Soweit zu den Anforderungen, die wir als Geisteswissenschaftler
an die Standards stellen müssen.
Es gibt auch einige Anforderungen, die an die geisteswissenschaftlichen Projekte
gestellt werden, eben weil unsere Projekte als Ziel haben,
Werkzeuge für die Nachwelt vorzubereiten.
3.1. Lebensdauer der Technik und der Daten
Die Computertechnik entwickelt sich nach wie vor im rasenden Tempo.
Viele Organisationen rechnen damit, daß alle Hardwares jede zwei
bis drei Jahre ersetzt werden; manche versuchen, die Maschinen im
Durchschnitt fünf Jahre lange in Betrieb zu halten — Maschinen
im Alter von fünf Jahren neigen aber zu unerwarteten und
katastrophalen Pannen. Wer denkt schon daran, Rechner im
Dreißig- oder Zwanzigjahrenzyklus, oder selbst im
Zehnjahrenzyklus, zu erneuern?
Die Softwares bleiben oft etwas länger leistungsfähig.
Die verschiedenen Versionen einer Software ersetzen sich vielleicht
regelmäßig, aber es gibt durchaus Softwares, die jahrzehntelang
zugänglich sind, oder sogar jahrzehntelang den Markt beherrschen.
Jahrzehntelang, aber man kann noch nicht sagen: über viele
Jahrzehnte hinweg.
(Tustep, jetzt bald im Alter von dreißig Jahren,
ist ja in der Softwarewelt ein Greis.)
Aber die Daten, um die wir uns kümmern, leben viel länger.
Selbst kommerzielle Daten bleibe viel länger aktuell, als Hardware
und Software. Der Vertrag mit dem Telefondienst läuft
fünf, oder zehn, oder fünfzig Jahre. Die ärztlichen
Unterlagen sollten idealerweise uns das ganze Leben lang zugreifbar
bleiben, oder noch länger, denn die [medical history] unserer
Eltern können durchaus bei der Diagnose von Belang sein.
Für Steuerzwecke haben oft Immobilien eine
Abschreibungsdauer
von etwa dreißig Jahren, werden aber viel länger in Stand gehalten.
Und das sind nur die einfachsten rein kommerziellen Beispiele.
Wer die menschlichen Sprachen, Literaturen, und Kulturen als
Forschungsgegenstand hat, pflegt, Daten im Alter von fünf bis
zwanzig Jahrhunderte zu verarbeiten. Selbst die Vorbereitung eines
Wörterbuches nimmt in manchen Fällen mehr Zeit in Anspruch, als
die Geschichte der elektronischen Rechentechnik aufzuweisen hat.
Wenn wir bei jeder neuen Maschine, bei jeder Aneignung einer neuen
Software, alle Daten wieder neu erstellen müßten, so kämen wir
nie über die Anfangsstadien unserer Projekte hinaus.
Wenn wir unsere Daten und Forschungsresultate, und die Werkzeuge,
die wir uns bauen — Korpora, Ausgaben, Wörterbücher, Lexika —
nicht nur fü den eigenen Gebrauch erhalten wollen, aber noch über
das eigene Leben hinaus der Nachwelt zur Verfügung stellen wollen,
sollten wir uns ernsthaft darüber Gedanken machen, wie wir die
Daten in einer dauerhaften und nachhaltbaren Form [Format?]
speichern können, aus der wir wenns notwendig ist auch
anwendungsspezifischen Formen ableiten können. Wie macht man
das? Wie sichert man die Daten für die Zukunft?
