builtins, string does have
* annotation in the schema for schemas. But I don't have
* any particular use for it, so I'm omitting it for now. */
]).
This code is used in < Built-in simple type definitions (2L) 289 >
5.2.2.5. NMTOKEN
simpletype(t_xsd_normalizedString,
'/simpleType(xsd:normalizedString)',
normalizedString, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_normalizedString)),
(scd('/simpleType(xsd:normalizedString)')),
(anonymous(false)),
(name(normalizedString)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition( t_xsd_string )),
(item_type_definition( keyword(absent) )),
(member_type_definitions([])),
(facets([
whiteSpace(value(replace),
fixed(false),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_string)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
simpletype(t_xsd_token,
'/simpleType(xsd:token)',
token, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_token)),
(scd('/simpleType(xsd:token)')),
(anonymous(false)),
(name(token)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition( t_xsd_string )),
(item_type_definition( keyword(absent) )),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(false),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_normalizedString)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
simpletype(t_xsd_NMTOKEN,
'/simpleType(xsd:NMTOKEN)',
'NMTOKEN', 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_NMTOKEN)),
(scd('/simpleType(xsd:NMTOKEN)')),
(anonymous(false)),
(name('NMTOKEN')),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition( t_xsd_string )),
(item_type_definition( keyword(absent) )),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(false),
annotation(keyword(absent))),
pattern(value('\c+'), annotation(keyword(absent)),
dctg_rule(t_xsd_string))
/* actually, the pattern does have annotation, but I have
* no use for it at the moment */
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_token)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
5.2.2.6. SKU
simpletype(t_SKU,
'simpleType(po:SKU)',
'SKU', 'http://www.example.com/PO1', global, [
(id(t_SKU)),
(scd('simpleType(po:SKU)')),
(anonymous(false)),
(name('SKU')),
(target_namespace('http://www.example.com/PO1')),
(variety(atomic)),
(primitive_type_definition(t_xsd_string)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(preserve),
fixed(false),
annotation(keyword(absent))),
pattern(value('\d{3}-[A-Z]{2}'), annotation(keyword(absent)),
dctg_rule(t_SKU))
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_string)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Simple type definitions in purchase-order schema (2L) 288 >
5.2.2.7. Decimal
simpletype(t_xsd_decimal,
'simpleType(xsd:decimal)',
decimal, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_decimal)),
(scd('simpleType(xsd:decimal)')),
(anonymous(false)),
(name(decimal)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_decimal)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(total),
bounded(false),
cardinality(countable),
numeric(true)
])),
(base_type_definition(t_xsd_anySimpleType)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
5.2.2.8. Quantity
simpletype(t_xsd_integer,
'simpleType(xsd:integer)',
integer, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_integer)),
(scd('simpleType(xsd:integer)')),
(anonymous(false)),
(name(integer)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_decimal)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent))),
fractionDigits(value(0),
fixed(true),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(total),
bounded(false),
cardinality(countable),
numeric(true)
])),
(base_type_definition(t_xsd_decimal)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
simpletype(t_xsd_nonNegativeInteger,
'simpleType(xsd:nonNegativeInteger)',
nonNegativeInteger, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_nonNegativeInteger)),
(scd('simpleType(xsd:nonNegativeInteger)')),
(anonymous(false)),
(name(nonNegativeInteger)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_decimal)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent))),
fractionDigits(value(0),
fixed(true),
annotation(keyword(absent))),
minInclusive(value(0),
fixed(false),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(total),
bounded(false),
cardinality(countable),
numeric(true)
])),
(base_type_definition(t_xsd_integer)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
simpletype(t_xsd_positiveInteger,
'simpleType(xsd:positiveInteger)',
positiveInteger, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_positiveInteger)),
(scd('simpleType(xsd:positiveInteger)')),
(anonymous(false)),
(name(positiveInteger)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_decimal)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent))),
fractionDigits(value(0),
fixed(true),
annotation(keyword(absent))),
minInclusive(value(1),
fixed(false),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(total),
bounded(false),
cardinality(countable),
numeric(true)
])),
(base_type_definition(t_xsd_nonNegativeInteger)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
simpletype(t_e_quantity_t_e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(quantity)/simpleType()',
t_e_quantity_t_e_item_t_Items, 'http://www.example.com/PO1', local, [
(id(t_e_quantity_t_e_item_t_Items)),
(scd('/complexType(po:Items)/sequence()/element(item)/complexType()/sequence()/element(quantity)/simpleType()')),
(anonymous(true)),
(name(t_e_quantity_t_e_item_t_Items)),
(target_namespace('http://www.example.com/PO1')),
(variety(atomic)),
(primitive_type_definition(t_xsd_decimal)),
(item_type_definition(keyword(absent))),
(member_type_definitions(keyword(absent))),
(facets([
/* from decimal */
whiteSpace( value(collapse),
fixed(true),
annotation(keyword(absent))),
/* from integer */
fractionDigits(value(0), fixed(true), annotation(keyword(absent))),
/* from nonnegativeInteger, later overridden */
/*
minInclusive(value(0), fixed(false), annotation(keyword(absent))),
*/
/* from positiveInteger */
minInclusive(value(1), fixed(false), annotation(keyword(absent))),
/* from final derivation step for quantity */
maxExclusive(value(100), fixed(false), annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(total),
bounded(true),
cardinality(finite),
numeric(true)
])),
(base_type_definition(t_xsd_positiveInteger)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Simple type definitions in purchase-order schema (2L) 288 >
5.2.2.9. Date
simpletype(t_xsd_date, 'simpleType(xsd:date)',
date, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_date)),
(scd('simpleType(xsd:date)')),
(anonymous(false)),
(name(date)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_date)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(partial),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_anySimpleType)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
5.2.2.10. Other simple types
simpletype(t_xsd_QName, '/simpleType(xsd:QName)',
QName, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_QName)),
(scd('/simpleType(xsd:QName)')),
(anonymous(false)),
(name(QName)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_QName)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_anySimpleType)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
simpletype(t_xsd_anyURI, '/simpleType(xsd:anyURI)',
anyURI, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_anyURI)),
(scd('/simpleType(xsd:anyURI)')),
(anonymous(false)),
(name(anyURI)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_anyURI)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_anySimpleType)),
(final([])),
(annotation(keyword(absent)))
]).
/* the anonymous type associated with schemaLocation */
simpletype(t_xsd_list_anyURI, '/attribute(xsi:schemaLocation)/simpleType(*)',
'', 'http://www.w3.org/2001/XMLSchema', local, [
(id(t_xsd_list_anyURI)),
(scd('/simpleType(xsd:anyURI)')),
(anonymous(true)),
(name(keyword(absent))),
(target_namespace('http://www.w3.org/2001/XMLSchema-instance')),
(variety(list)),
(primitive_type_definition(t_xsd_anySimpleType)),
(item_type_definition(t_xsd_anyURI)),
(member_type_definitions([])),
(facets([])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(countable),
numeric(false)
])),
(base_type_definition(t_xsd_anySimpleType)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
simpletype(t_xsd_boolean, '/simpleType(xsd:boolean)',
boolean, 'http://www.w3.org/2001/XMLSchema', global, [
(id(t_xsd_boolean)),
(scd('/simpleType(xsd:boolean)')),
(anonymous(false)),
(name(boolean)),
(target_namespace('http://www.w3.org/2001/XMLSchema')),
(variety(atomic)),
(primitive_type_definition(t_xsd_boolean)),
(item_type_definition(keyword(absent))),
(member_type_definitions([])),
(facets([
whiteSpace(value(collapse),
fixed(true),
annotation(keyword(absent)))
])),
(fundamental_facets([
ordered(false),
bounded(false),
cardinality(finite),
numeric(false)
])),
(base_type_definition(t_xsd_anySimpleType)),
(final([])),
(annotation(keyword(absent)))
]).
This code is used in < Built-in simple type definitions (2L) 289 >
5.2.3. Reifying complex type definitions
5.2.3.1. Pattern for complex type definitions
complextype(TYPEID,
SCD,
Local_name, Target_namespace,
Scope, [
(id(TYPEID)),
(scd(SCD)),
(anonymous(Boolean)),
(name(Local_name)),
(target_namespace(Target_namespace)),
(base_type_definition(BASE_TYPEID)),
(derivation_method(DerivationKW)),
(final(FinalKWList)),
(abstract(Boolean)),
(attribute_uses([
au(RQ,AC,VC), ...
])),
(attribute_wildcard(Wildcard)),
(content_type(ContentType)),
(prohibited_substitutions(ListProhibitedKW)),
(annotations(InfosetOrAbsent))
]).
complextype(t_PurchaseOrderType,
'/complexType(po:PurchaseOrderType)',
'PurchaseOrderType', 'http://www.example.com/PO1',
global, [
(id(t_PurchaseOrderType)),
(scd('/complexType(po:PurchaseOrderType)')),
(anonymous(false)),
(name('PurchaseOrderType')),
(target_namespace('http://www.example.com/PO1')),
(base_type_definition(t_xsd_anyType)),
(derivation_method(restriction)),
(final([])),
(abstract(false)),
(attribute_uses([
au(required(false),
attdecl(a_orderDate_t_PurchaseOrderType),
value_constraint(keyword(absent)))
])),
(attribute_wildcard(keyword(absent))),
(content_type(c(content_t_PurchaseOrderType,element-only))),
(prohibited_substitutions([])),
(annotations(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
- The anonymous property is added, to provide a convenient way to determine whether the value of the name property was supplied in the schema or by the translation into Prolog. This is redundant: it is true iff we have scope(global).
- An attribute declaration is represented by the atom used as its unique identifier in this Prolog representation. (In practice, for local attributes this is a_ + the attribute's local name + the type's identifier.)
- An attribute use component is represented by a structure
of the form au(RQ,AC,VC), where
- RQ is the structure required(true) or required(false),
- AC (‘attribute component’) is the structure attdecl(ATTID) where ATTID is the atom used for the attribute declaration, and
- VC is a structure with functor value_constraint and a single argument, which is either keyword(absent) or required(Value) or fixed(Value)
- In the {content type} property
- The keyword empty is represented keyword(empty).
- A content model
is represented by a structure of the form
c_model(T,K), where
- T is the name of a non-terminal in the definite clause translation grammar (typically — always? — content_TYPEID), and
- K is one of the atoms element-only and mixed.
attdecl(a_orderDate_t_PurchaseOrderType,
'/complexType(po:PurchaseOrderType)/attribute(orderDate)',
orderDate, 'http://www.example.com/PO1',
local, [
(name(orderDate)),
(target_namespace('http://www.example.com/PO1')),
(type_definition(t_xsd_date)),
(scope(t_PurchaseOrderType)),
(value_constraint(keyword(absent))),
(annotation(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
5.2.3.2. Specific complex types
/* Complex type definitions */
{anyType (2L) 291}
{Complex type: t_PurchaseOrderType (2L) 307}
{Complex type: t_USAddress (2L) 310}
{Complex type: t_Items (2L) 312}
{Complex type: t_e_item_t_Items (2L) 313}
/* Attribute declarations */
{Attribute wildcard for anyType (2L) 292}
{Address attributes (2L) 311}
{Address attributes (2L) 314}
{Purchase order attributes (2L) 308}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
complextype(t_USAddress,'/complexType(po:USAddress)',
'USAddress', 'http://www.example.com/PO1',
global, [
(id(t_USAddress)),
(scd('/complexType(po:USAddress)')),
(anonymous(false)),
(name('USAddress')),
(target_namespace('http://www.example.com/PO1')),
(base_type_definition(t_xsd_anyType)),
(derivation_method(restriction)),
(final([])),
(abstract(false)),
(attribute_uses([
au(required(false),
attdecl(a_country_t_USAddress),
value_constraint(keyword(absent)))
])),
(attribute_wildcard(keyword(absent))),
(content_type(c_model(content_t_USAddress,element-only))),
(prohibited_substitutions([])),
(annotations(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
attdecl(a_country_t_USAddress,
'/complexType(po:USAddress)/attribute(country)',
country, 'http://www.example.com/PO1',
local, [
(name(country)),
(target_namespace('http://www.example.com/PO1')),
(type_definition(t_xsd_NMTOKEN)),
(scope(t_USAddress)),
(value_constraint(fixed('US'))),
(annotation(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
complextype(t_Items,'/complexType(po:Items)',
'Items', 'http://www.example.com/PO1',
global, [
(id(t_Items)),
(scd('/complexType(po:Items)')),
(anonymous(false)),
(name('Items')),
(target_namespace('http://www.example.com/PO1')),
(base_type_definition(t_xsd_anyType)),
(derivation_method(restriction)),
(final([])),
(abstract(false)),
(attribute_uses([])),
(attribute_wildcard(keyword(absent))),
(content_type(c_model(content_t_Items,element-only))),
(prohibited_substitutions([])),
(annotations(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
complextype(t_e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)/complexType() ',
t_e_item_t_Items, 'http://www.example.com/PO1',
local, [
(id(t_e_item_t_Items)),
(scd('/complexType(po:PurchaseOrderType)')),
(anonymous(true)),
(name('t_e_item_t_Items')),
(target_namespace('http://www.example.com/PO1')),
(base_type_definition(t_xsd_anyType)),
(derivation_method(restriction)),
(final([])),
(abstract(false)),
(attribute_uses([
au(required(true),
attdecl(a_partNum_t_e_item_t_Items),
value_constraint(keyword(absent)))
])),
(attribute_wildcard(keyword(absent))),
(content_type(c_model(content_t_e_item_t_Items,element-only))),
(prohibited_substitutions([])),
(annotations(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
attdecl(a_partNum_t_e_item_t_Items,
'/complexType(po:Items)/sequence()/element(item)/complexType()/attribute(partNum)',
partNum, 'http://www.example.com/PO1',
local, [
(name(partNum)),
(target_namespace('http://www.example.com/PO1')),
(type_definition(t_SKU)),
(scope(t_e_item_t_Items)),
(value_constraint(keyword(absent))),
(annotation(keyword(absent)))
]).
This code is used in < Complex types for PO schema (2L) 309 >
5.2.4. Extracting property information from type definitions
type_property(scd,TypeID,SCD) :-
simpletype(TypeID, SCD, _LN, _NS, _Level, _Properties);
complextype(TypeID, SCD, _LN, _NS, _Level, _Properties).
type_property(local_name,TypeID,LN) :-
simpletype(TypeID, _SCD, LN, _NS, _Level, _Properties);
complextype(TypeID, _SCD, LN, _NS, _Level, _Properties).
type_property(namespace, TypeID, NS) :-
simpletype(TypeID, _SCD, _LN, NS, _Level, _Properties);
complextype(TypeID, _SCD, _LN, NS, _Level, _Properties).
type_property(level,TypeID,Level) :-
simpletype(TypeID, _SCD, _LN, _NS, Level, _Properties);
complextype(TypeID, _SCD, _LN, _NS, Level, _Properties).
type_property(type,TypeID,simple) :-
simpletype(TypeID, _SCD, _LN, _NS, _Level, _Properties).
type_property(type,TypeID,complex) :-
complextype(TypeID, _SCD, _LN, _NS, _Level, _Properties).
Continued in <Fallback clause (2L) 316>This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
type_property(Prop,TypeID,Val) :- Prop \= scd, Prop \= local_name, Prop \= namespace, Prop \= level, Prop \= type, ( simpletype(TypeID, _SCD, _LN, _NS, _Level, Properties) ; complextype(TypeID, _SCD, _LN, _NS, _Level, Properties) ), Att =.. [Prop, Val], Properties ^^ Att.
