[29 June 2009; subheads added 30 June 2009]
Last week I was at the University of Maryland attending Digital Humanities 2009, the annual joint conference of the Association for Computers and the Humanities (ACH), the Association for Literary and Linguistic Computing (ALLC), and the Society for Digital Humanities / Société pour l’étude des médias interactifs (SDH/SEMI) — the constituent societies of the Association of Digital Humanities Organizations. It had a fine concentration of digital humanists, ranging from stylometricians and adepts of authorship attribution to theorists of video games (this is a branch of cultural and medial studies, not to be confused with the game theory of von Neumann and Morgenstern — there may be a promotional opportunity in the slogan “Not your grandfather’s game theory!”, but I’ll let others take it up).
I saw a number of talks; some of the ones that stick in my mind are these.
Rockwell / Sinclair on Knowledge radio
Geoffrey Rockwell (Univ. of Alberta) and Stefán Sinclair (McMaster U.) talked about “Animating the knowledge radio” and showed how one could lower the threshold of text analysis by processing raw streams of data without requiring that it be indexed first. The user’s wait while the stream is being processed can be made bearable, and perhaps even informative, by animating the processing being performed. In one of their examples, word clouds of the high-frequency words in a text are created, and the cloud changes as new words are read in and the list of most-frequent words changes. The analogy with radio (as a stream you tap into without saving it to disk first) is arresting and may have potential for doing more work than they currently make it do. I wonder, too, whether going forward their analysis would benefit by considering current work on continuous queries (a big topic in database research and practice today) or streaming query processors (more XQuery processors act on streams than act on static indexed data). Bottom line: the visuals were pretty and the discipline of making tools work on streams appears to be beneficial.
Roued, Cayless, Stokes on paleography and the reading of manuscripts
Henriette Roued (Oxford) spoke on an Interpretation Support System she is building in company with others, to help readers and editors of ancient documents keep track of cruces, conjectures, arguments in favor of this or that reading of a crux, and so on. It was very impressive stuff. In the same session, Hugh Cayless (NYU) sketched out a kind of theoretical framework for the annotation of manuscript images, starting from a conventional scan, processing it into a page full of SVG paths, and attempting from that to build up a web of links connecting transcriptions to the image at the word token and line levels. This led to various hallway and lunchroom conversations about automatic detection of page structure, or mise en page, about which I know mostly that there are people who have studied it in some detail and whose results really ought to be relevant here. The session ended with Peter Stokes (Cambridge) talking about the past and future of computer-aided paleography. Among them, the three speakers seemed to have anticipated a good deal of what Claus Huitfeldt, Yves Marcoux, and I were going to say later in the week, and their pictures were nicer. This could have been depressing. But we decided to take this fact as a confirmation that our topic really is relevant.
One thing troubles me a bit. Both Roued and Cayless seem to take as a given that the regions of a document containing basic tokens provide a tessellation of the page; surely this is an oversimplification. It is perhaps true for most typewritten pages using the Roman alphabet, if they have no manuscript additions, but high ascenders, low descenders, complex scribal abbreviations, even printers’ ligatures all seem to require or suggest that it might be wise to assume that the regions occupied by basic tokens might overlap each other. (Not to mention the practice in times of paper shortage of overwriting the page with lines at right angles to the first set. And of course there are palimpsests.) And in pages with a lot of white space, it doesn’t seem obvious to me that all of the whitespace need be accounted for in the tabulation of basic tokens.
Bradley on the contributions of technical specialists to interdisciplinary projects
John Bradley (King’s College London) closed (my experience of) the first day of the conference by presenting a thought-provoking set of reflections on the contribution of specialists in digital humanities to projects undertaken jointly with humanists who are not particularly focused on the digital (analog humanists?). Of course, in my case he was preaching to the choir, but his arguments that those who contribute to the technical side of such projects should be regarded as partners, not as factotums, ought to be heeded by everyone engaged in interdisciplinary projects. Those who have ears to hear, let them hear.
Pierazzo on diplomatic editions
One of the high points of the conference for me was a talk on Wednesday by Elena Pierazzo (King’s College London), who spoke under the title “The limit of representation” about digital diplomatic editions, with particular reference to experience with a three-year project devoted to Jane Austen’s manuscripts of fiction. She spoke eloquently and insightfully about the difference between transcriptions (even diplomatic transcriptions) and the original, and about the need to choose intelligently when to capture some property of the original in a diplomatic edition and when to gesture instead toward the facsimile or leave the property uncaptured. This is a quiet step past Thomas Tanselle’s view (Studies in Bibliography 31 [1978]) that “the editor’s goal is to reproduce in print as many of the characteristics of the document as he can” — the history of digital editions, short as it is, provides plenty of examples to illustrate the proposition that editorial decisions should be driven by the requirements of the material and of the intended users of the edition, not (as in Tanselle’s view) by technology.