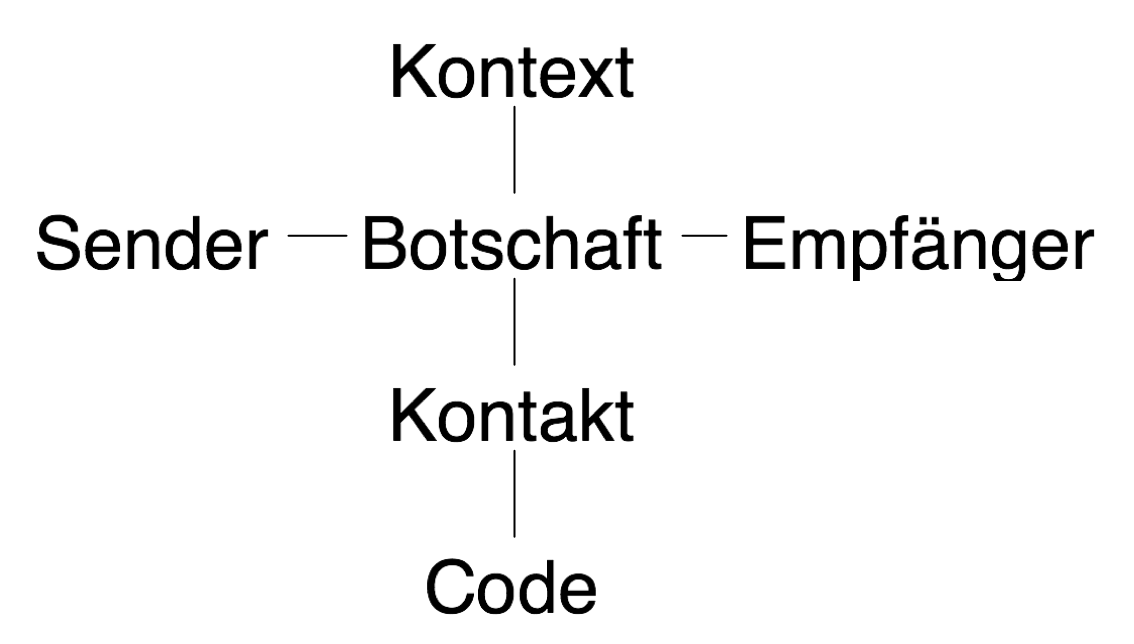
Man kann diese Fragen vielleicht am besten beantworten,
wenn man hier die Botschaften an die Zukunft im Licht eines
allgemeinen Kommunikationsmodells betrachtet, das vom dem
großen Strukturalisten Roman Jakobson 1960 vorgeschlagen
wurde.
3.2. Erfolg und Fehlschlag
Als Zukunftsicherung der Daten bezeichne ich das Bemühen,
sicherzustellen (oder wenigstens die Wahrscheinlichkeit zu
erhöhen, daß die Daten, die wir mühevoll und teuer erstellen,
für die Nachwelt nutzbar seien.
Im Grunde genommen gleicht dies dem Problem des Datenaustausches mit
anderen Projekten oder Organisationen: Die Zunkunft ist ein fremdes
Land, man macht dort vieles anders. In mancher Hinsicht unterscheiden
sich diese zwei Probleme: der
Empfänger
der Daten z.B. sollen
wir oft selbst sein, und nicht andere, aber im wesentlich kennen wir
auch dann den Empfänger auf eine sehr unvollkomme Weise. Wir
werden bis dahin einiges gelernt, oder vergessen, unsere Institutionen
werden vielleicht neue Richtungen eingeschlagen haben. Die Lage
kann sich drastisch geändert haben. (Das kommt nicht ganz selten
vor, wenn man neue oder neuartige Daten und Softwares bereitstellt:
lange, bevor man den Originalplan zu Ende gefürht hat, können
die ersten Teillieferungen die Lage grundliegend ändern.)
Und selbst wenn der Empfänger die selbe Ziele hat, die wir
erwarten, kennen wir doch nicht die technische Umgebung, in der
er arbeitet, wir wissen nicht, was für Hardware und Software zur Verfügung stehen wird,
unsere Daten auszunutzen. Wir wissen es nicht und können es nicht
erfahren, denn die Kommunikation mit der Nachwelt ist eine Art
Einbahnstraße, ein Write-Only Datenträger. Der Empfänger kann
nicht unsere Botschaft empfangen und inspizieren, und dann uns eine
Rückmeldung schicken “Botschaft nicht verstanden. Bitte
nochmals senden.” Wer Botschaften an die Zukunft sendet,
bekommt keine Rückmeldungen. Es ist eine Art Flaschenpost,
oder als ob man Botschaften an Spionen senden würde, die
so geheim arbeiten müssen daß sie sich keine Rückmeldung
leisten können.
In dieser Lage müssen wir alle Fehlermöglichkeiten des Vorgangs
voraussehen und vermeiden. Alle Bruchstellen der Verbindung zwischen
Sender und Empfänger müssen untersucht werden, um mögliche Pannen zu
vermeiden. Dazu diene uns das Kommunikationsmodell von Roman Jakobson.