5.3. Starting schema-validity assessment
- what document to validate
- whether to produce a PSVI or not (default: yes)
- whether to write error messages or not (if no PSVI is produced and no error messages are written, we'll provide some information via the return code: see below (default: yes, error messages)
- where to write the PSVI, if any (default: stdout)
- language and style of the messages
{Options for level 2L validation 328}
{Handling infoset as input (2L) 331}
{Handling file as input (2L) 333}
{Handling stream handle as input (2L) 334}
{Handling URI as input (2L) 335}
{Checking whether a list is in Anjewierden/Wielemaker form (2L) 332}
{Checking whether an atom is an HTTP URL (2L) 336}
{Read command-line options, produce Prolog representation (2L) 338}
{Mapping from property values to numbers (2L) 342}
{Overall validity message 415}
{Overall validity message (2L) 416}
{Reporting validation results (2L) 414}
{Find root element in infoset (PV) 252}
{Identify a parsed node as the validation root (PV) 208}
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
{Predicate sevastopol/5, main top-level predicate (2L) 327}
{Predicate sevastopol/4 (2L) 326}
{Predicate sevastopol/0 337}
{Calculate return code from validity and validation_attempted (2L) 340}
{Schema-information predicate (PV) 207}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
5.3.1. Shell script sevastopol
#!/bin/bash
### sevastopol: run purchase-order validator
{W3C copyright notice 87}
### 1 check argument count, usage
{Check argument count, issue usage message 320}
### 2 set verbosity option
{Set options for shell script 321}
### 3 invoke Prolog with the appropriate arguments
{Call Prolog with the appropriate arguments 323}
### 4 say something, if we need to
{Check return code, issue message if needed 324}
### 5 exit
{Exit with appropriate return code 325}
if [ $# -lt 1 -o "$1" = '?' -o "$1" = '-?' ] ; then echo "sevastopol: purchase-order validator, a conforming implementation of XML Schema 1.0" echo " with a fixed schema" echo "Usage: sevastopol INPUT [OPTION ...]" echo "where " echo "INPUT is the filename or URL of the purchase order to be validated" echo "OPTION is one of the known options:" echo " --language LANG specifies what language messages should be in, one of:" echo " en, de, fr" echo " --messages MSGLVL specifies how verbose messages should be: MSGLVL is one of:" echo " verbose, terse, silent" echo " --psvi PSVI_SET specifies how much of the PSVI to write out:" echo " red no output: [validity], [validation attempted], and" echo " [error code] on validation root only, conveyed" echo " by error messages and return code" echo " yellow [validity], [validation attempted], [error code], " echo " [notation system], and [notation public]" echo " wherever applicable" echo " blue yellow, plus information about [element declaration], " echo " [attribute declaration], [type definition], " echo " [member type definition], and [schema-normalized value]" echo " wherever applicable" echo " indigo yellow, plus [nil], [type definition name], " echo " [type definition namespace], [type definition type], " echo " [type definition anonymous], [member type definition name], " echo " [member type definition namespace], " echo " [member type definition type], " echo " [member type definition anonymous], [schema-normalized value], " echo " [schema default], [schema supplied], and" echo " [schema information], wherever applicable" echo " violet everything the processor has" echo " none same as 'red'" echo " full same as 'violet'" echo " --output FILENAME specifies a file to which output should be written." echo " Default: - (i.e. standard output stream)" echo " --test specifies that test-related predicates should be loaded." echo "" echo 'The return code is (1 * validity) + (4 * validation_attempted)), where' echo "valid = 0, notKnown = 1, invalid = 2, full = 0, partial = 1, none = 2" echo "So: return code of 0 = fully validated, valid" echo " 2 = fully validated, invalid" echo " 4 = partly validated, valid" echo " 5 = partly validated, validity notKnown" echo " 6 = partly validated, invalid" echo " 9 = not validated, validity notKnown" echo "N.B. return codes of 1, 8, and 10 denote combinations of the validity" echo "and validation attempted properties which will not occur." echo "" exit fi
This code is used in < Shell script sevastopol (purchase-order validator) 319 >
trigger=0
fTest=0
fVerbose='terse'
lArgs="$*"
until [ -z "$1" ] ; do
if [ "$1" = "--messages" ] ; then
fVerbose=${2:-"terse"}
shift
elif [ "$1" = "--test" ] ; then
fTest=1
fi
shift
done
This code is used in < Shell script sevastopol (purchase-order validator) 319 >
trigger=0
fTest=0
for i do
if [ "$i" = "--messages" ] ; then
trigger=1
elif [ $trigger -eq 1 ] ; then
fVerbose="$i"
break
elif [ "$i" = "--test" ] ; then
fTest=1
break
else
trigger=0
fi
done
This code is not used elsewhere.
PROLOGDIR="/home/cmsmcq/2004/schema/dctg/Prolog" if [ $fTest -eq 0 ] ; then PROG="$PROLOGDIR/load_2l.pl" GOAL="sevastopol" else PROG="$PROLOGDIR/test_2l.pl" GOAL="run_test" fi pl -q -f $PROG -g $GOAL -t 'halt(13)' -- "$lArgs" ; RC=$?
This code is used in < Shell script sevastopol (purchase-order validator) 319 >
### if --messages verbose, then say what the result was
if [ "$fVerbose" = "verbose" ] ; then
VALCODE=[$RC%4]
ATTCODE=[$RC/4]
case "$VALCODE" in
0 ) VALSTR="valid";;
1 ) VALSTR="notKnown";;
2 ) VALSTR="invalid";;
3 ) VALSTR="error, this value should be impossible";;
esac
case "$ATTCODE" in
0 ) ATTSTR="full";;
1 ) ATTSTR="partial";;
2 ) ATTSTR="none";;
3 ) ATTSTR="error, this value should be impossible";;
esac
echo "sevastopol: Return code $RC: [validity = $VALSTR],[validation attempted = $ATTSTR]" >&2
fi
This code is used in < Shell script sevastopol (purchase-order validator) 319 >
exit $RC
This code is used in < Shell script sevastopol (purchase-order validator) 319 >
5.3.2. Top-level Prolog predicates
- sevastopol(+Source, -PSVI, -Validity, -Validation_attempted, +Options): true if and only if purchase-order validation of the Source using Options specified produces the result PSVI, whose top level has [validity = Validity] and [validation attempted = Validation_attempted.
- sevastopol(+Source, -PSVI, -Validity, -Validation_attempted): same as the preceding, using the default options.
- sevastopol: same as the preceding, but reads the options from the command line.
5.3.2.1. Calling with defaulted options
sevastopol(In,Out,V,VA) :- sevastopol(In,Out,V,VA,[]).
This code is used in < Initiating schema-validity assessment, po-specific (2L) 318 >
5.3.2.2. Main top-level predicate
sevastopol(In,PSVI,V,VA,Options0) :-
/* handle the options */
default_sva_options(Defaults),
set_sva_options(Options0,Defaults,Options),
/* set up the input infoset */
in_infoset(In,Infoset,Options),
infoset_root(Infoset, Root),
/* validate the infoset as a purchase order element,
* fall back if you have to */
( element(e_purchaseOrder, 'element(/1)', [ns('##NONE','')],
PN, [Root],[])
; infoitem([ns('##NONE','')], PN, [Root],[])
),
anoint_root(PN,PSVI),
PSVI^^validity(V),
PSVI^^validation_attempted(VA),
/* write the output */
report_results(V, VA, PSVI, Options).
This code is used in < Initiating schema-validity assessment, po-specific (2L) 318 >
5.3.2.2.1. Handling options
- language(lang-code): what language to write messages in. Eventually, we'll support more than one language, but for now only “en” is really implemented.
- messages(level): verbose, terse, silent.
- psvi(subset): red, yellow, blue, indigo, violet, none (= red), full (= violet, at least mostly). For now, using the write_psvi predicate from the PV validator, the only values we understand are “full” and “violet”.
- output(filename), with default of “-” (meaning standard output).
/* Options for 2L */ default_sva_options(l2opts(en,verbose,full,'-')). option_value(language,l2opts(L,_M,_P,_O),L). option_value(messages,l2opts(_L,M,_P,_O),M). option_value(psvi, l2opts(_L,_M,P,_O),P). option_value(output, l2opts(_L,_M,_P,O),O).Continued in <Setting options (2L) 329>, <Setting options (2L) 330>
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
set_option_value(language(L),l2opts(_L,M,P,O), l2opts(L,M,P,O)). set_option_value(messages(M),l2opts(L,_M,P,O), l2opts(L,M,P,O)). set_option_value(psvi(P), l2opts(L,M,_P,O), l2opts(L,M,P,O)). set_option_value(output(O), l2opts(L,M,P,_O), l2opts(L,M,P,O)). set_option_value(xsitype_fallback(F), l2opts(L,M,P,O), l2opts(L,M,P,O)) :- retractall(sevastopol_global_option(xsitype_fallback,_)), assert(sevastopol_global_option(xsitype_fallback,F)).
set_sva_options([],Options,Options). set_sva_options([O|Os],Options0,Options) :- set_option_value(O, Options0, Options1), set_sva_options(Os, Options1, Options).
5.3.2.2.2. Mapping input into an infoset
in_infoset([H|T],[H|T],_Options) :- wielemaker_form([H|T]).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
/* a list is in Anjewierden/Wielemaker form if all of * its members are atoms, or element structures, or * entity, sdata, ndata, or pi structures */ wielemaker_form([]). wielemaker_form([H|T]) :- atom(H), wielemaker_form(T). wielemaker_form([element(_,_,_)|T]) :- wielemaker_form(T). wielemaker_form([entity(_)|T]) :- wielemaker_form(T). wielemaker_form([sdata(_)|T]) :- wielemaker_form(T). wielemaker_form([ndata(_)|T]) :- wielemaker_form(T). wielemaker_form([pi(_)|T]) :- wielemaker_form(T).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
in_infoset(Filename,Infoset,_Options) :- exists_file(Filename), load_structure(Filename,Infoset,[dialect(xmlns),space(remove)]).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
in_infoset(stream(Handle),Infoset,_Options) :-
load_structure(stream(Handle),Infoset,
[dialect(xmlns),space(remove)]).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
in_infoset(URL,Infoset,_Options) :- http_url(URL), http_open(URL,Stream,[timeout(15)]), load_structure(Stream,Infoset,[dialect(xmlns),space(remove)]), close(Stream).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
http_url(URL) :- parse_url(URL, Parts), member(protocol(http),Parts).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
5.3.2.2.3. Reporting results
- write out the PSVI to an output stream
- traverse the PSVI and issue error messages where we find validity problems
- exit with an appropriate return code
5.3.2.3. Invocation from command-line
sevastopol :- cl_args_options([Input],Options), sevastopol(Input, PSVI, V, VA, Options), po_psvi_rc(PSVI, V, VA, RC), halt(RC).
This code is used in < Initiating schema-validity assessment, po-specific (2L) 318 >
- The application-specific arguments are all given following the token “--” and tokens preceding that double hyphen are for the Prolog system itself. (SWI Prolog stops scanning the argument list when it sees “--”.)
- The first application tokens, up to the first token which begins with a double hyphen, are the arguments.
- The other application tokens are either functors, marked with two hyphens as the first two characters of the token, or arguments (not so marked) of the preceding functor.
cl_args_options(Args,Options) :- current_prolog_flag(argv,CLArgs), cl_args_options(_Sys,Args,Options,CLArgs,[]).Continued in <Grammar for command line (2L) 339>
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
cl_args_options(Sys,Args,Options) -->
sys_args(Sys), ['--'], args(Args), options(Options).
cl_args_options(Sys,[],[]) -->
sys_args(Sys).
sys_args([Arg|Args]) --> [Arg],
{ Arg \= '--' },
sys_args(Args).
sys_args([]) --> [].
args([Arg|Args]) --> [Arg],
{ not(atom_concat('--',_F,Arg)) },
args(Args).
args([]) --> [].
options([O|Os]) --> option(O), options(Os).
options([]) --> [].
option(O) --> [Token], args(Args),
{ atom_concat('--',Functor,Token),
O =.. [Functor | Args] }.
- sevastopol po.xml --language en --messages verbose --psvi full yields the Prolog command line pl -q -f $PROLOGDIR/load_2l.pl -g sevastopol -t 'halt(13)' -- po.xml --language en --messages verbose --psvi full, which in turn yields the argument po.xml and the options [language(en), messages(verbose), psvi(full)].
- sevastopol input --foo bar --phu baz blort is translated into the Prolog command line pl -q -f $PROLOGDIR/load_2l.pl -g sevastopol -t 'halt(13)' -- input --foo bar --phu baz blort, which yields the argument input and the options [foo(bar), phu(baz,blort)].
po_psvi_rc(PSVI, V, VA, RC) :-
PSVI ^^ type_definition_name('PurchaseOrderType'),
PSVI ^^ type_definition_namespace('http://www.example.com/PO1'),
validity_rc(V,IntV),
validation_attempted_rc(VA,IntVA),
RC is (4 * IntVA + IntV).
Continued in <Calculate return code from validity and validation_attempted (2L) 341>This code is used in < Initiating schema-validity assessment, po-specific (2L) 318 >
/* If the element was not validated against PurchaseOrderType,
* then it's partially validated and invalid, for our purposes.
* 6 = 4 (partially validated) + 2 (invalid).
*/
po_psvi_rc(PSVI, _V, _VA, 6) :-
not((PSVI ^^ type_definition_name('PurchaseOrderType'),
PSVI ^^ type_definition_namespace('http://www.example.com/PO1'))).
/* Numeric equivalents for validity and validation-attempted * properties, for use in calculating return code */ validity_rc(valid,0). validity_rc(notKnown,1). validity_rc(invalid,2). validation_attempted_rc(full,0). validation_attempted_rc(partial,1). validation_attempted_rc(none,2).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
5.4. Validating individual elements
5.4.1. The element grammar rule
element(ED_declared, VRoot, Lnsb0) ::=
[element(GI, Lras, Lre)],
{
eii_match_decl_decl(GI,ED_declared,ED),
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_eii(ED,element(GI,Lras,Lre),Lnsb,Type,Lerr0),
once(sva_type_atts(Type,Lras,VRoot,Lpa,Lpna,Lerr1)),
sva_type_content(Type,VRoot,Lnsb,Lre,Lpe,Lerr2)
}
<:> local_name(Localname) ::- name_parts(GI,_,Localname)
&& namespace_name(Namespace) ::- name_parts(GI,Namespace,_)
&& type_definition_anonymous(TD_anon) ::-
type_property(anonymous,Type,TD_anon)
&& type_definition_namespace(TD_ns) ::-
type_property(target_namespace,Type,TD_ns)
&& type_definition_name(TD_ln) ::-
type_property(name,Type,TD_ln)
&& type_definition_type(TD_type) ::-
type_property(type,Type,TD_type)
&& info_item(element)
&& attributes(Lpa)
&& namespace_attributes(Lpna)
&& inscope_namespaces(Lnsb)
&& children(Lpe)
&& schema_error_code(Lerr) ::-
flatten([Lerr0,Lerr1,Lerr2],Lerr)
&& validity(V) ::-
calc_validity(Lerr0,Lerr1,Lerr2,Lpa,Lpe,V)
&& nil(false)
&& validation_context(VRoot)
&& validation_attempted(VA) ::-
( type_property(type,Type,complex)
-> calc_validation_attempted(Lpa,Lpe,VA)
; type_property(type,Type,simple)
-> VA = 'full'
; Type = kw(absent)
-> VA = 'partial'
)
.
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.4.2. Validating elements against element declarations
5.4.2.1. Finding the right element declaration
eii_match_decl_decl(GI,ED,ED) :- name_parts(GI,NS,LN), elemdecl_property(namespace,ED,NS), elemdecl_property(local_name,ED,LN).
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.4.2.2. Validating elements against their declarations
sva_elemdecl_eii(Elemid,element(_GI, Lras,_Lre), Lnsb, TypeID, Lerr) :-
{Check for xsi:nil attribute, validate (2L) 346},
{Check for xsi:type attribute, validate (2L) 347}.
This code is used in < DCTG for purchase order schema, layer 2L 268 >
( member('http://www.w3.org/2001/XMLSchema-instance':
nil=_Value, Lras)
-> Lerr0 = [error('cvc-elt.3.1',
'xsi:nil attribute not allowed: element not nillable',
[element(Elemid), atts(Lras)])]
; Lerr0 = [])
This code is used in < Validating elements against element declarations (2L) 345 >
( member(
'http://www.w3.org/2001/XMLSchema-instance':
type=QN_LocalType,Lras)
-> {Validate xsi:type, fall back if needed (2L) 348}
; Lerr1 = [],
elemdecl_property(type_definition,Elemid,TypeID)
),
append(Lerr0,Lerr1,Lerr)
This code is used in < Validating elements against element declarations (2L) 345 >
sva_xsitype(Elemid, QN_LocalType, Lnsb, TypeID0, Lerr1),
( Lerr1 = []
-> TypeID = TypeID0
; xsitype_fallback(Elemid,TypeID)
)
This code is used in < Check for xsi:type attribute, validate (2L) 347 >
xsitype_fallback(Elemid,Typeid) :-
( sevastopol_global_option(xsitype_fallback,true),
elemdecl_property(type_definition,Elemid,Typeid)
-> true
; Typeid = kw(absent)
).
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.4.3. Extracting information about type derivation and element/type bindings
/* Information about element/type bindings * (temporary location: move this to some more * appropriate location to be identified) */ elem_type(Eid,Tid) :- elemdecl_property(type_definition,Eid,Tid).
This code is used in < DCTG for purchase order schema, layer 2L 268 >
/* sva_xsitype(+Elemid, +QN_LocalType, +Lnsb, -TypeID, -Lerr): true if
Lerr is the list of errors involved if QN_LocalType is
the value of an xsi:type attribute on an element of type
Elemid, with Lnsb the list of active namespace bindings.
*/
sva_xsitype(Elemid, QN_LocalType, Lnsb, Typeid, Lerr) :-
/* First, check that it's a legal QName */
( sva_type_plf(t_xsd_QName,QN_LocalType,LF,PN,Lerr0)
-> {Check return from QName check (PV) 190}
; Lerr = [error('cvc-elt.4.1',
'xsi:type attribute should have a legal QName as its value',
[element(Elemid),localtype(QN_LocalType),
trace('sva_plf_t_xsd_QName did not return')])]).
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
/* sva_xsitype_resolve(+PN, +Lnsb, -Typeid, -Lerr):
true iff the parsed QName PN resolves, in the context of the
current list of namespace bindings Lnsb and the current schema,
to type Typeid, or else we get the errors in Lerr. */
sva_xsitype_resolve(PN, Lnsb, Typeid, Lerr) :-
qname_expand(PN, Lnsb, expqname(NS,LName,_Prefix), Lerr0),
( ( simpletype(Typeid, _SCD, LName, NS, _Local, _Props)
; complextype(Typeid, _SCD, LName, NS, _Local, _Props) )
-> Lerr = Lerr0
; Lerr = [error(l2_sva_xsitype_resolve,
'expanded name does not map to a type',
[ns(NS), ln(LName)]) | Lerr0]
).
