What is schema mapping,
and why should portals care?
C. M. Sperberg-McQueen
<philtag n="7"/>
Trier, 13 October 2008
Overview
- What is schema mapping?
- Why should portals care?
- A problem for portals, repositories, collections
- A brute force solutions using schema mapping
- A clever solutions using schema mapping
- Longer-term prospects
- In the short term
N.B. this talk does not provide full or correct answers.
It doesn't even provide incomplete or incorrect answers.
It may, possibly, provide a useful question.
What is schema mapping?
- schema mapping
- the translation of data from one schema (or: vocabulary; or: markup language)
to another
- data exchange
- taking data structured as an instance of one schema and
representing it as accurately as possible as an instance of another
- data integration
- bringing together data from disparate sources and providing
access to it as though it were a unified collection
A problem for portals
A portal presenting a collection should
- Provide access to the entire collection
through a single
unified interface
- Provide full access to each item in the collection
A problem for portals (2)
But the collection has variable structure.
| |
Tag 1 | Tag 2 | Tag 3 | Tag 4 | Tag 5 |
Tag 6 | Tag 7 | Tag 8 |
| Text 1 |
X | X | | | |
| | |
| Text 2 |
X | X | X | X | |
| | |
| Text 3 |
X | | | X | |
| | |
| Text 4 |
X | | | X | |
X | | |
| Text 5 |
X | | | X | |
| X | |
| Text 6 |
X | X | | X | |
| | X |
| Text 7 |
X | X | | | X |
| X | X |
| Text 8 |
X | X | | | |
| | |
| Text 9 |
X | X | X | X | |
| | |
| Text 10 |
X | | | X | |
| | |
| Text 11 |
X | | | X | |
X | | |
| Text 12 |
X | | | X | |
| X | |
| Text 13 |
X | X | | X | |
| | X |
| Text 14 |
X | X | | | X |
| X | X |
A Procrustean approach
We can analyse the variation:
| |
Tag 1 | Tag 4 | Tag 2 | Tag 3 | Tag 5 |
Tag 6 | Tag 7 | Tag 8 |
| Text 2 |
X | X | X | X | |
| | |
| Text 6 |
X | X | X | | |
| | X |
| Text 9 |
X | X | X | X | |
| | |
| Text 13 |
X | X | X | | |
| | X |
| Text 3 |
X | X | | | |
| | |
| Text 4 |
X | X | | | |
X | | |
| Text 5 |
X | X | | | |
| X | |
| Text 10 |
X | X | | | |
| | |
| Text 11 |
X | X | | | |
X | | |
| Text 12 |
X | X | | | |
| X | |
| Text 1 |
X | | X | | |
| | |
| Text 7 |
X | | X | | X |
| X | X |
| Text 8 |
X | | X | | |
| | |
| Text 14 |
X | | X | | X |
| X | X |
Now it's simple
And trim it away. Now it's simple.
| |
Tag 1 | Tag 4 | Tag 2 |
| Text 2 |
X | X | X |
| Text 6 |
X | X | X |
| Text 9 |
X | X | X |
| Text 13 |
X | X | X |
| Text 3 |
X | X | |
| Text 4 |
X | X | |
| Text 5 |
X | X | |
| Text 10 |
X | X | |
| Text 11 |
X | X | |
| Text 12 |
X | X | |
| Text 1 |
X | | X |
| Text 7 |
X | | X |
| Text 8 |
X | | X |
| Text 14 |
X | | X |
A better approach
Two incompatible goals?
Try
two solutions:
One common interface (‘least common denominator’)
for entire collection.
E.g. all texts consist of book, chapter,
paragraph.
Cf. Arras (John B. Smith, ca. 1980):
- text, chapter, paragraph, sentence, word
- text, volume, page, line, word
Specialized interfaces for subcollections with consistent content / tagging.
Multiple UIs?
Some user-interface specialists* recommend
multiple user interfaces.
- Different users work differently.
- Each user works differently at different times.
- Multiple interfaces → clean separation of UI and back end.
* See e.g. N. Borenstein, Programming as if people mattered.
But how do we make that work?