Ein Mitteilung, so Jakobson, hat offensichtlich einen Sender, und einen Empfänger
Die Mitteilung kann vor allem dazu bestimmt sein, über den Sender Auskunft
zu geben. Jakobson schreibt demgemäß eine Ausdrucksfunktion oder
emotive Funktion der Sprache
und der Mitteilung zu. Oder sie kann dem Empfänger einen Auftrag oder einen Befehl
geben: das ist die Aufforderungsfunktion oder die konative Funktion.
Meistens aber handelt es sich um eine Mitteilung, die sich auf eine Sachlage
in der Welt (oder im Kontext) bezieht; eine so ausgerichte Mitteilung
übt die referentielle Funktion der Sprache aus.
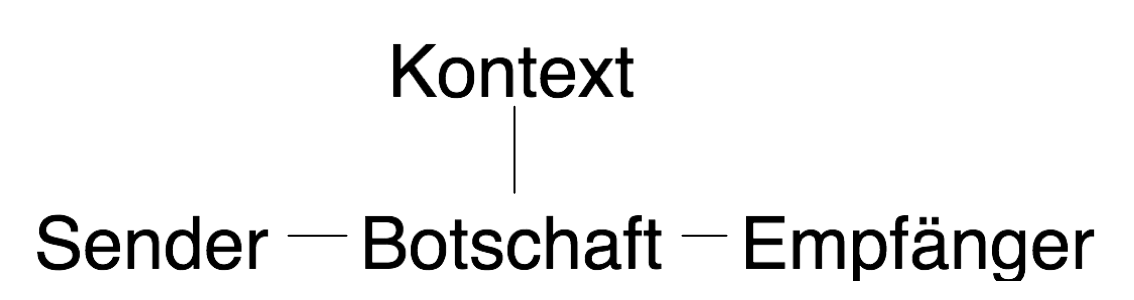
Die Kommunikation findet aber nur dann statt, wenn der Sender
und der Empfänger körperlich in Kontakt stehen.
Die Mitteilung muß ja physikalisch vom Sender zum Empfänger kommen.
Im Fall von gesprochenen Mitteilungen heißt das, daß der
Sprecher (der Sender) und der Hörer (der Empfänger) in unmittelbarer Nähe
zueinander sind, es sei denn, Lautsprecher oder Funkgeräte kommen
ins Spiel. Im schriftlichen Fall muß der Schriftträger
vom Sender zum Empfänger kommen, entweder direkt oder durch eine
Art Staffellauf, wo mehrere Abschriften einen Teil der Strecke
zurücklegen können. Werke der Antike oder des Mittelalters
kann man heute nur dann lesen, wenn wenigstens eine
Hs die Feinde der Information überwunden hat und bis in unsere
Zeit überlebt hat. Selbst in der Neuzeit sind viele Werke
dem Krieg, der Zensur, oder den Kaminen überlebender Verwandter
des Autors zum Opfer gefallen. Eine Mitteilung oder Botschaft
kann auch als Zweck haben, einfach sicherzustellen, daß dieser
Kontakt richtig funktioniert. (Hallo? Hallo? Hören Sie? Funktioniert
diese Lautsprecheranlage?)
Das ist die phatische Funktion der Sprache.
Wenn wir den Kontaktweg hinzufügen, sieht die Zeichnung so aus:
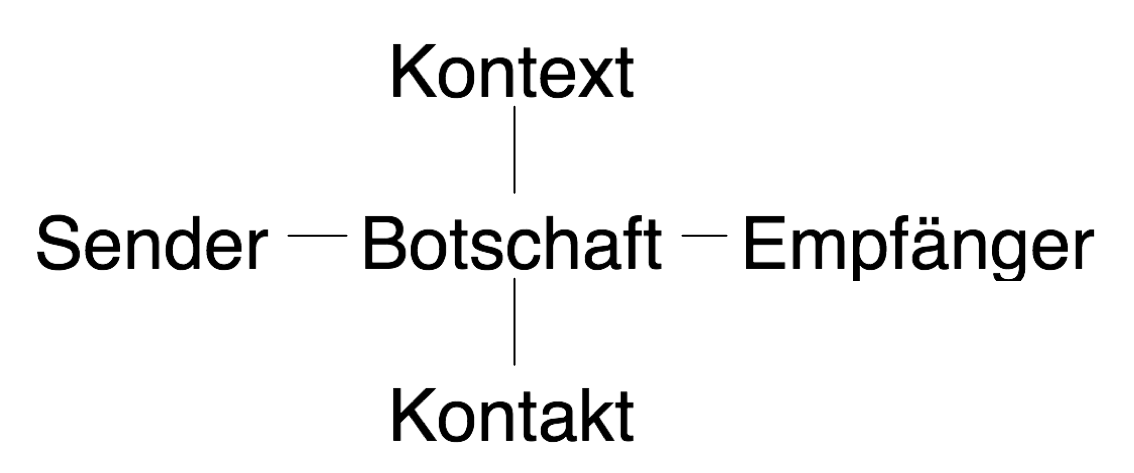
Der Kontakt aber genügt nicht. Die Kommunikation findet
nur dann statt, wenn der Sender und der Empfänger beide das selbe sprachliche System
(denselben Code) beherrschen.