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
type_base(T1,T2) :- type_property(base_type_definition,T1,T2).
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.4.4. Validating elements against type definitions
5.5. Validating content and pre-lexical forms against simple types
5.5.1. Validation
5.5.1.1. Generic sva_type_content predicate for simple types
sva_type_content(Tid,_VR,_Lnsb,Lre,Lpe,Lerr) :-
type_property(type,Tid,simple),
sva_type_plf(Tid,Lre,Lpe,_PN,Lerr).
{Type-specific type_value constraints for built-ins (2L) 372}
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
/* Schema-specific rules for sva_content_TYPEID predicates
* used to be here. Replaced by single generic rule
* for sva_type_content(Typeid,VR,Lnsb,Lre,Lpe,Lerr).
*/
{Type-specific type_value constraints (2L) 369}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
5.5.1.2. Generic sva_type_plf predicate
sva_type_plf(Tid,PLF,LF,PN,Lerr) :-
( aelist_chars(PLF,Lch,Lerr0)
-> {Check return code from aelist_chars, if OK do wlv checks (2L) 361}
; Lerr = [error('sva_type_plf.1','aelist_chars failed',
[type(Tid), ce([])])],
PN = 'unparsed',
LF = []).
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
( Lerr0 = []
-> {Get whitespace keyword, normalize pre-lexical form (2L) 362}
; Lerr = [error('sva_type_plf.2','aelist_chars failed',
[type(Tid), ce(Lerr0)])],
PN = 'unparsed',
LF = [])
This code is used in < Checking pre-lexical forms against built-in types (2L) 360 >
( ( ( type_property(facets,Tid,Lfacets),
Lfacets ^^ whiteSpace(value(KwWS),fixed(_),annotation(_)) )
; KwWS = 'preserve'
)
-> {Perform whitespace normalization on pre-lexical form (2L) 363}
; Lerr = [error('sva_type_plf.3','unable to extract value of whitespace facet',
[type(Tid), ce([])])],
PN = 'unparsed',
LF = [])
This code is used in < Check return code from aelist_chars, if OK do wlv checks (2L) 361 >
( ws_normalize(KwWS,Lch,LF,Lerr1)
-> {Check return code from ws_normalize, if OK do lv checks (2L) 364}
; Lerr = [error('sva_type_plf.4','white-space normalization failed (cannot happen)',
[type(Tid), ce([]), kw(KwWS), lch(Lch)])],
PN = 'unparsed',
LF = [])
This code is used in < Get whitespace keyword, normalize pre-lexical form (2L) 362 >
( Lerr1 = []
-> {Check lexical form and value (2L) 365}
; Lerr = [error('sva_type_plf.5','white space normalization raised error',
[type(Tid), ce(Lerr1), kw(KwWS), lch(Lch), lf(LF)])],
PN = 'unparsed')
This code is used in < Perform whitespace normalization on pre-lexical form (2L) 363 >
( type_lexform(Tid,PN,LF,[])
-> {Check return from type_lexform for errors, if OK do value checks (2L) 366}
; Lerr = [error('cvs-datatype-valid.1','bad lexical form, grammar did not return',
[type(Tid), ce([]), lf(LF)])],
PN = 'unparsed')
This code is used in < Check return code from ws_normalize, if OK do lv checks (2L) 364 >
( PN ^^ errors(Lerr2),
Lerr2 = []
-> {Check value constraints (2L) 367}
; Lerr = [error('cvs-datatype-valid.1','lexical form parsed with errors',
[type(Tid), ce(Lerr2), lf(LF)])])
This code is used in < Check lexical form and value (2L) 365 >
( type_value(Tid,PN,Lerr3)
-> {Check return code from type_value (2L) 368}
; Lerr = [error('sva_type_plf.6','failure while checking value constraints',
[type(Tid), ce([])])])
This code is used in < Check return from type_lexform for errors, if OK do value checks (2L) 366 >
( Lerr3 = []
-> Lerr = []
; Lerr = error('cvc-datatype-valid.2','failure to satisfy value constraints',
[type(Tid), ce(Lerr3)]))
This code is used in < Check value constraints (2L) 367 >
5.5.1.3. Type-specific value constraints
/* value constraints for SKU */ type_value(t_SKU,_PN,[]).Continued in <Checking quantity values (2L) 370>
This code is used in < Simple-type content rules for purchase-order types (2L) 359 >
/* value constraints for quantities */
type_value(t_e_quantity_t_e_item_t_Items,PN,Lerr) :-
PN ^^ value(V),
( V >= 1
-> {Checking quantity value against max (2L) 371}
; Lerr = [error('cvc-minInclusive-valid',
'Value too small',
[minInclusive(1), value(V), type(t_e_quantity_t_e_item_t_Items)])]).
( V < 100
-> Lerr = []
; Lerr = [error('cvc-maxExclusive-valid',
'Value too large',
[maxExclusive(100), value(V), type(t_e_quantity_t_e_item_t_Items)])])
This code is used in < Checking quantity values (2L) 370 >
type_value(t_xsd_string,_PN,[]). type_value(t_xsd_decimal,_PN,[]). type_value(t_xsd_date,PN,Lerr) :- date_ok(PN,Lerr). type_value(t_xsd_QName,_PN,[]). type_value(t_xsd_NMTOKEN,_PN,[]). type_value(t_xsd_anyURI,_PN,[]). type_value(t_xsd_list_anyURI,_PN,[]). type_value(t_xsd_boolean,_PN,[]).
This code is used in < sva_content rules for built-in types (2L) 358 >
type_facet_value(Fname,Tid,Fvalue) :- type_property(facets,Tid,Lfacets), Att =.. [Fname | Fargs], Lfacets ^^ Att, member(value(Fvalue, Fargs)).
This code is not used elsewhere.
5.5.1.4. Grammar rules for simple types
/* DCTG rules for lexical forms of built-in types. */
{Lexical form of string (L2) 377}
{Lexical form for NMTOKEN (2L) 378}
{Lexical form of decimal (2L) 379}
{Lexical form for dates (2L) 381}
{Lexical form for QNames (2L) 382}
{Lexical form of anyURI (L2) 383}
{Lexical form for list_anyURI (2L) 384}
{Lexical form for boolean (2L) 385}
{Checking date values (PV) 134}
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
/* Schema-specific PLF rules used to be here; replaced by
* single generic rule sva_type_plf/4.
*/
{Lexical form for SKU (2L) 387}
{Lexical form for quantity type (2L) 386}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
5.5.1.5. Generic utilities
5.5.2. Recasting the lexical-form rules
5.5.2.1. Lexical form for string
:- multifile
type_lexform/4.
type_lexform(t_xsd_string) ::= []
<:> errors([])
&& value([]).
type_lexform(t_xsd_string) ::= [Code], type_lexform(t_xsd_string)^^R,
{ ( atom_chars(Code,[Code])
-> Lerr0 = []
; not(integer(Code))
-> Lerr0 = [error(pv_string1,
'Non-integer, non-character code point found',
[code(Code)])]
; Code > 1114112
-> Lerr0 = [error(pv_string2,
'Code point too large',
[code(Code)])]
; Code < 0
-> Lerr0 = [error(pv_string3,
'Code point negative',
[code(Code)])]
; Code =:= 0
-> Lerr0 = [error(pv_string4,
'NUL character not legal in XML',
[])]
; Lerr0 = []
)
}
<:> errors(Lerr) ::-
R ^^ errors(Lerr1),
append(Lerr0,Lerr1, Lerr)
&& value(S) ::- R ^^ value(S0),
(Lerr0 = []
-> S = [Code | S0]
; S = S0)
.
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
5.5.2.2. Lexical form for NMTOKEN(s)
type_lexform(t_xsd_NMTOKEN) ::= name_char^^C, other_name_chars^^Tail
<:> value(V) ::- C^^value(Vc),
Tail^^value(Vt),
append(Vc,Vt,V)
&& errors([])
.
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
5.5.2.3. Lexical form for decimal
type_lexform(t_xsd_decimal) ::= type_lexform(t_xsd_integer)^^I, fractionalpart^^F
<:> lexval(LV) ::- I^^lexval(LVi),
F^^lexval(LVf),
append(LVi,LVf,LV)
&& value(V) ::- I^^value(Vi),
F^^value(Vf),
/* if sign is negative, subtract Vf,
* else add */
(I^^lexval(['-'|_])
-> V is Vi - Vf
; V is Vi + Vf)
&& errors(Lerr) ::- I^^errors(Lerr0),
F^^errors(Lerr1),
append(Lerr0,Lerr1,Lerr).
{Lexical form of integer (2L) 380}
{Grammar for fractional part of decimal (PV) 114}
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
type_lexform(t_xsd_integer) ::= opt_sign^^S, digits^^D,
{ S ^^ lexval(Sign),
D ^^ lexval(LVd) }
<:> lexval([Sign | LVd])
&& value(V) ::- Sign = '+',
length(LVd, S0),
Scale is S0 - 1,
D^^value(Scale,V)
/* N.B. Scale is passed in as parameter to help
* determine value. */
&& value(Vn) ::- Sign = '-',
length(LVd, S0),
Scale is S0 - 1,
D^^value(Scale,V0),
Vn is 0 - V0
&& errors(Lerr) ::- S^^errors(Lerrs),
D^^errors(Lerrd),
append(Lerrs,Lerrd,Lerr).
This code is used in < Lexical form of decimal (2L) 379 >
5.5.2.4. Lexical form for dates
type_lexform(t_xsd_date) ::= year^^Y, hyphen, month^^M, hyphen, day^^D
<:> errors(Lerr) ::-
Y^^errors(Lerr1),
M^^errors(Lerr2),
D^^errors(Lerr3),
flatten([Lerr1,Lerr2,Lerr3],Lerr)
&& year(YV) ::- Y^^value(YV)
&& month(MV) ::- M^^value(MV)
&& day(DV) ::- D^^value(DV)
{Calculating a date value (PV) 133}
.
{Lexical form for year (PV) 128}
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
5.5.2.5. Lexical form for QNames
/* do an eager match first: use the colon if it's there */
type_lexform(t_xsd_QName) ::= type_lexform(t_xsd_NCName)^^P, colon, type_lexform(t_xsd_NCName)^^L
<:> errors(Lerr) ::-
P^^errors(Lerr1),
L^^errors(Lerr2),
flatten([Lerr1,Lerr2],Lerr)
&& prefix(Prefix) ::- P^^value(LcPrefix), atom_chars(Prefix,LcPrefix)
&& local_name(LName) ::- L^^value(LcLName), atom_chars(LName,LcLName)
.
/* if there is no colon, fall back to this. */
type_lexform(t_xsd_QName) ::= type_lexform(t_xsd_NCName)^^L
<:> errors(Lerr) ::-
L^^errors(Lerr)
&& prefix('')
&& local_name(LName) ::- L^^value(LName)
.
type_lexform(t_xsd_NCName) ::= namestart_char^^C, other_name_chars^^Tail
<:> value(V) ::- C^^value(Vc),
Tail^^value(Vt),
append(Vc,Vt,V)
&& errors([])
.
colon ::= [':'].
namestart_char ::= [Char], { namestart_char(Char) }
<:> value([Char]).
name_char ::= [Char], { name_char(Char) }
<:> value([Char]).
other_name_chars ::= name_char^^C, other_name_chars^^Tail
<:> value(V) ::- C^^value(Vc),
Tail^^value(Vt),
append(Vc,Vt,V)
.
other_name_chars ::= []
<:> value([]).
/* Eventually, we'll do the right thing by Unicode. For now,
* a quick approximation for those who really only use ASCII
* anyway. */
/*
namestart_char(Char) :-
( char_type(Char,csymf)
; Char = '.'
; Char = '-' ).
name_char(Char) :-
( char_type(Char,csym)
; Char = '.'
; Char = '-' ).
*/
namestart_char('.').
namestart_char('-').
namestart_char(Char) :- char_type(Char,csymf).
name_char('.').
name_char('-').
name_char(C) :- integer(C), C < 256, char_type(C,csym).
name_char(Char) :- not(integer(Char)), char_type(Char,csym).
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
5.5.2.6. Lexical form for anyURI
/* anyURI ::= scheme_name ':' scheme-specific ('#' hashless_string)?
| random ('#' hashless_string)?
*/
:- use_module(po_lib('rfc2396.dctg')).
type_lexform(t_xsd_anyURI) ::= rfc2396^^URI
<:> errors([])
&& uri(URI)
.
/*
lexform_t_xsd_anyURI ::= []
<:> errors([])
&& value([]).
lexform_t_xsd_anyURI ::= [Code], lexform_t_xsd_anyURI^^R,
{ ( Code = '#'
( C
-> Lerr0 = []
; not(integer(Code))
-> Lerr0 = [error(pv_string1,
'Non-integer, non-character code point found',
[code(Code)])]
; Code > 1114112
-> Lerr0 = [error(pv_string2,
'Code point too large',
[code(Code)])]
; Code < 0
-> Lerr0 = [error(pv_string3,
'Code point negative',
[code(Code)])]
; Code =:= 0
-> Lerr0 = [error(pv_string4,
'NUL character not legal in XML',
[])]
; Lerr0 = []
)
}
<:> errors(Lerr) ::-
R ^^ errors(Lerr1),
append(Lerr0,Lerr1, Lerr)
&& value(S) ::- R ^^ value(S0),
(Lerr0 = []
-> S = [Code | S0]
; S = S0)
.
*/
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
5.5.2.7. Lexical form for list_anyURI
type_lexform(t_xsd_list_anyURI) ::=
type_lexform(t_xsd_anyURI)^^U,
continued_lexform_t_xsd_list_anyURI^^Us,
{ U^^uri(URI), Us^^urilist(URIs) }
<:> urilist([URI|URIs])
&& errors([])
.
continued_lexform_t_xsd_list_anyURI ::= whitespace,
type_lexform(t_xsd_list_anyURI)^^Us,
{ Us^^urilist(URIs) }
<:> urilist(URIs).
continued_lexform_t_xsd_list_anyURI ::= opt_whitespace
<:> urilist([])
&& errors([]).
whitespace ::= ws, opt_whitespace.
opt_whitespace ::= [].
opt_whitespace ::= ws, opt_whitespace.
ws ::= [' '].
ws ::= ['\t'].
ws ::= ['\r'].
ws ::= ['\n'].
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
5.5.2.8. Lexical form for boolean
type_lexform(t_xsd_boolean) ::= bool_true <:> errors([]). type_lexform(t_xsd_boolean) ::= bool_false <:> errors([]). bool_true ::= ['1']. bool_true ::= [t], [r], [u], [e]. bool_false ::= ['0']. bool_false ::= [f], [a], [l], [s], [e].
This code is used in < Grammar rules for lexical forms of built-in types (2L) 374 >
5.5.2.9. Quantity
type_lexform(t_e_quantity_t_e_item_t_Items) ::= opt_plussign^^S, digits^^D,
{ S ^^ lexval(Sign),
D ^^ lexval(LVd) }
<:> lexval([Sign | LVd])
&& value(V) ::- Sign = '+',
length(LVd, S0),
Scale is S0 - 1,
D^^value(Scale,V)
/* N.B. Scale is passed in as parameter to help
* determine value. */
&& errors(Lerr) ::- S^^errors(Es),
D^^errors(Ed),
append(Es,Ed,Lerr).
opt_plussign ::= []
<:> lexval('+')
&& errors([]).
opt_plussign ::= ['+']
<:> lexval('+')
&& errors([]).
This code is used in < Checking (pre-)lexical forms against schema-specific types (2L) 375 >
5.5.2.10. SKU
type_lexform(t_SKU) ::= sku_decimal_part^^D, hyphen, sku_alpha_part^^A
<:> errors(Lerr) ::-
D^^errors(LerrD),
A^^errors(LerrA),
append(LerrD,LerrA,Lerr)
&& lexval(LV) ::-
D^^lexval(LVD),
A^^lexval(LVA),
flatten([LVD,['-'],LVA],LV)
&& value(V) ::-
D^^lexval(LVD),
A^^lexval(LVA),
flatten([LVD,['-'],LVA],V).
/* Having both 'value' and 'lexval' looks rather dumb
* for strings */
sku_decimal_part ::= digit^^D1, digit^^D2, digit^^D3
<:> errors(Lerr) ::-
D1^^errors(Lerr1),
D2^^errors(Lerr2),
D3^^errors(Lerr3),
flatten([Lerr1,Lerr2,Lerr3],Lerr)
&& lexval([LV1,LV2,LV3]) ::-
D1^^lexval(LV1),
D2^^lexval(LV2),
D3^^lexval(LV3).
sku_alpha_part ::= cap_a_z^^L1, cap_a_z^^L2
<:> errors(Lerr) ::-
L1^^errors(Lerr1),
L2^^errors(Lerr2),
append(Lerr1,Lerr2,Lerr)
&& lexval([LV1,LV2]) ::-
L1^^lexval(LV1),
L2^^lexval(LV2).
/* Since the ISO Prolog character set is ISO Latin 1,
* it's not enough to call char_type(Char,upper),
* we also need to check that the character is in the ASCII
* range to make sure it's in the range [A-Z]. */
cap_a_z ::= [Char],
{ char_type(Char,upper),
char_type(Char,ascii) }
<:> errors([])
&& lexval(Char).