A simple solution
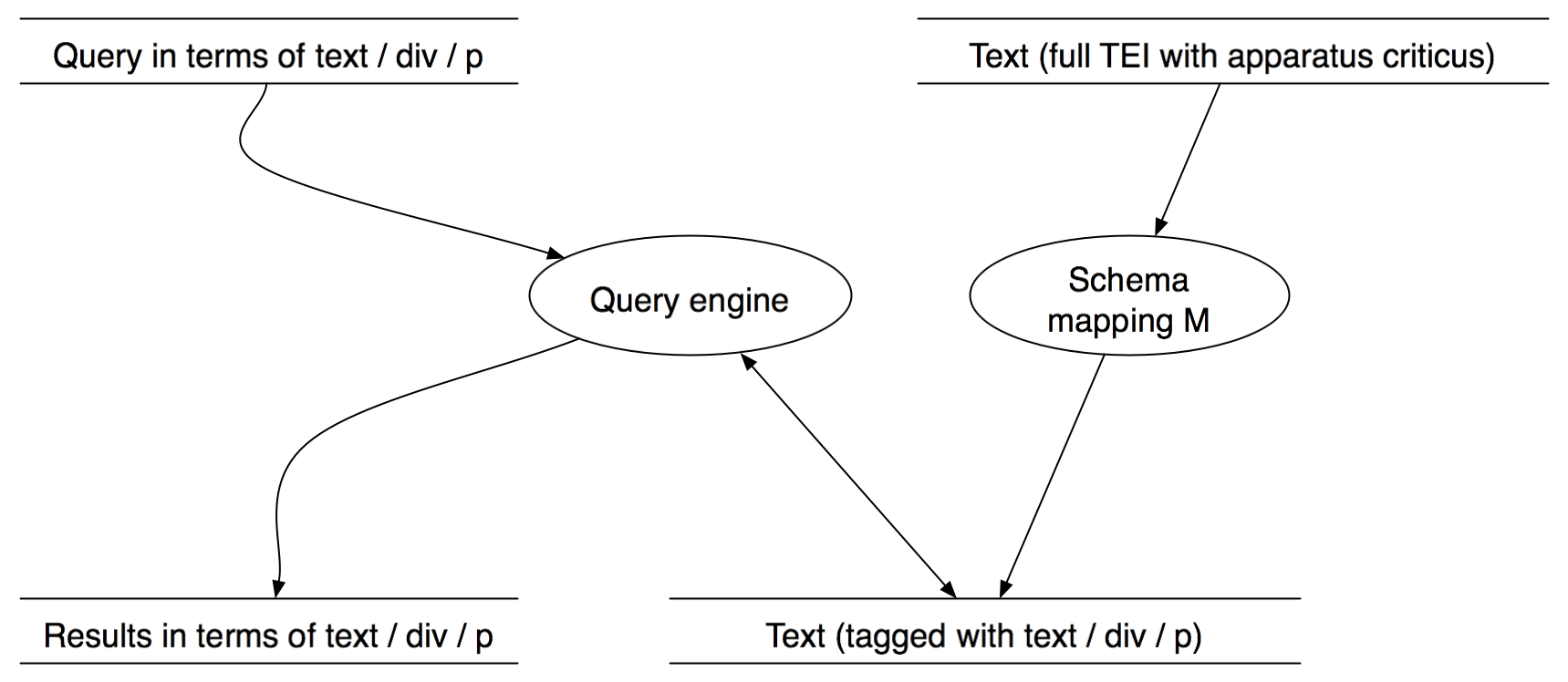
The simplest solution is brute force.
- Transform the data.
- Keep the original.
- Keep the copy.
- Buy a larger disk.