Die metalinguistische Function der Sprache dient dazu,
die Gemeinsamkeit des sprachlichen Systems herzustellen oder wieder
in Gleichgewicht zu bringen.
Jakobson wollte die Funktionen der Sprache erläutern, aber
sein Modell kann uns dazu dienen, die verschieden Ausfallarten der
Kommunikation zu verstehen.
3.2.1. Ausfall beim Sender
Die erste mögliche Bruchstelle in der Verbindung von Sender und Empfänger
liegt beim Sender. Wenn wir Botschaften an die Zukunft senden, dann
sind wir das. Wir können aus Absicht oder Versehen die Daten
überhaupt nicht senden; wir könnten sie verlieren oder löschen,
statt sie aufzubewahren und wiederzubenutzen.
Oder, und das ist eine zweite Ausfallart, es könnte vorkommen,
daß wir nicht sagen, was wir meinen. Im Bereich XML heißt das,
wir könnten dem Tagmißbrauch, dem schlechten Modellieren, oder
anderen semantischen Übeln unterliegen. Die Semantik soll später
diskutiert werden. Im Moment genügt es, zu sagen: wenn mann
bestimmte Informationen in Zukunft wiederbenutzen will, so ist
es wichtig, im Klaren über die Natur dieser Information zu sein.
In einem literarischen Werk wird dieses Anliegen dazu führen, daß
man am liebsten die eine Stelle as Personennamen, die andere als
terminus technicus, die dritte als Fremdwort, auszeichnet, auch wenn in der
Stilvorlage alle drei in der gleichen Schriftart (etwa: schräg)
gesetzt werden sollen. Wenn man mal die Stilvorlage ändert (und
das kommt doch vor), wird sich die Schriftart der einen oder der
anderen Stelle ändern, doch nicht die Tatsache, daß es um
Personnenname, terminus technicus, oder Fremdwort handelt.
Wenn man sich auf die sachliche Auszeichnung konzentriert, so
vermeidet man viele unnötige Änderungen.
Die Fähigkeit, das zu sagen was man sagen will, statt die
Aussage einem vordefinierten Schema von semantischen Primitivfunktionen
anzupassen, läßt den Gebrauch von SGML und XML fast wie eine Befreiung
erscheinen, wenn man an andere Methoden der Textdarstellung gewohnt ist.
Damit verbunden ist ein ernüchternde Verantwortung, denn wenn man
genau das sagen kann, was man sagen will, so muß man sich eben entscheiden,
was man eigentlich sagen will.
3.2.2. Ausfall beim Empfänger
Eine zweite Bruchstelle stellt der Empfänger dar. Es kann sein, daß
der zukunftiger Empfänger unserer Botschaft gar nicht auf diese Botschaft
achtet, nicht zuhört, fängt damit nichts an. Dagegen kann man nicht
viel unternehmen, außer daß wir es dem Empfänger leicht machen, zu
wissen, worum es sich bei dieser Botschaft dreht. So kann man
vielleicht verhindern, daß unsere Arbeit aus Versehen weggeschmissen
wird, weil der Empfänger (und hier bitte die Erinnerung daran wach halten,
daß es sich hier sehr oft um uns selbst handelt) nicht mehr die Bedeutung
oder den Ursprung der Daten durchschaut.
Eine zweite Ausfallart beim Empfänger besteht darin, daß wir vergessen,
daß wir nicht wissen, wer der Empfänger ist. Wir wissen
vor allem nicht, was der Empfänger kann, was seine Fähigkeiten sind.