This code is used in < Checking (pre-)lexical forms against schema-specific types (2L) 375 >
5.6. Validating content against complex types
5.6.1. The sva_type_content predicate for complex types
sva_type_content(TYPEID,VRoot,Lnsb,Lre,Lpe,Lerrors) :-
TYPEID \== kw(absent),
(content(TYPEID,VRoot,Lnsb,Topnode,Lre,[])
-> Topnode ^^ children(Lpe),
Lerrors = []
; content_skip(Lnsb,Lre,Lpe,Lerrors0),
content_error(Lre,TYPEID,Lerrors1),
append(Lerrors0,Lerrors1,Lerrors)).
/* If for some reason we don't have a type, we fall back to
* content_skip. For example, if xsi:type failed to resolve */
sva_type_content(kw(absent), _VRoot, Lnsb, Lre, Lpe, Lerr) :-
content_skip(Lnsb,Lre,Lpe,Lerr).
This code is used in < Complex-content rules (2L) 391 >
5.6.2. Content model rules for complex types
:- multifile content/6.
content(t_PurchaseOrderType,VRoot,Lnsb) ::=
element(e_shipTo_t_PurchaseOrderType,VRoot,Lnsb)^^S,
element(e_billTo_t_PurchaseOrderType,VRoot,Lnsb)^^B,
opt(e_comment,VRoot,Lnsb)^^C,
element(e_items_t_PurchaseOrderType,VRoot,Lnsb)^^I
{Children attribute of t_PurchaseOrder 36}
.
content(t_USAddress,VRoot,Lnsb) ::=
element(e_name_t_USAddress,VRoot,Lnsb)^^N,
element(e_street_t_USAddress,VRoot,Lnsb)^^S,
element(e_city_t_USAddress,VRoot,Lnsb)^^C,
element(e_state_t_USAddress,VRoot,Lnsb)^^ST,
element(e_zip_t_USAddress,VRoot,Lnsb)^^Z
{Children attribute of t_USAddress 33}
.
content(t_Items,VRoot,Lnsb) ::=
star(e_item_t_Items,VRoot,Lnsb)^^L
{Children attribute of content_t_Items 40}
.
content(t_e_item_t_Items,VRoot,Lnsb) ::=
element(e_productName_t_e_item_t_Items,VRoot,Lnsb)^^PN,
element(e_quantity_t_e_item_t_Items,VRoot,Lnsb)^^Q,
element(e_USPrice_t_e_item_t_Items,VRoot,Lnsb)^^USP,
opt(e_comment,VRoot,Lnsb)^^C,
opt(e_shipDate_t_e_item_t_Items,VRoot,Lnsb)^^S
{Children attribute of t_e_item_t_Items 37}
.
Continued in <Generic rules for optional and starred elements (2L) 390>This code is used in < Complex-content rules (2L) 391 >
opt(_ELEMID,_VRoot,_Lnsb) ::= [] <:> children([]) . opt(ELEMID,VRoot,Lnsb) ::= element(ELEMID,VRoot,Lnsb)^^Elemchild <:> children([Elemchild]) . star(_ELEMID,_VRoot,_Lnsb) ::= [] <:> children([]) . star(ELEMID,VRoot,Lnsb) ::= element(ELEMID,VRoot,Lnsb)^^E, star(ELEMID,VRoot,Lnsb)^^L <:> children([E|T]) ::- L^^children(T) .
5.6.3. Validation
5.7. Validating attributes
5.7.1. Generic rules for attribute-validation
sva_type_atts(TYPEID,Lras,VRoot,Lpa,Lpna,Lerr) :-
( type_property(type,TYPEID,complex)
; TYPEID = t_xsd_anySimpleType ),
lras(TYPEID,VRoot,LpaAll,Lras,[]),
LpaAll^^errors(Lerr0),
partition(LpaAll,LpaPres,Lpna),
attocc(TYPEID,LpaPres,Lpa,Lerr1),
append(Lerr0, Lerr1, Lerr).
{Validating attributes against types (2L) 393}
Continued in <Generic attribute rules, cont'd (2L) 394>, <Generic attribute rules, cont'd (2L) 395>This code is used in < Attribute handling for simple types (2L) 407 >
sva_type_atts(SimpleType, Lras, VRoot, Lpa, Lpna, Lerr) :- type_property(type,SimpleType,simple), once(sva_type_atts(t_xsd_anySimpleType,Lras, VRoot, Lpa, Lpna, Lerr)). /* If there is no type definition, there are not attribute * declarations. The validation required is the same as * for simple types, so we call that predicate. */ sva_type_atts(kw(absent), Lras, VRoot, Lpa, Lpna, Lerr) :- once(sva_type_atts(t_xsd_anySimpleType, Lras, VRoot, Lpa, Lpna, Lerr)).
This code is used in < Generic attribute rules (2L) 392 >
lras(_TYPEID,_VRoot) ::= []
<:> attributes([])
&& errors([]).
lras(TYPEID,VRoot) ::=
ras(TYPEID,VRoot)^^Pa,
lras(TYPEID,VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}
.
lras(TYPEID,VRoot) ::=
ras(nsd,VRoot)^^Pa,
lras(TYPEID,VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}
.
lras(TYPEID,VRoot) ::=
ras(xsi,VRoot)^^Pa,
lras(TYPEID,VRoot)^^Lpa
{Grammatical attributes for attribute-list recursion (PV) 226}
.
:- multifile ras/5.
ras(TYPEID,VRoot) ::= [Name=Value],
{ type_knownattributes(TYPEID,Latts),
attribute_unknown(Name,Latts) }
{Properties of unknown attributes (PV) 224}.
/* ras_nsd: grammatical rule for namespace-attribute
* specifications */
ras(nsd,_VRoot) ::= [xmlns=DefaultNS]
<:> info_item(attribute)
&& local_name(xmlns)
&& namespace_name('http://www.w3.org/2000/xmlns/')
&& normalized_value(DefaultNS)
&& prefix('##NONE')
&& namespace(DefaultNS)
&& errors([]).
ras(nsd,_VRoot) ::= [xmlns:Prefix=NSName]
<:> info_item(attribute)
&& local_name(Prefix)
&& namespace_name('http://www.w3.org/2000/xmlns/')
&& normalized_value(NSName)
&& prefix(Prefix)
&& namespace(NSName)
&& errors([]).
Continued in <Grammar rules for XSI attributes (2L) 397>This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
/* ras_xsi: grammar rule for XSI attribute specifications */
ras(xsi,VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':type=Value],
{ sva_type_plf(t_xsd_QName,Value,LF,_PN,Lerr) }
<:> local_name(type)
&& type_definition_name('QName')
&& type_definition_anonymous('false')
{Common properties for xsi attributes (PV) 236}
ras(xsi,VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':nil=Value],
{ sva_type_plf(t_xsd_boolean,Value,LF,_PN,Lerr) }
<:> local_name(nil)
&& type_definition_name('boolean')
&& type_definition_anonymous('false')
{Common properties for xsi attributes (PV) 236}
ras(xsi,VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':schemaLocation=Value],
{ sva_type_plf(t_xsd_list_anyURI,Value,LF,_PN,Lerr) }
<:> local_name(schemaLocation)
&& type_definition_name('t_a_schemaLocation')
&& type_definition_anonymous('true')
{Common properties for xsi attributes (PV) 236}
ras(xsi,VRoot) ::=
['http://www.w3.org/2001/XMLSchema-instance':noNamespaceSchemaLocation=Value],
{ sva_type_plf(t_xsd_anyURI,Value,LF,_PN,Lerr) }
<:> local_name(noNamespaceSchemaLocation)
&& type_definition_name('QName')
&& type_definition_anonymous('false')
{Common properties for xsi attributes (PV) 236}
atts_skip(Lnsb,Lras,Lpa,Lpna) :-
lras_skip(Lnsb,LpaAll,Lras,[]),
partition(LpaAll,Lpa,Lpna).
lras_skip(_Lnsb) ::= []
<:> attributes([]).
lras_skip(Lnsb) ::=
ras_skip(Lnsb)^^Pa,
lras_skip(Lnsb)^^Lpa
<:> attributes([Pa|L]) ::- Lpa^^attributes(L).
lras_skip(Lnsb) ::=
ras(nsd,Lnsb)^^Pa,
lras_skip(Lnsb)^^Lpa
<:> attributes([Pa|L]) ::- Lpa^^attributes(L).
ras_skip(_Lnsb) ::= [Attname=Attval],
{ Attname \= xmlns,
Attname \= xmlns:_Prefix,
name_parts(Attname,NS,Local)
}
<:> local_name(Local)
&& info_item(attribute)
&& namespace_name(NS)
&& normalized_value(Attval)
&& validation_attempted(none)
&& validity(notKnown)
.
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.7.2. Type-specific definitions of attributes
type_knownattributes(t_PurchaseOrderType,[orderDate]).
ras(t_PurchaseOrderType,VRoot) ::= [orderDate=Value],
{ sva_type_plf(t_xsd_date,Value,LF,_PN,Lerr) }
{Properties for orderDate attribute (PV) 221}.
Continued in <Attribute occurrences for PurchaseOrderType (2L) 400>This code is used in < Attribute rules for complex types (2L) 406 >
attocc(t_PurchaseOrderType,L,L,[]).
type_knownattributes(t_USAddress,[country]).
ras(t_USAddress,VRoot) ::= [country=Value],
{ sva_type_plf(t_xsd_NMTOKEN,Value,LF,_PN,Lerr0),
(LF = ['U', 'S']
-> Lerr = Lerr0
; Lerr = [error('cvc-attribute.4','Value does not match fixed value',
[val(Value), lf(LF), fixed('US')]) | Lerr0]) }
<:> info_item(attribute)
&& local_name('country')
&& namespace_name('')
&& normalized_value('US')
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')
&& type_definition_name('NMTOKEN')
&& type_definition_type(simple)
&& schema_default('US')
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid) ::- Lerr = []
&& validity(invalid) ::- Lerr \= []
&& schema_error_code(Lerr)
&& schema_normalized_value(LF)
&& validation_context(VRoot)
&& errors([])
.
Continued in <Attribute occurrence checking for USAddress (2L) 402>This code is used in < Attribute rules for complex types (2L) 406 >
attocc(t_USAddress,LpaPres,LpaAll,Lerr) :-
CountryAtt = node(
attribute(country),
[],
[ (info_item(attribute)),
(namespace_name('')),
(local_name('country')),
(normalized_value('US')),
(type_definition_anonymous('false')),
(type_definition_namespace(
'http://www.w3.org/2001/XMLSchema')),
(type_definition_name('NMTOKEN')),
(type_definition_type(simple)),
(schema_default('US')),
(schema_specified(schema)),
(validation_attempted(full)),
(validity(valid)),
(schema_error_code([])),
(schema_normalized_value(['U', 'S']))
]),
atts_defaulted(LpaPres,[CountryAtt],LpaAll,Lerr).
type_knownattributes(t_Items,[]). attocc(t_Items,L,L,[]).
This code is used in < Attribute rules for complex types (2L) 406 >
type_knownattributes(t_e_item_t_Items,[partNum]).
ras(t_e_item_t_Items,VRoot) ::= [partNum=Value],
{ sva_type_plf(t_SKU,Value,LF,_PN,Lerr) }
<:> info_item(attribute)
&& local_name('partNum')
&& namespace_name('')
&& normalized_value(Value)
&& type_definition_anonymous('false')
&& type_definition_namespace(
'http://www.example.com/PO1')
&& type_definition_name('SKU')
&& type_definition_type(simple)
&& schema_specified(infoset)
&& validation_attempted(full)
&& validity(valid) ::- Lerr = []
&& validity(invalid) ::- Lerr \= []
&& schema_error_code(Lerr)
&& schema_normalized_value(LF)
&& validation_context(VRoot)
&& errors([])
.
/* one required attribute: partNum */
attocc(t_e_item_t_Items,LpaPres,LpaAll,Lerr) :-
atts_present(LpaPres,['':partNum],Lerr0),
atts_absent(LpaPres,[],Lerr1),
atts_defaulted(LpaPres,[],LpaAll,Lerr2),
flatten([Lerr0,Lerr1,Lerr2],Lerr).
This code is used in < Attribute rules for complex types (2L) 406 >
type_knownattributes(t_xsd_anySimpleType,[]). attocc(t_xsd_anySimpleType,L,L,[]).
This code is used in < Attribute handling for simple types (2L) 407 >
5.7.3. Validation
/* Rules for validating attributes against complex types */
:- discontiguous type_knownattributes/2.
:- discontiguous ras/5.
:- multifile ras/5.
:- discontiguous attocc/4.
:- multifile attocc/4.
{DCTG rules for purchase-order attributes (2L) 399}
{Attribute rules for US address type (2L) 401}
{Attribute handling for Items type (2L) 403}
{Attribute handling for t_e_item_t_Items (2L) 404}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
:- discontiguous type_knownattributes/2.
:- discontiguous ras/5.
:- multifile ras/5.
:- discontiguous attocc/4.
:- multifile attocc/4.
{Generic attribute rules (2L) 392}
{Attribute handling for simple types (2L) 405}
This code is used in < DCTG for purchase order schema, layer 2L 268 >
{Utilities for checking attribute occurrences (PV) 237}
/* Venerable code from core layer */
{partition predicate 31}
This code is used in < Generic utilities for DCTG-encoded schemas (2L) 269 >
5.8. Miscellaneous
/* load_2l.pl: load the 2L DCTG grammar and other
* auxiliary material. */
{W3C copyright notice 86}
?- prolog_load_context(directory,Dir),
assert(file_search_path(po_bin,Dir)).
file_search_path(dctg,po_bin('..')).
file_search_path(po_tests,dctg('testdata/tests')).
file_search_path(po_out,dctg('testdata/tmp')).
file_search_path(po_lib,dctg('lib')).
?- ensure_loaded(po_lib('dctg_native.pl')).
?- ensure_loaded(library('http/http_open')).
?- ensure_loaded(po_bin('xsd_lib_2l.pl')).
?- ensure_loaded(po_bin('po_2l.pl')).
/* test_2l.pl: run tests on the 2L DCTG grammar */
{W3C copyright notice 86}
/* Consult this file, then run
*
* ?- run_tests.
*
* Use the predicates 'good', 'bad', 'ugly' to run valid, invalid, all.
* Use good(PSVI,Msglvl) etc. to control output:
* PSVI = psvi | nopsvi
* Msglvl = verbose | terse | silent
*/
?- prolog_load_context(directory,Dir),
assert(file_search_path(po_bin,Dir)).
?- ensure_loaded(po_bin('load_2l.pl')).
?- ensure_loaded(po_bin('coretests.pl')).
{Running one test (2L) 412}
{Error reports (PV) 266}
{Running one test (2L) 413}
/* run_test(File,Options): parse test File, compare result
* to expectations, report discrepancies */
run_test(File) :- run_test(File,[psvi(none), messages(terse)]).
run_test(File,Options0) :-
/* handle the options */
default_sva_options(Defaults),
set_sva_options(Options0,Defaults,Options),
option_value(messages,Options,Msglvl),
/* issue start message */
{Report at start of test (PV) 260},
/* run test */
potestfile(File,ExpectedRC),
absolute_file_name(po_tests(File),Testfile),
sevastopol(Testfile,PSVI,Valid,_VA,Options0),
!,
/* issue result message */
report_rc(Msglvl,ExpectedRC,Valid,File,PSVI),
!
.
{Report at end of test (PV) 261}
This code is used in < [File test_2l.pl] 411 >
good :- good([psvi(none), messages(terse)]). bad :- bad([psvi(none), messages(terse)]). ugly :- ugly([psvi(none), messages(terse)]). good(Options) :- run_tests(valid,Options). bad(Options) :- run_tests(invalid,Options). ugly(Options) :- run_tests(valid,Options), run_tests(invalid,Options). run_tests :- ugly. run_tests(RC,Options) :- bagof(File,potestfile(File,RC),Files), member(F,Files), run_test(F,Options), fail. run_tests(_RC,_Options). make_psvis :- make_psvis([messages(terse), psvi(full)]). make_psvis(Options) :- bagof(File,potestfile(File,_RC),Files), member(Filename0,Files), /* calculate an output file name and specify it as output option */ atom_concat(Stem,'.xml',Filename0), atom_concat(Stem,'.psvi.2L.xml',Filename1), absolute_file_name(po_out(Filename1),Filename), run_test(Filename0,[output(Filename)|Options]), fail. make_psvis(_Options).
This code is used in < [File test_2l.pl] 411 >
5.8.1. Reporting results of validation
report_results(V, VA, PSVI, Options) :-
report_messages(V, VA, PSVI, Options),
report_psvi(PSVI, Options).
report_messages(_V, _VA, _PSVI, Options) :-
option_value(messages,Options,silent).
report_messages(V, VA, PSVI, Options) :-
option_value(messages,Options,Msglvl),
Msglvl \= silent,
option_value(language,Options,Lang),
( PSVI^^type_definition_name(TDN)
; TDN = '[absent]'),
( PSVI^^type_definition_namespace(TDNS)
; TDNS = '[absent]'),
vmsg(Lang,Msglvl,V,VA,TDN,TDNS),
inspect_and_report(PSVI,Lang,Msglvl).
report_psvi(PSVI, Options) :-
/* someday we'll pay more attention to Flavor,
* but for now we just notice when it's 'none' */
option_value(psvi,Options,Flavor),
( Flavor = none
-> true
; ( option_value(output,Options,Output),
( Output = '-'
-> write_psvi(PSVI)
; ( telling(Stdout),
tell(Output),
write_psvi(PSVI),
told,
tell(Stdout), !)