“If brute force is not working,
you're not applying enough brute force.” -Norm Walsh
A cleverer solution
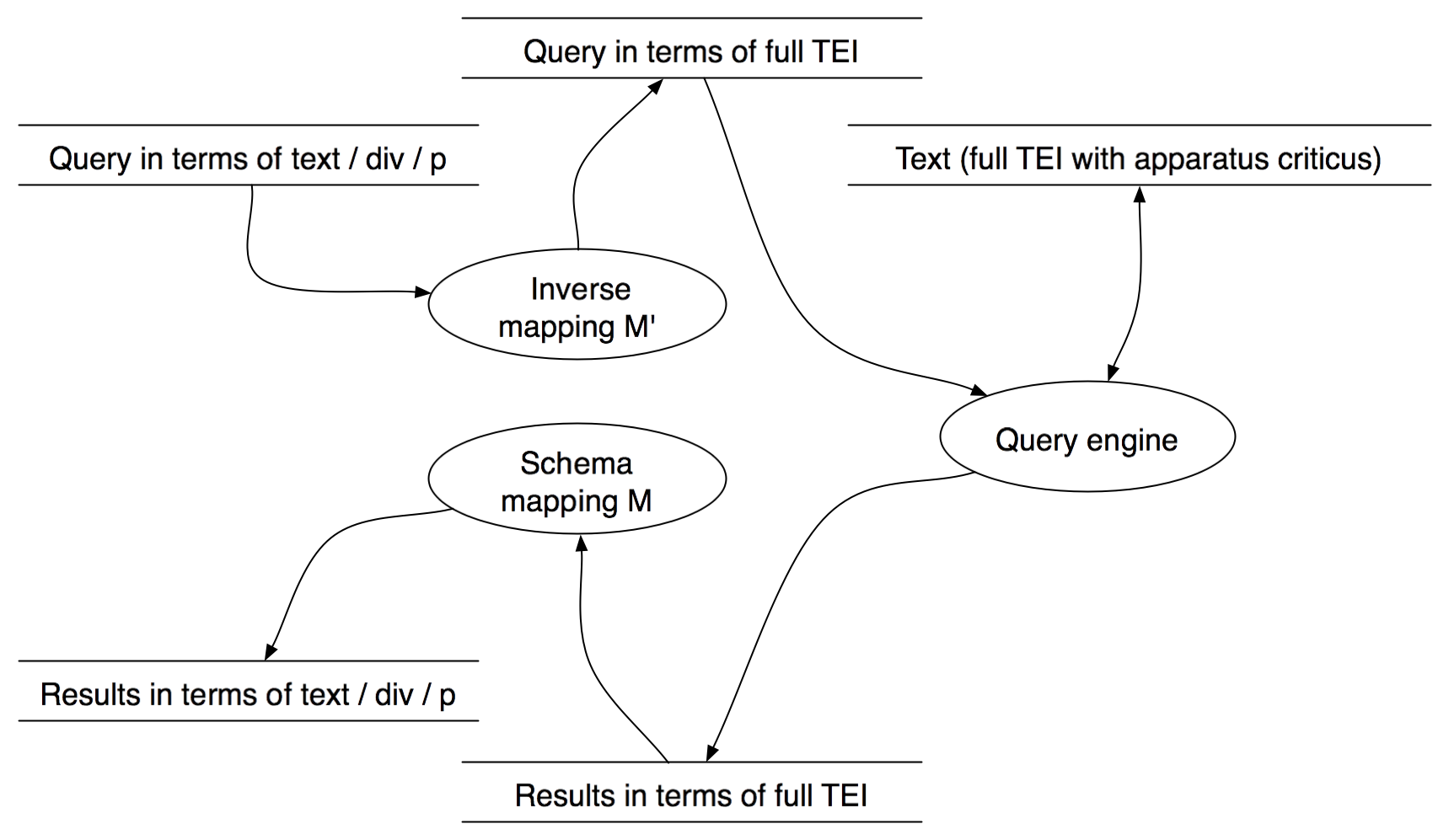
Invert the mapping and apply to query.
When are mappings reversible?
Obvious answer: when they lose no information.
- ... but how do we define that, in turn?
- M · M' = identity
Some obvious cases:
- isomorphism (rename, keep structure)
- structural filtering (untag selected elements)
Less obvious cases
- structural filtering (remove selected elements)
— problems for proximity searches?
- context-dependent mapping
(body/div/head → h1,
body/div/div/head → h2,
body/div/div/div/head → h3, etc.)
Related work in database theory
Schema mapping for relations has occupied some very bright minds.
Summary: Gosh, that's hard!
Also a topic in RDF-based data integration.
Summary: if you keep it simple, it can be simple.
Mapping inversion ≠ query inversion
It may not be as bad as it looks.
- Even lossy mappings can be query-reversible:
- Map emph,
foreign,
mentioned,
hi →
em.
- Query //hi →
//*[self::emph
or self::foreign
or self::mentioned
or self::hi]
- Reverse mapping may overgenerate, and excess results
may be filtered out later in user (target) schema.
- N.B. mapping must cover the documents present,
not necessarily all documents in the source schema.
Mapping inversion ≠ query inversion 2
It may be worse than it looks.
- Results in isolation may lack context necessary
to filter out excess hits (or translate correctly).
Shorter term practice
- Materialize the UI-specific views as needed. (Disk is cheap.)
- Assign stable identifiers to elements.
- Keep IDs aligned in all versions.
- Keep clear which version is the master copy.
- Derive all other copies mechanically from the master.
Longer term challenge
Understanding document-schema mappings:
when are they
- reversible?
- query-reversible?
- applicable to results out of context?
For now, inversion of arbitrary XSLT infeasible.
But particular transformations are clearly reversible
in general, or for querying.
Are there suitable subsets? Alternative formalisms?
There is a lot to learn here.