Es ist folglich meistens sinnlos, ihm per Flaschenpost zu bestimmten
Tätigkeiten anzuregen, ihm Befehle zu erteilen, ihm eine Botschaft mit
imperativer Semantik zukommen zu lassen. Eine
deklarative Semantik hat viel größere Chancen, auch in zukünftiger
Zeit relevant zu bleiben, genauso wie die deklarative Semantik
heute eine Schlüsselposition hat, wenn man die Wiederverwendbarkeit,
die Geräteunabhängigkeit, und die Anwendungsunabhängigkeit der
Daten gewährleisten will.
3.2.3. Ausfall beim Kontakt
Die dritte mögliche Bruchstelle liegt darin, daß man den
Kontakt zwischen Sender und Empfänger verliert.
Diese Ausfallart tritt dann ein, wenn der Datenträger verloren
geht, aus internen Gründen nicht mehr zu lesen ist, oder
mit neu erworbenen Maschinen nicht mehr zu lesen ist. In den
80er Jahre haben gewissenhafte Benutzer ihre Dateien regelmäßig
auf Disketten gespeichert, um sie zu archivieren. Jetzt
sitzen dies Benutzer auf einem großen Haufen Disketten in
der Größe von 5 Zoll, die keine Maschine mehr lesen kann. Wenn
man noch 3-Zoll Disketten hat, soll man sie schnell auf neue
Datenträger überspielen, bevor die letzte zugängliche Maschine im Haus,
die ein Diskettentreibwerk noch hat, spurlos verschwindet.
Manche Bibliotheke und Rechenzentren versuchen, diese Ausfallart
dadurch auszuweichen, indem sie alle Datenträger regelmäßig
kopieren. Viele setzen dafür Softwares für die Verwaltung von
digitalen Bibliotheken ein, die das Kopieren der Daten und der
dazugehörigen Metadaten bewerkstelligen. Solche Softwares sind
dazu konzipiert, sehr große Datenmassen zu bewältigen,
aber die Verbindung zu dem ursprünglichen Kontext geht in
solche Massensystem leicht verloren. Es rät sich, dabei
möglichst alles aufzuschreiben, was der zukünftiger Empfänger
vielleicht wissen muß, wenn er die Daten innerhalb dieser
Digitalbibliothekssoftware eines Tages herumliegen findet.
3.2.4. Ausfall im Code
Eine Ausfallart, die in der Vergangenheit den
geisteswissenschaftlichen Projekten große Schwierigkeiten bereitet
hat, ist die Möglichkeit, daß der Sender und der Empfänger
verschieden Zeichensätze benutzen. Eben weil der Zeichensatz
von so grundlegender Bedeutung für die Textdatenverarbeitung ist,
und von allen Teilsystemen unterstützt werden muß, wird
die Wahl des Systemzeichensatzes vielen Benutzern völlig
unsichtbar. Stillschweigend setzen alle Softwares im System
den gleichen Zeichensatz voraus. Wer nicht gegen diesen
Systemzeichensatz wegen seiner Unvollständigkeit ständig
kämpfen muß, fragt sich gar nicht, wie der Zeichensatz des
Systems überhaupt heißt, bis es beim Datenaustausch mit einem
fremden System zu einer Panne kommt.
Hier hat die Entwicklung vom Universalzeichensatz unheimlich viel
geholfen. Auch wenn man auf die Private Use Area zurückgreifen
muß, um Sonderzeichen zu kodieren, hat man mit dem Universalsatz
einen gemeinsamen Anhaltspunkt.
Wenn der Empfänger einmal die Zeichenkodierung verstanden hat,
beginnt die schwierige Arbeit, das Datenformat zu verstehen. Es
sind dem menschlichen Geist beim Erstellen von Datenformaten
praktisch keine Grenzen gesetzt, und der menschliche Geist hat
sich dankbar auf diesem Gebiet energisch und reichlich entfaltet.