)
)
).
{Overall validity message (2L) 417}
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
vmsg(en,verbose,V,VA,TDN,TDNS) :-
emsg(['The root element was validated against type {',
TDNS, '}', TDN, ' with the following results: \n',
'[validity] = "', V, '", [validation attempted] = "', VA,
'"'
]).
vmsg(en,terse,V,VA,TDN,TDNS) :-
emsg(['Root was ', V, ' against {',
TDNS, '}', TDN, ' (validation attempted: ',
VA, ').'
]).
vmsg(de,verbose,V,VA,TDN,TDNS) :-
emsg(['Die Gueltigkeit des Wurzelelements wurde gegen Typ {',
TDNS, '}', TDN, ' mit folgender Resultat geprueft: \n',
'[validity] = "', V, '", [validation attempted] = "', VA,
'"'
]).
vmsg(de,terse,V,VA,TDN,TDNS) :-
emsg(['Wurzelelement war ', V, ' gegen {',
TDNS, '}', TDN, ' (validation attempted: ',
VA, ').'
]).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
emsg([H|T]) :- concat_atom([H|T],Msg), emsg(Msg). emsg(Msg) :- atom(Msg), current_stream(2, write, Stream), write(Stream,Msg), nl(Stream).
This code is used in < Initiating schema-validity assessment, generic (2L) 317 >
inspect_and_report(Node,Lang,Msglvl) :- ir(Node,'/1',Lang,Msglvl). ir(Node,Tumbler,Lang,Msglvl) :- /* do reports in post-order traversal */ Node ^^ attributes(LPa), ir_atts(LPa, Tumbler, Lang, Msglvl), Node ^^ children(LCh), ir(LCh, Tumbler, 0, Lang, Msglvl), ir_element(Node, Tumbler, Lang, Msglvl).Continued in <Recurring on attributes (2L) 418>, <Recurring on the children (2L) 419>, <Reporting one element (2L) 420>, <Element status message (2L) 421>, <Reporting error codes (2L) 422>, <Reporting one attribute (2L) 423>
This code is used in < Reporting validation results (2L) 414 >
ir_atts([], _, _, _). ir_atts([A|As], Tumbler, Lang, Msglvl) :- ir_attribute(A, Tumbler, Lang, Msglvl), ir_atts(As, Tumbler, Lang, Msglvl).
ir([], _, _, _, _). ir([N|Ns], Tumbler0, Num0, Lang, Msglvl) :- N ^^ info_item(element), integer(Num0), Num is Num0 + 1, concat_atom([Tumbler0,'/',Num], Tumbler), ir(N, Tumbler, Lang, Msglvl), ir(Ns,Tumbler0, Num, Lang, Msglvl). ir([N|Ns], Tumbler, Num, Lang, Msglvl) :- ( N ^^ info_item(textnode) ; N ^^ info_item(pi) ; atom(N) ), ir(Ns, Tumbler, Num, Lang, Msglvl).
ir_element(Node, Tumbler, Lang, Msglvl) :-
Node ^^ validity(V),
( V = valid
-> true
; ( ir_element_report(Lang, Msglvl, V, Tumbler, Node),
( Node ^^ schema_error_code(Lerr)
-> ir_errors_report(Lerr, Lang, Msglvl, Tumbler)
; true
)
)
).
/* ir_element_report: say what's up with this one element */
/* if message level = 'silent', say nothing, otherwise ... */
ir_element_report(_L, silent, _V, _Tumbler, _Node).
ir_element_report(en, verbose, invalid, Tumbler, Node) :-
Node ^^ namespace_name(NS),
Node ^^ local_name(LN),
emsg(['Error at element(', Tumbler, '), {', NS, '}', LN]).
ir_element_report(en, verbose, notKnown, Tumbler, Node) :-
Node ^^ namespace_name(NS),
Node ^^ local_name(LN),
emsg(['Unknown validity at element(', Tumbler, '), {', NS, '}', LN]).
ir_element_report(en, terse, invalid, Tumbler, _Node) :-
emsg(['Error at element(', Tumbler, ')']).
ir_element_report(en, terse, notKnown, _Tumbler, _Node).
ir_element_report(de, verbose, invalid, Tumbler, Node) :-
Node ^^ namespace_name(NS),
Node ^^ local_name(LN),
emsg(['Gueltigkeitsfehler in Element ', Tumbler, ', {', NS, '}', LN]).
ir_element_report(de, verbose, notKnown, Tumbler, Node) :-
Node ^^ namespace_name(NS),
Node ^^ local_name(LN),
emsg(['Unbekannte Gueltigkeit in Element ', Tumbler, ', {', NS, '}', LN]).
ir_element_report(de, terse, invalid, Tumbler, _Node) :-
emsg(['Fehler: element(', Tumbler, ')']).
ir_element_report(de, terse, notKnown, _Tumbler, _Node).
ir_errors_report([], _, _, _). ir_errors_report([error(Code, Desc, Details)|Lerr], Lang, Msglvl, Tumbler) :- emsg([' ', Code, ': ', Desc]), (member(ce(Lerr1), Details) -> ir_errors_report(Lerr1, Lang, Msglvl, Tumbler) ; true), ir_errors_report(Lerr, Lang, Msglvl, Tumbler).
ir_attribute(A, Tumbler, Lang, Msglvl) :-
A^^validity(V),
( V = valid
-> true
; ( ir_attribute_report(Lang, Msglvl, V, Tumbler, A),
( A^^schema_error_code(Lerr)
-> ir_errors_report(Lerr, Lang, Msglvl, Tumbler)
; true ))
).
attnode_attname(Node,AN) :-
Node ^^ namespace_name(NS0),
Node ^^ local_name(LN),
(NS0 \= ''
-> concat_atom(['{',NS0,'}', LN], AN)
; AN = LN).
ir_attribute_report(_L, silent, _V, _Tumbler, _Node).
ir_attribute_report(en, verbose, invalid, Tumbler, Node) :-
attnode_attname(Node, AN),
emsg(['Error at attribute ', AN, ' of element(', Tumbler, ')']).
ir_attribute_report(en, verbose, notKnown, Tumbler, Node) :-
attnode_attname(Node, AN),
emsg(['Unknown validity at attribute ', AN, ' of element(', Tumbler, ')']).
ir_attribute_report(en, terse, invalid, Tumbler, Node) :-
attnode_attname(Node, AN),
emsg(['Error at element(', Tumbler, ')/@', AN]).
ir_attribute_report(en, terse, notKnown, _Tumbler, _Node).
ir_attribute_report(de, verbose, invalid, Tumbler, Node) :-
attnode_attname(Node, AN),
emsg(['Gueltigkeitsfehler im Attribut ', AN, 'vom Element ', Tumbler]).
ir_attribute_report(de, verbose, notKnown, Tumbler, Node) :-
attnode_attname(Node, AN),
emsg(['Unbekannte Gueltigkeit im Attribute ', AN, 'vom Element ', Tumbler]).
ir_attribute_report(de, terse, invalid, Tumbler, Node) :-
attnode_attname(Node, AN),
emsg(['Fehler: element(', Tumbler, '), Attribut ', AN]).
ir_attribute_report(de, terse, notKnown, _Tumbler, _Node).
5.9. Evaluation
| Grammar | Time to parse | |||
|---|---|---|---|---|
| Test suite (75 documents) | One document | |||
| DCG | 9.362 s | 125 ms | 0.277 s | 4 ms |
| Core | 13.837 s | 184 ms | 0.750 s | 10 ms |
| PV | 20.111 s | 268 ms | 1.760 s | 23 ms |
| 2L | 25.744 s | 343 ms | 2.665 s | 36 ms |
- Providing a single boolean value is fast and cheap.
- It costs time to calculate a full PSVI, even if it is not dumped. (So code which never calculates a PSVI will tend to be faster than code that does.) This explains the higher times of the core grammar (which provides PSVI information for valid documents) over the DCG grammar (which provides none). It also explains part of the speed advantage held by the core grammar over PV: PV provides PSVI for invalid documents.
- Partial validation has a cost, because it means the process cannot fail immediately upon seeing the first invalidity, but must continue to the end of the input document. This is responsible for part of the difference between Core and PSVI.
- A hard-coded grammar in which element names and type names are part of non-terminal names is faster than a more general grammar in which they are passed as parameters. This is, I believe, the reason for the speed difference between PV and 2L.
- Where does the time go, in each of these grammars? The SWI Prolog tool may provide answers.
- How much of the difference between Core and PV is due to PV not being able to fail early, and how much to the PSVI?
- Does the late calculation of DCTG attributes (i.e. the specification of attribute values by means of rules which are evaluated when the attribute value is sought) affect speed? If the attribute values are never calculated, presumably it increases speed (although it may also increase memory usage, which may slow things down). If they are calculated more than once, presumably it slows things down. Would pre-calculation of all values help or hurt?
- Does the list-based behavior of the ^^ operator hurt performance? Would an attribute discipline similar to the one used for options (with positional values) be faster?
- Is there a speed difference between DCGs and DCTGs, for the same functionality? (N.B. since DCGs will precalculate all attribute values and use a positional scheme for keeping track of them, both of the preceding points should be examined first within the context of DCTGs alone. (Since the two points at issue constitute the main reasons for using DCTGs instead of DCGs, however, if pre-calculation and positional attributes are faster, DCGs may be preferred to DCTGs even if they are not faster in themselves.
- If DCGs are faster, how can we solve, in a DCG, the problems that led us to switch to DCTGs in the first place?
- If the indirection of 2L is (necessarily?) slower than hard-coding non-terminal names, then is there any way to support xsi:type and lax validation and mixed content in a grammar which for the most part uses hard-coded non-terminals?
6. Notes on other features of XML Schema
6.1. Handling xsi:type
element(ED_declared, VRoot, Lnsb0) ::=
[element(GI, Lras, Lre)],
{
eii_match_decl_decl(GI,ED_declared,ED),
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_eii(ED,element(GI,Lras,Lre),Lnsb,Type0,Lerr0),
local_vs_declared(Type0,Lras,Type,Lerr1),
( Lerr1 = []
-> ( once(sva_type_atts(Type,Lras,VRoot,Lpa,Lpna,Lerr2)),
sva_type_content(Type,VRoot,Lnsb,Lre,Lpe,Lerr3)
)
/* if Lerr1 is not [], we do not have a good type and
* cannot proceed */
)
}
6.2. Fallback to lax processing
6.3. Supporting wildcards with skip and lax processing
wildcard(strict,NSconstraint, VRoot, Lnsb0) ::=
[element(GI, Lras, Lre)],
{
name_parts(GI,NS,LN),
ns_wildcard_match(NS,NSconstraint),
elemdecl(ED_declared, _SCD, LN, NS, global, _Props),
element(ED_declared, VRoot, Lnsb0, PN, [element(GI, Lras, Lre)], [])
}
If the predicate ns_wildcard_match does not succeed,
then the wildcard does not match and the rule fails.
wildcard(strict,NSconstraint, VRoot, Lnsb0) ::=
[element(GI, Lras, Lre)],
{
name_parts(GI,NS,LN),
ns_wildcard_match(NS,NSconstraint),
( elemdecl(ED_declared, _SCD, LN, NS, global, _Props)
-> element(ED_declared, VRoot, Lnsb0, PN, [element(GI, Lras, Lre)], [])
; content_lax(VRoot, Lnsb0, PN, [element(GI, Lras, Lre)], [])
)
}
wildcard(strict,NSconstraint, VRoot, Lnsb0) ::=
[element(GI, Lras, Lre)],
{
name_parts(GI,NS,LN),
ns_wildcard_match(NS,NSconstraint),
content_skip(VRoot, Lnsb0, PN, [element(GI, Lras, Lre)], [])
}
6.4. Supporting xsi:nil
6.5. Numeric exponents in content models
rep(0,_Max,_ELEMID,_VRoot,_Lnsb) ::= []
<:> children([]).
rep(Min,Max,ELEMID,VRoot,Lnsb) ::=
{ ( Max == unbounded ; Max > 0 ),
decrement(Min,Newmin),
decrement(Max,Newmax)
}
element(ELEMID,VRoot,Lnsb)^^EC,
rep(Newmin,Newmax,ELEMID,VRoot,Lnsb)^^Rell
<:> children([EC|ECs]) ::- Rell^^children(ECs).
6.6. Mixed content
6.6.1. Filtering the children
element(ED_declared, VRoot, Lnsb0) ::=
[element(GI, Lras, Lre)],
{
eii_match_decl_decl(GI,ED_declared,ED),
inscope_namespaces(Lnsb0, Lras, Lnsb),
sva_elemdecl_eii(ED,element(GI,Lras,Lre),Lnsb,Type,Lerr0),
/* check; mixed or element-only? */
type_property(content_type(c_model(_,FlagMixEO))),
once(sva_type_atts(Type,Lras,VRoot,Lpa,Lpna,Lerr1)),
/* filter out child elements, check text nodes to
* make sure they are whitespace only if type is
* element-only */
filter_children(FlagMixEO,Lre,Lsubelements,Lerr2),
sva_type_content(Type,VRoot,Lnsb,Lsubelements,Lpe0,Lerr3),
/* recombine parsed children with text nodes in Lpe */
re_interleave(Lre,Lpe0,Lpe)
}
It might be better to avoid the need for the
re_interleave predicate by moving the validation of
child elements out of the element rule and invoking it
separately, not on individual elements but on the list of children; it
would return a list of parsed nodes interleaved with text nodes.6.6.2. Using second-level parsers
6.7. Other features
- validation startup options: allowing the user to specify an element other than the document root as the starting point for schema-validity assessment; allowing the user to specify a type to which the validation root must conform; allowing the user to specify an element declaration to which the validation root must conform.
- abstract types: when they are present, the validation code must ensure that they are not used to validate an element or attribute
- identity constraints
- notations
- the remaining primitive types (Sevastopol only includes the types needed for the purchase-order schema)
- schema annotations
- attribute groups, named model groups
- schema composition (schema documents, schema location, include, import, redefine)
- validity of schema itself
7. Conformance claim
- The core grammar provides PSVI information only for valid documents; for invalid documents it only provides the information that they are invalid. The PSVI properties provided for valid documents are listed in section 2.
- The PV grammar provides PSVI information for all documents; the properties provided are listed in sections 4.3.6 and 4.4.
- The 2L grammar can be invoked in different ways; when the full PSVI is requested, it provides the same information as the PV grammar. Otherwise, it provides just information about validity and validation attempted of the document's root element, with error messages indicating error codes.
8. Further work
- implement the schema component constraints (see Appendix C.4 and subsection 6 of each component) I take this to mean that the schemas used by the processor must obey them; the processor may or may not independently enforce them. Proof obligation: prove that the style of DCTG outlined above does satisfy these constraints.
- implement the validation rules (see Appendix C.1 and subsection 4 of each component). I take this to mean the processor must work correctly from its component representation to the values of the relevant PSVI instance properties. Proof obligation: prove that the style of DCTG outlined above does correctly implement the validation rules.
- implement (i.e. make) the schema information set contributions (see Appendix C.2 and subsection 5 of each component). Proof obligation: make the parser decorate the input with appropriate grammatical attributes representing the relevant properties.
A. Works cited and further reading
Works cited
Abramson, Harvey. 1984. “Definite Clause Translation Grammars”. Proceedings of the 1984 International Symposium on Logic Programming, Atlantic City, New Jersey, February 6-9, 1984, pp. 233-240. (IEEE-CS 1984, ISBN 0-8186-0522-7)
Abramson, Harvey, and Veronica Dahl. 1989. Logic Grammars. Symbolic Computation AI Series. Springer-Verlag, 1989.
Abramson, Harvey, and Veronica Dahl, rev. Jocelyn Paine. 1990. DCTG: Prolog definite clause translation grammar translator. (Prolog code for translating from DCTG notation to standard Prolog. Note says syntax extended slightly by Jocelyn Paine to accept && between specifications of grammatical attributes, to minimize need for parentheses. Available from numerous AI/NLP software repositotries, including <URL:http://www-2.cs.cmu.edu/afs/cs/project/ai-repository/ai/lang/prolog/code/syntax/dctg/0.html>, <URL:http://www.ims.uni-stuttgart.de/ftp/pub/languages/prolog/libraries/imperial_college/dctg.tar.gz>, and <URL:http://www.ifs.org.uk/~popx/prolog/dctg/>.)
Alblas, Henk. 1991. “Introduction to attribute grammars”. Attribute grammars, applications and systems: International Summer School SAGA, Prague, Czechoslovakia, June 4-13, 1991, Proceedings, pp. 1-15. Berlin: Springer, 1991. Lecture Notes in Computer Science, 545.
Bratko, Ivan. 1990. Prolog programming for artificial intelligence. Second edition. Wokingham: Addison-Wesley. xxi, 597 pp.