Wer eine Botschaft an die Zukunft senden will, hat
drei Arten von Datenformatten zu erwägen:
- proprietäre (geschlossene) Formate
- eigene, selbstdefinierte Formatte, den eigenen Daten und
dem eigenen Bedarf nach Belieben angepast
- öffentlich zugängliche, öffentlich dokumentierte
Formatte
Proprietäre Formate bieten sich an und sind sehr bequem, solange
die dazugehörige Software weit verbreitet ist und sowohl dem Sender
wie auch dem Empfänger zugänglich ist. Für den Datenaustauch über
geographischen und organisatorischen Grenzen hinweg werden proprietäre
Formate oft mit Erfolg eingesetzt. Aber das meist recht kurze
Leben solcher Formate macht sie für eine Botschaft an die
Zukunft eher untauglich.
Selbstgemachte Formate sind oft eine gute Wahl, weil sie so gut
der Eigenart der Daten und den Bedürfnissen des Senders angepaßt
werden können. Aber wer ein solches Eigenformat definiert, muß
damit rechnen, daß er das Format auch gründlich dokumentieren muß.
Denn ohne Dokumentation wird der Empfänger wenig mit den Daten anzufangen wissen.
Es waren keine dreißig Jahre seit der Marslandung von Viking (1975
gelauncht, 1976 gelandet), als man die Meßdaten des Landers
durchsuchen wollte, um mögliche Zeichen von Leben auf Mars zu finden.
Das Magnetbandformat aber, in dem die Daten elektronisch erhalten sind,
wurde leider nie dokumentiert, bzw. es wurde die Dokumentation nicht
gefunden, und alle Daten wurden neu von Papierausdrucken mit der Hand
eingegeben.
Für eine Botschaft an die Zukunft scheinen aus solchen Gründen
sich die offene Formate wie XML besonders gut (oder wenigstens
weniger schlecht) zu eignen. Solche Formate sind gut dokumentiert,
die Dokumentation läßt sich ohne große Mühe finden (wenigstens
heute - wir wollen hoffen, das sei auch in Zukunft der Fall), und
es scheint unwahrscheinlich, daß das Wissen um XML und andere
offene Formate jemals gänzlich aus der Welt verschwindet. Das
XMLformat weist viel Redundanz auf, so daß es Datenverfall
verhältnismäßig gut widersteht — wenigstens wird es weniger Wahrscheinlich,
daß die Daten korrumpiert werden, ohne daß man es merkt.
Auch wenn XML so aus der Mode fiele, daß
es keine XML-softwares mehr gäbe, ist das Format im Grunde
so einfach, daß man selbst einen Parser dafür schreiben könnte,
um die Umformatierung in ein neues Format zu erleichtern.
Zusammenfassend kann man sagen, daß gegen Ausfälle beim Kontakt
und beim Code es brauchbare technische Mittel gibt, wenn man diese Mittel
konsequent und diszipliniert einsetzt. Probleme beim Sender
unde beim Empfänger dagegen, verlangen nicht technische sondern
institutionelle Lösungen.
3.2.5. Ausfall in der Semantik
Die letzte Ausfallart ist die der Semantik.
Die Kommunikation kann selbst dann spektakulär versagen,
wenn der Sender etwas mitteilen will, der Empfänger zuhören will, und
die in dem gemeinsamen Code verfaßte Mitteilung erfolgreich
beim Empfänger ankommt.
Drei verschiedene Ausfallarten gibt es hier, die alle mit der
Erfassung der Bedeutung der Botschaft zu tun haben.
Die erste Ausfallart scheint ein hoffnungsloser Fall zu sein.
Der Empfänger empfängt, entschlüsselt, und versteht die Botschaft,
und entdeckt dann erst, daß die Botschaft für den Empfänger weder
interessant noch nützlich ist. Der Empfänger will vielleicht etwas
über die Weissagung in der Antike erfahren, und schaut sich
die Daten an, weil sie angeblich u.a. auch von Orakeln handeln.
Er findet darin aber nur Information zu einem gewissen Datenbanksystem,
das ihn leider nicht interessiert. Ganz verhindern kann man wohl
diese Art des Ausfalls nicht, aber wir können und sollen es dem
Empfänger so leicht wie möglich machen, zu sehen, welches Oracle wir
eigentlich meinen.
Die zweite Ausfallart besteht darin, daß der Empfänger die
Botschaft erfolgreich entziffert, alle Daten richtig den
betreffenden Objekten in der Anwendungsdomäne zuweist,
begreift die volle Bedeutung der Botschaft aber nicht.
Dagegen ist auch kein Kraut gewachsen: daß man gelegentlich
die volle Bedeutung einer Tatsachenmenge nicht begreift,
gehört weniger zu der Problematik der Kommunikation, als
zu der Problematik des Lebens.
Die dritte semantische Ausfallart ist ganz einfach. Man bekommt
ein XMLdokument, versteht also mühelos die Elementstruktur der
Daten, kennt aber die vorliegende Auszeichnungssprache nicht,
versteht also nicht, welche Bedeutung den Elementen und Attributen
des Dokuments zuzuweisen ist. Diese Ausfallart dürfte eine der
am öftesten auftretenden sein, wenn es um den Austausch von
XMLdokumenten geht. Sie kann wenigsteins teilweise vermieden werden,
aber nicht ohne Arbeit.
Zu diesem Thema gibt es viel zu sagen — zuviel, vielleicht, denn
ich vermute, der Empfang ist inzwischen doch fertig vorbereitet,
und Sie haben vielleicht schon Durst. Ich versuche mich also kurz
zu fassen.
3.3. Nachhaltige Semantik
Die eigene Auszeichnungssprach dem Empfänger verständlich zu machen,
erfordert eine gewisse menschliche Intelligenz, und es ist schwierig,
dafür ein Regelwerk zu erstellen, das objektiv oder intersubjektiv
nachprüfbar wäre, und das uns den Erfolg garantieren würde.
Einige allgemeine Ratschläge kann man allerdings geben.
Regel 1: Man denke darüber systematisch nach, was man
sagen will.
Man braucht nicht unbedingt, eine formale Ontologie mit Definitionen
in der Web Ontology Language (OWL) oder mit Topics in Topic-map-format
zu formulieren, aber es lohnt sich zu fragen: worüber, über welche
Arten von Wesen, wollen wir Aussagen machen? Wörter? Sprachen?
Texten? Werken? Belegstellen? Wenn man eine formal definierte Ontologie erstellen
würde, was für Dinge würde man voraussetzen? Welche Eigenschaften
würde man ihnen zuweisen? Zu den Methoden für solche systematische
Überlegungen gibt es eine kleine, weit verstreute Literatur, die die
Modellierung und die Erstellung von Auszeichnungssprachen behandelt.
Ich empfehle allen u.a. das Buch von Eve Maler und Jeanne El Andaloussi,
Developing SGML DTDs: From Text to model to markup.
Regel 2: die Auszeichnungssprache sorgfältig
entwerfen, mit dem Ziel, daß die Einzeldokumente, die mit dieser Sprache
ausgezeichnet werden, so gemeinverständlich wie nur möglich sein sollen.
Rein mechanisch produzierten Auszeichnungssprachen können
beliebig schwerverständlich werden.
Regel 3: die Auszeichnungssprache,
und Ihren Gebrauch dieser Sprache, dokumentieren!
Große Bibliotheke haben oft ein Hauptexemplar des
bibliothekarischen Regelwerks, nach dem sie Bücher katalogisieren.
Dieses Hauptexemplar wird oft mit unbeschriebenem Papier durchschossen,
damit die lokal adoptierten Zusatzregeln, die lokale Auslegung
schwieriger Fälle, usw. festgehalten werden können. Manche
geisteswissenschaftliche Projekte pflegen auch eine solche
lokale Erweiterung ihres Regelwerks. Bei einer allgemein gehaltenen
Auszeichnungssprache wie den Richtlinien der TEI sind solche
lokale Erweiterungen durchaus notwending, und müssen dokumentiert
werden, wenn die Daten dem Empfänger verständlich sein sollen.
Zusamenfassend sollte das Markup Vokabular (oder genereller gesagt das verwendete Datenformat)
in allen für Langlebigkeit angelegten Daten auf verschiedene Arten dokumentiert werden:
- Generelle Dokumentation auf hoher Ebene
- Referenzinformationen für jedes Element und Attribut
- Anmerkungen zu lokaler Anwendung, wenn die lokale Anwendung eine konsistente Variante eines weit verbreiteten Vokabulars ausmacht.
- Beschreibungen der Bedeutung des Markups mittels einer 'Übersetzung
der Bedeutung des Markups oder von Markup-Konstrukten in eine oder mehrere formale Notationen: Prädikatenlogik
erster Stufe, RDF, Prolog etc.
Regel 4. den Tagmißbrauch vermeiden!