Brown, Allen L., Jr., and Howard A. Blair. 1990. “A logic grammar foundation for document representation and layout”. In EP90: Proceedings of the International Conference on Electronic Publishing, Document Manipulation and Typography, ed. Richard Furuta. Cambridge: Cambridge University Press, 1990, pp. 47-64.
Brown, Allen, Matthew Fuchs, Jonathan Robie, and Philip Wadler. 2001. “XML Schema: Formal Description”. W3C Working Draft, 25 September 2001. [Cambridge, Sophia-Antipolis, and Tokyo]: World Wide Web Consortium. <URL:http://www.w3.org/TR/xmlschema-formal/>
Brown, Allen L., Jr., Toshiro Wakayama, and Howard A. Blair. 1992. “A reconstruction of context-dependent document processing in SGML”. In EP92: Proceedings of Electronic Publishing, 1992, ed. C. Vanoirbeek and G. Coray. Cambridge: Cambridge University Press, 1992. Pages 1-25.
Brüggemann-Klein, Anne. 1993. Formal models in document processing. Habilitationsschrift, Freiburg i.Br., 1993. 110 pp. Available at <URL:ftp://ftp.informatik.uni-freiburg.de/documents/papers/brueggem/habil.ps> (Cover pages archival copy also at <URL:http://www.oasis-open.org/cover/bruggDissert-ps.gz>).
Clocksin, W. F., and C. S. Mellish. 1984. Programming in Prolog. Second edition. Berlin: Springer, 1984.
Dershowitz, Nachum, and Edward M. Reingold. 1997. Calendrical calculations. Cambridge: CUP, 1997.
Gal, Annie, Guy Lapalme, Patrick Saint-Dizier, and Harold Somers. 1991. Prolog for natural language processing. Chichester: Wiley, 1991. xiii, 306 pp.
Gazdar, Gerald, and Chris Mellish. 1989. Natural language processing in PROLOG: An introduction to computational linguistics. Wokingham: Addison-Wesley, 1989. xv, 504 pp.
Grune, Dick, and Ceriel J. H. Jacobs. 1990. Parsing techniques: a practical guide. New York, London: Ellis Horwood, 1990. Postscript of the book is available from the first author's Web site at <URL:http://www.cs.vu.nl/~dick/PTAPG.html>
Holstege, Mary, and Asir S. Vedamuthu, ed. 2003. XML Schema: Component Designators. W3C Working Draft 09 January 2003. [Cambridge, Sophia-Antipolis, and Tokyo]: World Wide Web Consortium. <URL:http://www.w3.org/TR/2003/WD-xmlschema-ref-20030109/>
Holstege, Mary, and Asir S. Vedamuthu, ed. 2005. XML Schema: Component Designators. W3C Working Draft 29 March 2005. [Cambridge, Sophia-Antipolis, and Tokyo]: World Wide Web Consortium. <URL:http://www.w3.org/TR/xmlschema-ref/>
Knuth, D. E. 1968. “Semantics of context-free languages”. Mathematical Systems Theory 2: 127-145.
König, Esther, and Roland Seiffert. 1989. Grundkurs PROLOG für Linguisten. Tübingen: Francke. [= Uni-Taschenbücher 1525]
O'Keefe, Richard A. 1990. The Craft of Prolog. Cambridge: MIT Press.
Pereira, Fernando C. N., and Stuart M. Shieber, Prolog and natural-language analysis. CSLI lecture notes 10. Stanford: Center for the study of language and information, 1987.
Sperberg-McQueen, C. M. 2002. “ Canonical XML forms for post-schema-validation infosets: A preliminary reconnaissance”. Working paper prepared for the W3C XML Schema Working Group. 24 April 2002. <URL:http://www.w3.org/2002/04/xmlschema-psvi-in-xml>
Sperberg-McQueen, C. M. 2004a. “A brief introduction to definite clause grammars and definite clause translation grammars”. Working paper prepared for the W3C XML Schema Working Group.
Sperberg-McQueen, C. M. 2004b. “A definite-clause grammar representation of an XSD schema”. Working paper prepared for the W3C XML Schema Working Group.
Sperberg-McQueen, C. M. 2005. “Applications of Brzozowski derivatives to XML Schema processing”. Paper given at the Extreme Markup Languages 2005 conference sponsored by IDEAlliance, Montréal, August 2005. Available on the Web at <URL:http://www.mulberrytech.com/Extreme/Proceedings/html/2005/SperbergMcQueen01/EML2005SperbergMcQueen01.html>, <URL:http://www.w3.org/People/cmsmcq/2005/abdxsp.unicode.html>, and <URL:http://www.w3.org/People/cmsmcq/2005/abdxsp.ascii.html>.
Stepney, Susan. High-integrity compilation. Prentice-Hall. Available from <URL:http://www-users.cs.york.ac.uk/~susan/bib/ss/hic/index.htm>. Chapter 3 (Using Prolog) provides a terse introduction to DCTG notation and use.
Sterling, Leon, and Ehud Shapiro. 1994. The Art of Prolog: Advanced Programming Techniques. Cambridge, Mass.: MIT Press.
W3C (World Wide Web Consortium). 2001a. “XML Schema Part 0: Primer”, ed. David Fallside. W3C Recommendation, 2 May 2001. [Cambridge, Sophia-Antipolis, Tokyo: W3C] <URL:http://www.w3.org/TR/xmlschema-0/>.
W3C (World Wide Web Consortium). 2001b. XML Schema Part 1: Structures, ed. Henry S. Thompson, David Beech, Murray Maloney, and Noah Mendelsohn. W3C Recommendation 2 May 2001. [Cambridge, Sophia-Antipolis, and Tokyo]: World Wide Web Consortium. <URL:http://www.w3.org/TR/2001/REC-xmlschema-1-20010502/>
W3C (World Wide Web Consortium). 2001c. XML Schema Part 2: Datatypes, ed. Biron, Paul V. and Ashok Malhotra. W3C Recommendation 2 May 2001. [Cambridge, Sophia-Antipolis, and Tokyo]: World Wide Web Consortium. <URL:http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/>
Wadler, Philip. “A formal semantics of patterns in XSLT and XPath.” Markup Languages: Theory & Practice 2.2 (2000): 183-202.
Wielemaker, Jan. “SWI-Prolog SGML/XML parser: Version 1.0.14, March 2001”. <URL:http://www.swi-prolog.org/packages/sgml2pl.html>
Further reading
B. The test cases
/* coretests: simple one-item test routine for SWI Prolog
*
* This DCG was generated by a literate programming system; if
* maintenance is necessary, make changes to the source (podctg.xml),
* not to this output file.
*/
{W3C copyright notice 86}
?- prolog_load_context(directory,Dir),
assert(file_search_path(po_bin,Dir)).
/* grammar_version(KW,File) : File contains the grammar known as KW. */
grammar_version(core,po_bin('po_core.pl')).
grammar_version(pv,po_bin('po_pv.pl')).
grammar_version('2l',po_bin('po_2l.pl')).
grammar_version(fb,po_bin('po_fb.pl')).
potestfile('po1.xml', 'valid').
potestfile('po1v10a.xml', 'valid').
potestfile('po1v25.xml', 'valid').
potestfile('po1v33.xml', 'valid').
potestfile('po1v38.xml', 'valid').
potestfile('po1v62d.xml', 'valid').
potestfile('po1v65.xml', 'valid').
potestfile('po1v79.xml', 'valid').
potestfile('po1v80.xml', 'valid').
potestfile('po1v100a.xml','valid').
potestfile('po1v100b.xml','valid').
potestfile('po1v121.xml', 'valid').
potestfile('po1v124.xml', 'valid').
potestfile('po1v128.xml', 'valid').
potestfile('po1v130.xml', 'valid').
potestfile('po1e04.xml', 'invalid').
potestfile('po1e13.xml', 'invalid').
potestfile('po1e14.xml', 'invalid').
potestfile('po1e15.xml', 'invalid').
potestfile('po1e15a.xml', 'invalid').
potestfile('po1e15b.xml', 'invalid').
potestfile('po1e15c.xml', 'invalid').
potestfile('po1e16.xml', 'invalid').
potestfile('po1e16b.xml', 'invalid').
potestfile('po1e18.xml', 'invalid').
potestfile('po1e19.xml', 'invalid').
potestfile('po1e20.xml', 'invalid').
potestfile('po1e20b.xml', 'invalid').
potestfile('po1e27.xml', 'invalid').
potestfile('po1e28.xml', 'invalid').
potestfile('po1e28b.xml', 'invalid').
potestfile('po1e30.xml', 'invalid').
potestfile('po1e31.xml', 'invalid').
potestfile('po1e32.xml', 'invalid').
potestfile('po1e35.xml', 'invalid').
potestfile('po1e36.xml', 'invalid').
potestfile('po1e41.xml', 'invalid').
potestfile('po1e42.xml', 'invalid').
potestfile('po1e43.xml', 'invalid').
potestfile('po1e44.xml', 'invalid').
potestfile('po1e46.xml', 'invalid').
potestfile('po1e47.xml', 'invalid').
potestfile('po1e48.xml', 'invalid').
potestfile('po1e50.xml', 'invalid').
potestfile('po1e51.xml', 'invalid').
potestfile('po1e52.xml', 'invalid').
potestfile('po1e55.xml', 'invalid').
potestfile('po1e56.xml', 'invalid').
potestfile('po1e62.xml', 'invalid').
potestfile('po1e62b.xml', 'invalid').
potestfile('po1e62c.xml', 'invalid').
potestfile('po1e63.xml', 'invalid').
potestfile('po1e64.xml', 'invalid').
potestfile('po1e68.xml', 'invalid').
potestfile('po1e70.xml', 'invalid').
potestfile('po1e70b.xml', 'invalid').
potestfile('po1e78.xml', 'invalid').
potestfile('po1e81.xml', 'invalid').
potestfile('po1e86.xml', 'invalid').
potestfile('po1e87.xml', 'invalid').
potestfile('po1e88.xml', 'invalid').
potestfile('po1e89.xml', 'invalid').
potestfile('po1e91.xml', 'invalid').
potestfile('po1e92.xml', 'invalid').
potestfile('po1e101a.xml', 'invalid').
potestfile('po1e101b.xml', 'invalid').
potestfile('po1e101c.xml', 'invalid').
potestfile('po1e101d.xml', 'invalid').
potestfile('po1e105bisa.xml','invalid').
potestfile('po1e105bisb.xml','invalid').
potestfile('po1e106.xml', 'invalid').
potestfile('po1e109.xml', 'invalid').
potestfile('po1e113.xml', 'invalid').
potestfile('po1e114.xml', 'invalid').
potestfile('po1e116.xml', 'invalid').
potestfile('po1e122a.xml', 'invalid').
potestfile('po1e122b.xml', 'invalid').
potestfile('po1e122c.xml', 'invalid').
potestfile('po1e125a.xml', 'invalid').
potestfile('po1e125b.xml', 'invalid').
potestfile('po1e125c.xml', 'invalid').
potestfile('po1e125d.xml', 'invalid').
potestfile('po1e125e.xml', 'invalid').
potestfile('po1e125f.xml', 'invalid').
potestfile('po1e127a.xml', 'invalid').
potestfile('po1e127b.xml', 'invalid').
potestfile('po1e129.xml', 'invalid').
potestfile('po1e131a.xml', 'invalid').
potestfile('po1e131b.xml', 'invalid').
potestfile('po1e132.xml', 'invalid').
cd ~/2003/schema/dctg $ /cygdrive/d/usr/src/pl/bin/plcon.exe -f potests.pl -g 'one(current)' -t haltor
$ /cygdrive/d/usr/src/pl/bin/plcon.exe \ > -f d:/home/cmsmcq/2002/Prolog/potest.pl \ > -g 'good(current)' -t haltThe command line might be simpler if Prolog has a good search path, but I haven't gotten around to that yet.
C. Regression testing
#!/bin/bash
### regression_test.sh: test purchase-order schema validators
### for new errors or inconsistent changes.
{W3C copyright notice 87}
fMsglvl=$1
cd /home/cmsmcq/2005/schema/dctg
### First, check all grammars superficially:
function runall ()
{
echo "Running $2 tests on $1 ..."
STDOUT=testdata/tmp/tests.$1.$2.stdout
STDERR=testdata/tmp/stderr.$1.$2.stderr
time bash Prolog/runtests.sh $1 $2 tty > $STDOUT 2>$STDERR
diff -s testdata/ref/reference.$1.$2.stdout $STDOUT
if [ $? -ne 0 ] ; then
exit $?
else
rm -f $STDOUT $STDERR
fi
echo ""
return
}
runall core all
runall pv all
runall 2L all
### Next, generate and diff the PSVI files for core, PV, and 2L
### and diff them with the reference copies
ASN=~/lib/prolog/attseq_normalize.pl
function checkpsvi ()
{
echo "Generating PSVI using $1 grammar"
OUT=testdata/tmp/psvi.$1.stdout
ERR=testdata/tmp/stderr.psvi.$1.stderr
pl -f Prolog/$2 -g $3 -t halt > $OUT 2> $ERR
OUTN=testdata/tmp/psvi.$1.normalize.stdout
ERRN=testdata/tmp/stderr.psvi.$1.normalize.stderr
if [ "$fMsglvl" = "verbose" ] ; then
echo "Normalizing PSVI files for $1"
fi
for f in testdata/tmp/po*psvi.$1.xml
do pl -f $ASN -g "attseq_normalize('$f','${f%.xml}.normalized.xml')" -t halt
done > $OUTN 2> $ERRN
FSAVE=0
for f in testdata/psvi$1/po*normalized.xml;
do g=${f##*/}
### echo $g
diff -q $f testdata/tmp
if [ $? -eq 0 ] ; then
rm -f testdata/tmp/$g
rm -f testdata/tmp/${g%.normalized.xml}.xml
else
echo "$g differs from reference copy"
FSAVE=1
fi
done
if [ $FSAVE -eq 0 ] ; then
rm -f $OUT $OUTN $ERR $ERRN
fi
echo
}
### do it
checkpsvi core test_core.pl "good(psvi)"
checkpsvi pv test_pv.pl "ugly(psvi,terse)"
checkpsvi 2L test_2l.pl "make_psvis"
exit 0
D. SWI Prolog handling of characters
- named general entity reference in document for
single character (defined by using numeric character
reference):
- ntilde (defined as ñ): represented directly (code 241)
- lsquo and rsquo (defined as ‘ and ’): represented as entity(lsquo) and entity(rsquo)
- numeric character reference in document:
- 241 (ntilde): represented directly (code 241)
- U+2018, U+2019 (lsquo and rsquo): represented as entity(8216) and entity(8217)
- larger general entities with non-ASCII characters in the
replacement text:
- using named entities: top-level entity is expanded; within the expansion, ntilde and the sinqle quotes treated as described above (named entities)
- using numeric character references: top-level entity is expanded; within the expansion, ntilde and the sinqle quotes treated as described above (numeric references)
- UTF-8 (entire document translated to UTF-8, no entity or
character references involved):
- ntilde shows up as character 241
- lsquo and rsquo show up as characters 24 and 25 (n.b. 24 = 8216 mod 256)
E. Error codes for elements and attributes
Schema-validity assessment
- cvc-assess-elt.1.1.1 schema-validity not assessed: no element declaration known for this element
- cvc-assess-elt.1.1.2 schema-validity not assessed: element was not validated w.r.t. its element declaration (Element Locally Valid was not run).
- cvc-assess-elt.1.1.3 schema-validity not assessed: the necessary type definition was absent [Should normally be accompanied by error code cvc.type.1.]
- cvc-assess-elt.1.2.1 schema-validity not assessed: the type definition needed to validate this element was either unknown or absent
- cvc-assess-elt.1.2.1.2.2 schema-validity not assessed: an xsi:type attribute was present, but its value was not a valid QName
- cvc-assess-elt.1.2.1.2.3 schema-validity not assessed: an xsi:type attribute was present, but its value did not resolve to any known type definition
- cvc-assess-elt.1.2.1.2.4 schema-validity not assessed: an xsi:type attribute was present, but the type it denotes is not validly derived from the type stipulated by the processor at run time
- cvc-assess-elt.1.2.2 schema-validity not assessed: element was not validated w.r.t. either the processor-stipulated type or the local (xsi:type-specified) type definition
- cvc-assess-elt.2 schema-validity not assessed: either there were children which were not assessed, or attributes which were not assessed. [Should be accompanied by one or more errors from cvc-assess-elt for the children, or cvc-assess-attr for the attributes.]
Elements: local validity
- cvc-elt.1 element is not locally valid: no element declaration found
- cvc-elt.2 element is not locally valid: element is declared abstract
- cvc-elt.3.1 element is not locally valid, element is declared non-nillable, but there is an xsi:nil attribute present (it doesn't matter what value that attribute had, it's legal only on nillable elements)
- cvc-elt.3.2.1 element is not locally valid, it's nillable and has xsi:nil="true", but the element is not empty.
- cvc-elt.3.2.2 element is not locally valid, it's nillable and has xsi:nil="true", but it has a fixed {value constraint}.
- cvc-elt.4.1 element is not locally valid, it has xsi:type but the value is not a valid QName. [Should also have a cvc-simple-type error.]
- cvc-elt.4.2 element is not locally valid, it has xsi:type but the value does not resolve to a known type. [Should also have a cvc-resolve-instance error.]