Der Tagmißbrauch (engl. Tag abuse) schadet der
Nutzbarkeit von Dokumentation, denn wenn Tagmißbrauch begangen wird, dann beschreibt
die Dokumentation nicht mehr
die Sprache, in der die Daten ausgedrückt werden. Wenn Elemente
oder Attribute nicht angemessen hinsichtlich ihrer definierten
Semantik benutzt werden, sind die Daten weniger einfach
wiederverwendbar, weil sie nicht so verlässlich verarbeitet
werden können.
Der Tagmißbrauch definiert man als
Unverträglichkeit zwischen der beabsichtigten Semantik und der
tatsächlichen Verwendung eines Tags Es ist schwer, ihn mit automatischen
Methoden aufzuspüren. Aber es gibt Methoden, welche das notwendige
menschliche Eingreifen einfacher und effizienter machen. So genannte
false-color Fassungen von Dokumenten können vorbereitet werden.
Sie stellen in auffälligen Farben Markierungen von spezifischen
Passagen bereit, welche ein Mensch überprüfen sollte (z.B.
alles in Rot was als ein Personenname ausgezeichnet ist, oder alle
Ortnamen mit blauem Hintergrund). Die Semantik des Markups kann in
natursprachige Sätze übersetzt werden, so daß sie hinsichtlich
Inkonsistenzen und Irrelevanz überprüft werden kann.
Vergleiche [
Marcoux 2006] für
weitere Diskussionen.
Regel 5. Ergänzende Dokumente sollen bereitgestellt und dokumentiert sein.
Soviel relevanter Kontext wie möglich muß man an
den Empfänger weiterleiten. Wichtige Metadaten, die spezifisch sind
für ein bestimmtes Dokument, sollten wahrscheinlich eher
innerhalb des Dokuments gespeichert werden als extern, so daß
es weniger wahrscheinlich wird, daß sie verloren gehen.
Die Verfügbarkeit solchen zusätzlichen Materials kann
weitreichend zum Verständnis des angemessenen Kontextes für
die Interpretation der Daten beitragen, und hilft somit
Mißverständnisse oder ein Unverständnis der Daten zu
verhindern.
Regel 6. Früh und oft validieren und verifizieren!
Man kann viele Problem dadurch verhindern,
indem man regelmäßige
Validierung und Verifikation durchfürht. Im allgemeinen Fall ist die
Semantik formaler Sprachen nur für wohlgeformte
Äußerungen wohldefiniert. Nicht valide Dokumente haben
nicht notwendigerweise eine feste Interpretation. Es muß deshalb
früh und oft validiert werden.
Das selbe trifft für semantische Validierungs- und
Verifikationsprozeduren zu. (Der Leser sollte sich bewußt sein
daß Forscher und Praktiker aus dem Bereich der
Programmverifikation Verifikation als mechanischen
Prozeß bezeichnen, und Validierung als zugehörigen
nicht mechanischen Prozeß. Die Markup Community folgt der Tradition
der formalen Logik, indem sie den Ausdruck Validität
als mechanisch überprüfbare Eigenschaft auffaßt; nicht
selten wird der Ausdruck Verifikation benutzt um einen
zugehörigen nicht mechanischen Prozeß zu bezeichnen. Wer sich
mit Anderen unterhält, die Interesse an dem Thema haben, tut gut,
sicherzustellen, daß man man sich u.U. die Terminologie sich
gegenseitig erklärt.)
Zusammenfassend:
- Überlegen, was Sie überhaupt sagen wollen!
- Die Auszeichnungssprache mit Sorgfalt entwerfen,
und die Elementnamen, die Attributnamen, und die
Verschachtelungsstruktur mit Bedacht wählen!
- Die Ausz.spr. dokumentieren, vorzugsweise auf verschiedene Arten:
- Dokumentation in Prosa auf hoher Ebene
- detaillierte Beschreibung jedes Elements und jedes Attributes
- Dokumentation zur lokalen Interpretationen und Verwendung
- Beschreibung, in Prosa und als ausführbarer Programmcode, zumindest eines Teils
der Bedeutung einer Dokumentinstanz in einer radikal anderen Notation wie Prädikatenlogik erster Stufe oder RDF.
- Den Tagmißbrauch vermeiden!
- Zusätzliche Dokumente (Dokumentation, Schemata, Stylesheets etc.) für den Empfänger bereitstellen!
- Sowohl die Syntax als auch die Semantik der Dokumente systematisch
validieren!