- cvc-elt.4.3 element is not locally valid, it has xsi:type but the type named is not validly derived from the declared type. [Should also have a cos-ct-derived-ok error or a cos-st-derived-ok error.]
- cvc-elt.5.1.1 element is not locally valid; it is empty and non-nil and has a {value constraint}, but the default value is not a legal value for the local type. [Should also have a cos-valid-default error.]
- cvc-elt.5.1.2 element is not locally valid; it is empty and non-nil and has a {value constraint}, but the element (after supplying the default value) is not locally valid according to the actual type definition. [Should also have a cvc-type error.]
- cvc-elt.5.2.1 element is not locally valid; failed Element Locally Valid (Type) (cvc-type). [Should also have a cvc-type error.]
- cvc-elt.5.2.2.1 element is not locally valid; it has both a fixed value and element children.
- cvc-elt.5.2.2.2.1 element is not locally valid; the initial value of its mixed content does not match the canonical lexical representation of the fixed value in the actual declaration.
- cvc-elt.5.2.2.2.2 element is not locally valid; the actual value it contains does not match the canonical lexical representation of the fixed value in the actual declaration.
- cvc-elt.6 element is not locally valid; failed an identity-constraint. [Should also have a cvc-identity-constraint error.]
- cvc-elt.7 element is not locally valid; it's the validation root, but failed the ID/IDREF check. [Should also have a cvc-id error.]
- cvc-type.1 element is not locally valid: no type definition found.
- cvc-type.2 element is not locally valid: its type definition has abstract="true".
- cvc-type.3.1.1 element is not locally valid: its type definition is simple, but it has attributes other than xsi:type, xsi:nil, xsi:schemaLocation, and xsi:noNamespaceSchemaLocation.
- cvc-type.3.1.2 element is not locally valid: its type definition is simple, but it has element children.
- cvc-type.3.1.2 element is not locally valid: its content is not a legal lexical form for its simple type. [Should also have a cvc-simple-type error code.]
- cvc-type.3.2 element is not locally valid: it is not valid with respect to its complex type. [Should also have a cvc-complex-type error code.]
Validity with respect to a complex type
- cvc-complex-type.1 element not locally valid: complex type does not have abstract="false".
- cvc-complex-type.2.1 element not locally valid: complex type is declared empty (has {content type} of empty) but the element is not empty. [Applies only if non-nil.]
- cvc-complex-type.2.2 element not locally valid: complex type is derived from a simple type (has a simple type as its {content type}) but the element has element children. [Applies only if non-nil.]
- cvc-complex-type.2.2 element not locally valid: complex type is derived from a simple type (has a simple type as its {content type}) but the element is not valid w.r.t. that simple type. [Should also have cvc-simple-type error code.] [Applies only if non-nil.]
- cvc-complex-type.2.3 element not locally valid: complex type has {content type} element-only, but the element has non-whitespace characters between child elements. [Applies only if non-nil.]
- cvc-complex-type.2.4 element not locally valid: the sequence of element children does not match the content model. [Should also have one or more cvc-particle errors.] [Applies only if non-nil.]
- cvc-complex-type.3.1 element not locally valid: attribute not valid w.r.t. declared attribute use. [Should also have one or more cvc-au errors.]
- cvc-complex-type.3.2.1 element not locally valid: attribute not declared, matches no wildcard.
- cvc-complex-type.3.2.2 element not locally valid: attribute not valid w.r.t. wildcard. [Should also have one or more cvc-wildcard errors.]
- cvc-complex-type.4 element not locally valid: required attribute missing.
- cvc-complex-type.5.1 element not locally valid: more than one wild ID.
- cvc-complex-type.5.2 element not locally valid: there is both a wild ID and a tame ID.
- cvc-particle.1.1 element-sequence not locally valid w.r.t. particle: wildcard match count less than {min occurs}.
- cvc-particle.1.2 element-sequence not locally valid w.r.t. particle: wildcard match count greater than numeric {max occurs}.
- cvc-particle.1.3 element-sequence not locally valid w.r.t. particle: element not valid w.r.t. wildcard. [Should also have some cvc-wildcard error codes.]
- cvc-particle.2.1 element-sequence not locally valid w.r.t. particle: element match count less than {min occurs}.
- cvc-particle.2.2 element-sequence not locally valid w.r.t. particle: element match count greater than {max occurs}.
- cvc-particle.2.3 element-sequence not locally valid w.r.t. particle: element not matched.
- cvc-particle.3.1 element-sequence not locally valid w.r.t. particle: model group must occur at least {min occurs} times.
- cvc-particle.3.2 element-sequence not locally valid w.r.t. particle: model group must occur at most {max occurs} times.
- cvc-particle.3.3 element-sequence not locally valid w.r.t. particle: subsequence not valid against model group. [Should also have some cvc-model-group errors.]
- cvc-model-group element sequence is not valid with respect to model group
- cvc-model-group.1 element sequence is not valid with respect to a sequence group
- cvc-model-group.2 element sequence is not valid with respect to a choice group: none of the particles in the choice validates this sequence
- cvc-model-group.3 element sequence is not valid with respect to an all group
- cos-equiv-derived-ok-rec.2.1 element E1 not substitutable for element E2: substitution is blocked (the blocking constraint contains substitution) [which blocking constraint?]
- cos-equiv-derived-ok-rec.2.2 element E1 not substitutable for element E2: E2 is not in the {substitution group affiliation} chain of E1
- cos-equiv-derived-ok-rec.2.3 element E1 not substitutable for element E2: the type of E1 is derived from the type of E2 by a set of derivation methods which overlaps with the blocking constraint, or with the {prohibited substitutions} of E2's type, or with the {prohibited substitutions} of any other type in the derivation chain. [22]
Attributes
- cvc-assess-attribute the attribute's schema-validity was not asessed.
- cvc-assess-attribute.1 the attribute's schema-validity was not asessed: no attribute declaration was known and present
- cvc-assess-attribute.1.1 the attribute's schema-validity was not asessed: no attribute declaration was known and present (context-determined declaration not found)
- cvc-assess-attribute.1.2.a the attribute's schema-validity was not asessed: no attribute declaration was known and present (context-determined declaration was not skip, but the attribute's QName did not resolve)
- cvc-assess-attribute.1.2.b the attribute's schema-validity was not asessed: no attribute declaration was known and present (context-determined declaration was skip)
- cvc-assess-attribute.2 the attribute's schema-validity was not asessed: validation rule cvc-attribute not performed [why might this happen?]
- cvc-assess-attribute.3 the attribute's schema-validity was not asessed: error cvc-attribute.1 or cvc-attribute.2 occurred
- cvc-attribute attribute not locally valid w.r.t. attribute declaration
- cvc-attribute.1 attribute not locally valid w.r.t. attribute declaration: attribute declaration is absent
- cvc-attribute.2 attribute not locally valid w.r.t. attribute declaration: type definition is absent
- cvc-attribute.3 attribute not locally valid w.r.t. attribute declaration: normalized value not locally valid with respect to (simple) type definition [should have error from cvc-simple-type, too]
- cvc-attribute.4 attribute not locally valid w.r.t. attribute declaration: actual value does not match fixed value
- cvc-au attribute information item not valid w.r.t. attribute use: normalized value does not match canonical form of fixed value in attribute use
Simple types
- cvc-simple-type.1 string not locally valid w.r.t. the given simple type. [Should also have one or more error codes from cvc-datatype-valid in datatypes spec.]
- cvc-simple-type.2.1 string not locally valid w.r.t. simple type derived from ENTITY: not a declared entity name.
- cvc-simple-type.2.2 string not locally valid w.r.t. simple type derived from ENTITIES: substring not a declared entity name.
- cvc-datatype-valid.1 lexical form not datatype-valid w.r.t. a given simple type: does not match a literal in the lexical space.
- cvc-datatype-valid.1.1 lexical form not datatype-valid w.r.t. a given simple type: not pattern-valid.
- cvc-datatype-valid.1.2 lexical form not datatype-valid w.r.t. a given simple type: not in base type's lexical space.
- cvc-datatype-valid.1.2.1 lexical form not datatype-valid w.r.t. a given simple type: not in atomic base type's lexical space.
- cvc-datatype-valid.1.2.2 lexical form not datatype-valid w.r.t. a given simple type: there is a whitespace-delimited token which is not in the base type's lexical space.
- cvc-datatype-valid.1.2.3 lexical form not datatype-valid w.r.t. a given simple type: not a member of the lexical space of any member of the union.
- cvc-datatype-valid.2 lexical form not datatype-valid w.r.t. a given simple type: does not denote a member of the value space. [Should usually be accompanied by an error indicating which facet was violated.]
Lexical forms
- cvc-pattern-valid.1 Literal is not among the character sequences denoted by the regular expression of the pattern.
Values
- cvc-facet-valid.1 value not valid with respect to a particular constraining facet. [This one seems pointless; it will always be accompanied by other errors pointing out the specific facet with a problem.]
- cvc-length-valid value is too short or too long
- cvc-length-valid.1.1 (for strings and URIs): value has too many or too few characters
- cvc-length-valid.1.2 (for hexBinary and base64Binary): value has too many or too few octets
- cvc-length-valid.1.3 (for QName and NOTATION): value has wrong length (this error can never be raised: all values have legal length by definition)
- cvc-length-valid.2 (for lists): value has too many or too few items
- cvc-minLength-valid value is too short. (Sub-rules follow same pattern as for cvc-length-valid.)
- cvc-maxLength-valid value is too long. (Sub-rules follow same pattern as for cvc-length-valid.)
- cvc-enumeration-valid the value is not one of those enumerated
- cvc-maxExclusive-valid value is not (numerically or chronologically) less than the specified maximum
- cvc-maxInclusive-valid value is not (numerically or chronologically) less than or equal to the specified maximum
- cvc-minExclusive-valid value is not (numerically or chronologically) greater than the specified maximum
- cvc-minInclusive-valid value is not (numerically or chronologically) greater than or equal to the specified maximum
- cvc-fractionDigits-valid value requires too many fractional digits (i.e. it is not expressible as i × 10^-n where i and n are integers such that 0 ≤ n ≤ fractionDigits).
- cvc-totalDigits-valid value requires too many digits (i.e. it is not expressible as i × 10^-n where i and n are integers such that |i| < 10^totalDigits and 0 ≤ n ≤ totalDigits).
Miscellaneous, common constructs
- cvc-resolve-instance a QName pair (namespace name or absent, local name) failed to resolve to a schema component
- cvc-resolve-instance.1 a QName pair failed to resolve to a simple or complex type definition using {type definitions}
- cvc-resolve-instance.2 a QName pair failed to resolve to an attribute declaration using {attribute declarations}
- cvc-resolve-instance.3 a QName pair failed to resolve to an element declaration using {element declarations}
- cvc-resolve-instance.4 a QName pair failed to resolve to a named attribute group using {attribute group definitions}
- cvc-resolve-instance.5 a QName pair failed to resolve to a named model group using {model group definitions}
- cvc-resolve-instance.6 a QName pair failed to resolve to a notation using {notation declarations}
- cvc-identity-constraint element not locally valid w.r.t. an identity constraint
- cvc-identity-constraint.1 element not locally valid w.r.t. an identity constraint: selector on constraint does not evaluate to a node set
- cvc-identity-constraint.2 element not locally valid w.r.t. an identity constraint: selector on constraint evaluates to a node set including a node outside the element's subtree
- cvc-identity-constraint.3.a element not locally valid w.r.t. an identity constraint: for some target node, some field evaluates to more than one node
- cvc-identity-constraint.3.b element not locally valid w.r.t. an identity constraint: for some target node, some field evaluates to a node without a simple type
- cvc-identity-constraint.4.1 element not locally valid w.r.t. an identity constraint: constraint is unique but two members of qualified node set have pairwise equal key sequences
- cvc-identity-constraint.4.2.1 element not locally valid w.r.t. an identity constraint: constraint is key, but the target node set and the qualified node set are not equal
- cvc-identity-constraint.4.2.2 element not locally valid w.r.t. an identity constraint: constraint is key, but two qualified nodes have equal key sequences
- cvc-identity-constraint.4.2.3 element not locally valid w.r.t. an identity constraint: constraint is key, but some key field on a qualified node was validated with {nillable} = true
- cvc-identity-constraint.4.3 element not locally valid w.r.t. an identity constraint: constraint is keyref, but there is some keyref member M for which no key in the table matches the key sequence of M.
- cvc-id.1 validation root is not valid: there is an ID/IDREF binding which is the empty set (i.e. there is a reference to an undefined ID)
- cvc-id.1 validation root is not valid: there is an ID/IDREF binding which has multiple members (i.e. some ID occurs more than once)
- cvc-wildcard information item is not allowed by namespace constraint of the wildcard it was validated against [should be accompanied by cvc-wildcard-namespace errors].
- cvc-wildcard-namespace.2.2 namespace name not valid with respect to a wildcard constraint: constraint is an exclusion, and the value is identical to the excluded namespace.
- cvc-wildcard-namespace.2.3 namespace name not valid with respect to a wildcard constraint: constraint is an exclusion, but the value is absent.
- cvc-wildcard-namespace.3 namespace name not valid with respect to a wildcard constraint: The constraint is a set, but the namespace name is not among the members.
F. List of possible improvements
- Write sva_lax_seq(LInputnodes,LParsednodes) (promised in Validation of simple types and ). (Check it, fix it to handle xsi:type as well.)
- Complete the list of content-model checking errors.
- Partition the list of content-model checking errors differently?
Examine the grammar of the core grammar, and the list of errors, to
identify
- errors which are already caught explicitly (and where)
- errors which cause failure of validation (and thus need to be caught, so validation can succeed)
- errors which cannot arise in the purchase-order schema (? on second thought, I'm skeptical that there can be any; if any of these errors is not thrown, I suspect validation of a document with that error would fail)
- Add content-model checking errors to lax validation rule.
- Check xsi:schemaLocation and xsi:noNamespaceSchemaLocation attributes; it is an error if they occur after the first use of the namespace they describe.
- Add test checking for lax validation of element information items.
- Make error message routines to translate error structures to prose messages; change run_test (and other) to use flags to govern (a) writing PSVI, (b) emitting error messages, (c) reporting validity and validation attempted properties for root.
G. Indices to source code
Index of files generated
- coretests.pl: defined in < 424 Utility routines for testing Prolog implementations of po1.xsd >
- load_2l.pl: defined in < 410 [File load_2l.pl] >
- load_core.pl: defined in < 90 [File load_core.pl] >
- load_pv.pl: defined in < 257 [File load_pv.pl] >
- po_2l.pl: defined in < 268 DCTG for purchase order schema, layer 2L >
- po_core.pl: defined in < 85 DCTG core version of the purchase order schema >
- po_pv.pl: defined in < 94 DCTG for purchase order schema, partial-validation layer >
- pvtest.lf.pl: defined in < 168 Prolog code for testing lexical forms > , < 169 Run one test >
- pvtest.lf.pl: defined in < 168 Prolog code for testing lexical forms > , < 169 Run one test >
- pvtest.lf.xml: defined in < 167 Test cases for simple types >
- regression_test.sh: defined in < 425 [File regression_test.sh] >
- sevastopol: defined in < 319 Shell script sevastopol (purchase-order validator) >
- test_2l.pl: defined in < 411 [File test_2l.pl] >
- test_core.pl: defined in < 91 [File test_core.pl] >
- test_pv.pl: defined in < 258 [File test_pv.pl] >
- xsd_lib_2l.pl: defined in < 269 Generic utilities for DCTG-encoded schemas (2L) >
- xsd_lib_core.dctg: defined in < 89 Generic DCTG rules for DCTG-encoded schemas >
- xsd_lib_core.pl: defined in < 88 Generic utilities for DCTG-encoded schemas >
- xsd_lib_pv.pl: defined in < 95 Generic utilities for DCTG-encoded schemas (PV) >
Index of source-code fragments
- [File load_core.pl] 90
- [File test_core.pl] 91
- [File load_pv.pl] 257
- [File test_pv.pl] 258
- [File load_2l.pl] 410
- [File test_2l.pl] 411
- [File regression_test.sh] 425
- Additional PSVI properties for elements (PV) 205
- Address attributes (2L) 311
- Address attributes (2L) 314
- Attribute handling for Items type 27
- Attribute handling for Items type (2L) 403
- Attribute handling for Items type (PV) 230
- Attribute handling for PurchaseOrderType 16
- Attribute handling for USAddress 25
- Attribute handling for simple types 30
- Attribute handling for simple types (2L) 405
- Attribute handling for simple types (2L) 407
- Attribute handling for simple types (PV) 233
- Attribute handling for t_e_item_t_Items 28
- Attribute handling for t_e_item_t_Items (2L) 404
- Attribute handling for t_e_item_t_Items (PV) 231
- Attribute occurrence checking for USAddress 26
- Attribute occurrence checking for USAddress (2L) 402
- Attribute occurrence checking for USAddress (PV) 228
- Attribute occurrences for PurchaseOrderType (2L) 400
- Attribute rules for US address type (2L) 401
- Attribute rules for US address type (PV) 227
- Attribute rules for complex types (2L) 406
- Attribute rules for complex types (PV) 214
- Attribute rules for purchase-order type (PV) 218
- Attribute rules for purchase-order type (first cut) 216
- Attribute wildcard for anyType (2L) 292
- Attribute-occurrence rule for PurchaseOrderType (unused) 217
- Built-in simple type definitions (2L) 289
- Calculate name for PSVI file (PV) 254
- Calculate return code from validity and validation_attempted (2L) 340
- Calculate return code from validity and validation_attempted (2L) 341
- Calculating a date value (PV) 133
- Calculating element validity (PV) 211
- Calculating in-scope namespaces (2L) 351
- Calculating in-scope namespaces (PV) 185
- Calculating in-scope namespaces, cont'd (PV) 186
- Calculating in-scope namespaces, cont'd (PV) 187
- Calculating list of active namespace bindings 61
- Calculating validation-attempted property (2L) 356
- Calculating validation-attempted property (PV) 210
- Call Prolog with the appropriate arguments 323
- Check argument count, issue usage message 320
- Check for xsi:nil attribute, validate (2L) 346
- Check for xsi:type attribute, validate (2L) 347
- Check lexical form and value (2L) 365
- Check return code from aelist_chars, if OK do wlv checks (2L) 361
- Check return code from type_value (2L) 368
- Check return code from ws_normalize, if OK do lv checks (2L) 364
- Check return code, issue message if needed 324
- Check return from QName check (PV) 190
- Check return from QName resolution (PV) 192
- Check return from Type Derivation OK (PV) 194
- Check return from type_lexform for errors, if OK do value checks (2L) 366
- Check that type reference is legal (PV) 193
- Check value constraints (2L) 367
- Check value given in xsi:type (2L) 352
- Check value given in xsi:type (PV) 189
- Checking (pre-) lexical forms against schema-specific types (PV) 165
- Checking (pre-)lexical forms against schema-specific types (2L) 375
- Checking QName values (PV) 148
- Checking a pre-lexical form as a string (PV) 102
- Checking child sequence for mixed content (PV) 243
- Checking date values 49
- Checking date values 56
- Checking date values 57
- Checking date values (PV) 134
- Checking date values (PV) 135
- Checking date values (PV) 136
- Checking decimal and integer values 47
- Checking pre-lexical form as xsd_decimal (PV) 108
- Checking pre-lexical forms against built-in types (2L) 360
- Checking pre-lexical forms against built-in types (PV) 163
- Checking pre-lexical forms as SKU (PV) 142
- Checking pre-lexical forms as quantities (PV) 138
- Checking quantity value against max (2L) 371
- Checking quantity values (2L) 370
- Checking quantity values against bounds (PV) 139
- Checking type derivations (2L) 353
- Checking whether a list is in Anjewierden/Wielemaker form (2L) 332
- Checking whether an atom is an HTTP URL (2L) 336
- Children attribute of content_t_Items 40
- Children attribute of t_PurchaseOrder 36
- Children attribute of t_USAddress 33
- Children attribute of t_e_item_t_Items 37
- Children for opt_e_comment nonterminal 35
- Children for opt_e_shipdate nonterminal 39
- Children for star_e_item_t_Items nonterminal 42
- Collapsing whitespace (PV) 123
- Collapsing whitespace (PV) 124
- Common infoset properties for elements in po namespace 2
- Common infoset properties for elements in po namespace (PV) 180
- Common properties (2L) 272
- Common properties for xsi attributes 9
- Common properties for xsi attributes (PV) 236
- Complex type: t_Items (2L) 312
- Complex type: t_PurchaseOrderType (2L) 307
- Complex type: t_USAddress (2L) 310
- Complex type: t_e_item_t_Items (2L) 313
- Complex types for PO schema (2L) 309
- Complex-content rules (2L) 391
- Complex-content rules (PV) 240
- Conversion between atom/entity list and list of characters 111
- Conversion between atom/entity list and list of codes (PV) 103
- DCTG core version of the purchase order schema 85
- DCTG for purchase order schema, layer 2L 268
- DCTG for purchase order schema, partial-validation layer 94
- DCTG rules for purchase-order attributes (2L) 399
- DCTG rules for purchase-order attributes (PV) 219
- Derivation information for built-ins (PV) 201
- Distinguishing mixed-content error from child-sequence error (PV) 242
- Element declaration checking with element id as parameter (sample) 204
- Element declaration: USPrice (2L) 285
- Element declaration: billTo (2L) 275
- Element declaration: city (2L) 279
- Element declaration: comment (2L) 273
- Element declaration: item (2L) 282
- Element declaration: items (2L) 276
- Element declaration: name (2L) 277
- Element declaration: productName (2L) 283
- Element declaration: purchaseOrder (2L) 270
- Element declaration: quantity (2L) 284
- Element declaration: shipDate (2L) 286
- Element declaration: shipTo (2L) 274
- Element declaration: state (2L) 280
- Element declaration: street (2L) 278
- Element declaration: zip (2L) 281
- Element declarations in purchase-order schema (2L) 271
- Element status message (2L) 421
- Element-type bindings for purchase-order schema (PV) 202
- Empty list of children for opt_e_comment nonterminal 34
- Empty list of children for opt_e_shipdate nonterminal 38
- Empty list of children for star_e_item_t_Items nonterminal 41
- Entity declarations for long number 110
- Error reports (PV) 266
- Exit with appropriate return code 325
- Expand QName to expanded name triple (PV) 196
- Expand Qname to expanded name triple (2L) 355
- Extract properties from element declarations (2L) 287
- Extract properties from type definitions (2L) 315
- Fallback clause (2L) 316
- Find root element in infoset (PV) 252
- Finding one binding for a namespace 64
- General predicate for facet extraction (2L) 373
- Generating a QName from a namespace name and local name, given a list of namespace bindings 62
- Generic DCTG rules for DCTG-encoded schemas 89
- Generic attribute rules (2L) 392
- Generic attribute rules, cont'd (2L) 394
- Generic attribute rules, cont'd (2L) 395
- Generic predicates for simple types (2L) 376
- Generic predicates for simple types (PV) 166
- Generic rules for attribute validation (2L) 408
- Generic rules for attribute validation (PV) 215
- Generic rules for optional and starred elements (2L) 390
- Generic utilities for DCTG-encoded schemas 88
- Generic utilities for DCTG-encoded schemas (2L) 269
- Generic utilities for DCTG-encoded schemas (PV) 95
- Get whitespace keyword, normalize pre-lexical form (2L) 362
- Grammar for command line (2L) 339
- Grammar for digits of decimal (PV) 117
- Grammar for fractional part of decimal (PV) 114
- Grammar for optional digits of decimal (PV) 116
- Grammar for sign and decimal point of decimal (PV) 115
- Grammar rules for XSI attributes 8
- Grammar rules for XSI attributes (2L) 397
- Grammar rules for XSI attributes (PV) 235
- Grammar rules for lexical forms of built-in types (2L) 374
- Grammar rules for lexical forms of built-in types (PV) 164
- Grammar rules for namespace and XSI attributes 7
- Grammar rules for namespace and XSI attributes (2L) 396
- Grammar rules for namespace and XSI attributes (PV) 234
- Grammatical attributes for attribute-list recursion 23
- Grammatical attributes for attribute-list recursion (PV) 226
- Grammatical attributes for empty attribute list 22
- Grammatical attributes for empty attribute list (PV) 225
- Guard to check attributes and content of strings 4
- Guard to check attributes and content of strings (PV) 184
- Handling URI as input (2L) 335
- Handling a single PSVI property 73
- Handling a single PSVI property with a body 72
- Handling file as input (2L) 333
- Handling infoset as input (2L) 331
- Handling stream handle as input (2L) 334
- Identify a parsed node as the validation root (PV) 208
- Initiating schema-validity assessment, generic (2L) 317
- Initiating schema-validity assessment, po-specific (2L) 318
- Invalid attribute (PV) 213
- Invalid child (PV) 212
- Invoke the correct validation routine 171
- Lexical form for NMTOKEN (2L) 378
- Lexical form for NMTOKENs (PV) 150
- Lexical form for QNames (2L) 382
- Lexical form for QNames (PV) 146
- Lexical form for SKU (2L) 387
- Lexical form for SKU (PV) 143
- Lexical form for anyURI (PV) 153
- Lexical form for boolean 11
- Lexical form for boolean (2L) 385
- Lexical form for boolean (PV) 159
- Lexical form for dates (2L) 381
- Lexical form for dates (PV) 126
- Lexical form for day of month 55
- Lexical form for day of month (PV) 131
- Lexical form for decimal and integer 48
- Lexical form for list_anyURI (2L) 384
- Lexical form for list_anyURI (PV) 156
- Lexical form for month 54
- Lexical form for month (PV) 130
- Lexical form for quantity type (2L) 386
- Lexical form for quantity type (PV) 140
- Lexical form for year 50
- Lexical form for year 51
- Lexical form for year (PV) 128
- Lexical form of anyURI (L2) 383
- Lexical form of decimal (2L) 379
- Lexical form of decimal (PV) 112
- Lexical form of integer (2L) 380
- Lexical form of integer (PV) 113
- Lexical form of string (L2) 377
- Lexical form of string (PV) 106
- Mapping from expanded name to type ID (PV) 197
- Mapping from property values to numbers (2L) 342
- Matching elements against element declarations (2L) 344
- More test cases for decimals 118
- Normalizing to blanks (PV) 121
- Old stuff, delete me 265
- Options for level 2L validation 328
- Overall validity message 415
- Overall validity message (2L) 416
- Overall validity message (2L) 417
- PSVI properties for decimals 6
- PSVI properties for strings 5
- PartNum attribute 29
- PartNum attribute (PV) 232
- Perform whitespace normalization on pre-lexical form (2L) 363
- Pre-lexical form checking for NMTOKENs (PV) 149
- Pre-lexical form checking for QNames (PV) 145
- Pre-lexical form checking for anyURI (PV) 152
- Pre-lexical form checking for boolean (PV) 158
- Pre-lexical form checking for dates (PV) 125
- Pre-lexical form checking for list of anyURI (PV) 155
- Predicate sevastopol/0 337
- Predicate sevastopol/4 (2L) 326
- Predicate sevastopol/5, main top-level predicate (2L) 327
- Predicates to load and run test files 92
- Predicates to load and run test files 93
- Predicates to load and run test files (PV) 259
- Prolog code for testing lexical forms 168
- Properties for orderDate attribute 24
- Properties for orderDate attribute (PV) 221
- Properties of unknown attributes (PV) 224
- Purchase order attributes (2L) 308
- Purely grammatical rule for month 52
- QName generation for attributes 63
- Read command-line options, produce Prolog representation (2L) 338
- Recurring on attributes (2L) 418
- Recurring on the children (2L) 419
- Removing a namespace binding (PV) 188
- Report at end of test ('silent' mode) (PV) 264
- Report at end of test (PV) 261
- Report at end of test (terse) (PV) 263
- Report at end of test (verbose) (PV) 262
- Report at start of test (PV) 260
- Reporting error codes (2L) 422
- Reporting one attribute (2L) 423
- Reporting one element (2L) 420
- Reporting validation results (2L) 414
- Resolve QName reference to type (PV) 191
- Resolve QName to type (2L) 354
- Resolve QName to type (PV) 195
- Rules for elements with complex types 1
- Rules for elements with complex types (PV) 179
- Rules for elements with simple types 3
- Rules for elements with simple types (PV) 183
- Rules for purchase-order content models 32
- Rules for purchase-order content models (2L) 389
- Rules for purchase-order content models (PV) 241
- Rules for validating against element declarations (2L) 350
- Rules for validating against element declarations (PV) 203
- Rules for writing extract from schema_information property 256
- Rules for writing schema_error_code property values (PV) 255
- Run one test 169
- Running all tests (PV) 267
- Running one test (2L) 412
- Running one test (2L) 413
- Sample check on pre-lexical form 96
- Sample: check lexical form 98
- Sample: normalize whitespace 97
- Sample: perform value check 1 99
- Sample: perform value check 2 100
- Sample: perform value check n 101
- Schema information property for root element (PV) 206
- Schema-information predicate (PV) 207
- Schema-specific derivation information (PV) 200
- Schema-validity assessment on a file (PV) 251
- Semi-grammatical rule for month 53
- Set options for shell script 321
- Set options for shell script (previous hack) 322
- Setting options (2L) 329
- Setting options (2L) 330
- Shell script sevastopol (purchase-order validator) 319
- Simple test cases for NMTOKEN values 151
- Simple test cases for anyURI values 154
- Simple test cases for boolean values 160
- Simple test cases for decimals 109
- Simple test cases for list_anyURI values 157
- Simple test cases for strings (PV) 104
- Simple test cases for strings (PV) (cont'd) 105
- Simple test cases for strings (cont'd) 107
- Simple type definition for QName (2L) 304
- Simple type definition for boolean (2L) 306
- Simple type definitions for anyURI and list of anyURI (2L) 305
- Simple type definitions in purchase-order schema (2L) 288
- Simple type for quantities (2L) 302
- Simple type: NMTOKEN (2L) 296
- Simple type: SKU (2L) 297
- Simple type: anySimpleType (2L) 290
- Simple type: date (2L) 303
- Simple type: decimal (2L) 298
- Simple type: integer (2L) 299
- Simple type: non-negative integer (2L) 300
- Simple type: normalizedString (2L) 294
- Simple type: positive integer (2L) 301
- Simple type: string (2L) 293
- Simple type: token (2L) 295
- Simple-type content rules for purchase-order types 45
- Simple-type content rules for purchase-order types (2L) 359
- Simple-type content rules for purchase-order types (PV) 162
- Some test cases for QNames 147
- Some test cases for SKUs 144
- Some test cases for dates 127
- Some test cases for dates (four or more year-digits) 129
- Some test cases for dates (leap-year calculations) 137
- Some test cases for dates (ranges on month, day) 132
- Some test cases for quantities 141
- Start schema-validity assessment (PV) 250
- Start schema-validity assessment and dump PSVI (PV) 253
- Suppressing some PSVI properties 74
- Test cases for simple types 167
- The content_skip predicate (PV) 245
- The grammar rule atts_skip (PV) 249
- The grammar rule atts_skip (PV) 398
- The grammar rule content_sequence (PV) 246
- The grammar rule infoitem (PV) 247
- The name_parts predicate (for unparsed names) (PV) 248
- The orderDate attribute (PV) 220
- The type_base relation (2L) 357
- The unknown attribute (PO) (PV) 222
- The unknown attribute (USAddress) (PV) 229
- Top-level components in the purchase-order schema (PV) 198
- Top-level predicate for writing PSVI 60
- Type derivation hierarchy for purchase-order schema (PV) 199
- Type-specific type_value constraints (2L) 369
- Type-specific type_value constraints for built-ins (2L) 372
- Utilities for checking attribute occurrences 12
- Utilities for checking attribute occurrences (2L) 409
- Utilities for checking attribute occurrences (PV) 237
- Utility for checking absent attributes 13
- Utility for checking absent attributes (PV) 238
- Utility for collapsing whitespace 21
- Utility for providing defaulted attributes 14
- Utility for providing defaulted attributes 15
- Utility for providing defaulted attributes (PV) 239
- Utility for whitespace normalization 17
- Utility for whitespace normalization 18
- Utility for whitespace normalization 20
- Utility for whitespace normalization (PV) 119
- Utility for whitespace normalization (PV) 120
- Utility for whitespace normalization (PV) 122
- Utility routines for testing Prolog implementations of po1.xsd 424
- Utility to change whitespace characters to blanks 19
- Validate xsi:type, fall back if needed (2L) 348
- Validating an element (2L) 343
- Validating attributes against types (2L) 393
- Validating elements against element declarations (2L) 345
- Validation attempted property for complex elements (PV) 181
- Validation attempted property for simple elements (PV) 182
- Validation-context property for elements (PV) 209
- Value-checking rules for SKU 58
- Value-checking rules for quantities 59
- W3C copyright notice 86
- W3C copyright notice 87
- Wrapper predicates (sva_content_TYPE) for complex content 43
- Wrapper predicates (sva_content_TYPE) for complex content (2L) 388
- Wrapper predicates (sva_content_TYPE) for complex content (PV) 244
- Write expectations (silent) 175
- Write expectations (terse) 174
- Write expectations (verbose) 173
- Write out result of this test 172
- Write out the result (silent) 178
- Write out the result (terse) 177
- Write out the result (verbose) 176
- Write out what is expected for this test 170
- Writing out PSVI properties for attributes 76
- Writing out PSVI properties for attributes 77
- Writing out PSVI properties for element 71
- Writing out a PCDATA atom in PSVI 82
- Writing out a child element in PSVI 84
- Writing out a non-Prolog Unicode character in PSVI 83
- Writing out a single PSVI property 75
- Writing out a single PSVI property for attributes 78
- Writing out a single PSVI property for attributes 79
- Writing out a single PSVI property for attributes 80
- Writing out a single attribute in PSVI 66
- Writing out a single attribute in PSVI 67
- Writing out a string without double quotes 69
- Writing out an attribute value in PSVI 68
- Writing out attributes in PSVI 65
- Writing out children in PSVI 81
- Writing out namespace attributes in PSVI 70
- anyType (2L) 291
- attribute_unknown predicate (PV) 223
- partition predicate 31
- sva_content rules for built-in Types 44
- sva_content rules for built-in types (2L) 358
- sva_content rules for built-in types (PV) 161
- sva_plf rules for built-in types 10
- sva_plf rules for built-in types 46
- xsi:type fallback to declared type (2L) 349