Ruecker and Galey on hermeneutics of design
Stan Ruecker (U. Albert) and Alan Galey (Toronto) gave a paper on “Design as a hermeneutic process: Thinking through making from book history to critical design” which I enjoyed a great deal, and think I learned a lot from, but which appears to defy paraphrase. After discussing the competing views that design should be the handmaiden of content and that design can and should itself embody an argument, they considered several examples, reading each as the embodiment of an argument, elucidating the work and the argument, and critiquing the embodiment. It gave me a pleasure much like that of sitting in on a master class in design.
Huitfeldt, Marcoux, and Sperberg-McQueen on transcription
In the same session (sic), Claus Huitfeldt (Univ. of Bergen), Yves Marcoux (Univ. de Montréal), and I gave our paper on “What is transcription? part 2”; the slides are on the Web.
Rockwell and Day, Memento mori for projects
The session concluded with a presentation by Geoff Rockwell (again! and still at Alberta) and Shawn Day (Digital Humanities Observatory, RIA Dublin) called “Burying dead projects: Depositing the Globalization Compendium”. They talked about some of the issues involved in depositing digital work with archives and repositories, as illustrated by their experience with a several-year project to develop a collection of resources on globalization (the Globalization Compendium of the title). Deposit is, they said, a requirement for all projects funded by the Canadian Social Sciences and Humanities Research Council (SSHRC), and has been for some time, but the repositories they worked with were still working out the kinks in their processes, and their own initial plans for deposit were also subject to change (deposit of the material was, interestingly, from the beginning planned into the project schedule and budget, but in the course of the project they changed their minds about what “the material” to be deposited should include).
I was glad to hear the other talks in the session, but I never did figure out what the program committee thought these three talks had in common.
Caton on transcription and its collateral losses
On the final day of the conference, Paul Caton (National Univ. of Ireland, Galway) gave a talk on transcription, in which he extended the analysis of transcription which Claus Huitfeldt and I had presented at DH 2007 (later published in Literary & Linguistic Computing) to consider information beyond the sequence of graphemes presented by a transcription and its exemplar.
There are a number of methodological and terminological pitfalls here, which mean caution is advised. For example, we seem to have different ideas about the meaning of the term token, which some people use to denote a concrete physical object (or distinguishable part of an object), but which Paul seems to use to denote a particular glyph or graphetic form. And is the uppercase / lowercase distinction of English to be taken as graphemic? I think the answer is yes (changing the case of a letter does not always produce a minimal pair, but it sometimes does, which I think suffices); Paul explicitly says the answer is no.
Paul identifies, under the cover term modality, some important classes of information which are lost by (most) transcriptions: presentation modality (e.g. font shifts), accidental modality (turned letters, malformed letters, broken type, even incorrect letters and words out of sequence), and temporal modality (the effects of time upon a document).
I think that some of the phenomena he discusses can in fact be treated as extensions of the set of types used to read and transcribe a document, but that raises thorny questions to which I do not have the answer. I think Paul has placed his finger upon a sore spot in the analysis of types and tokens: the usual view of the types instantiated by tokens is that we have a flat unstructured set of them, but as the examples of upper- and lower-case H, roman, italic, and bold instances of the word here, and other examples (e.g. long and short s, i/j, v/u) illustrate, the types we use in practice often do not form a simple flat set in which the identity of the type is the only salient information: often types are related in special ways. We can say, for purposes of analysis and discussion, that a set of types which merges upper and lower case, on the one had, and one which distinguishes them, on the other, are simply two different sets of types. But then, in practice, we operate not with one type system but with several, and the relations among type systems become a topic of interest. In particular, it’s obvious that some sets of types subsume others, and conversely that some are refinements of others. It’s not obvious that subsumption / refinement is the only relation among typesets that is worth worrying about. I assume that phonology has similar issues, both with identifying phonemes and with choosing the level of detail for phonetic transcriptions, but I know too little of phonology to be able to identify useful morals for application here.
What, no markup theory?
Looking back over this trip report, I notice that I haven’t mentioned any talks on markup theory or practice. Partly this reflects the program: a lot of discussions of markup theory seem to have migrated from the Digital Humanities conference to the Balisage conference. But partly it’s illusory: there were plenty of mentions of markup, markup languages, and so on. Syd Bauman and Dot Porter talked about the challenge of improving the cross referencing of the TEI Guidelines, and many talks mentioned their encoding scheme explicitly (usually the TEI). The TEI appears to be in wide use, and some parts of the TEI which have long been neglected appear to be coming into their own: Jan Christoph Meister of Hamburg and his students have built an annotation system (CATMA) based on TEI feature structures, and at least one other poster or paper also applied feature structures to its problem. Several people also mentioned standoff markup (though when one otherwise interesting presenter proposed using character offsets as the way to point into a base text, I left quietly to avoid screaming at him during the question session).
The hallway conversations were also very rewarding this year. Old friends and new ones were present in abundance, and I made some new acquaintances I look forward to renewing at future DH conferences. The twitter stream from the conference was also abundant (archive); not quite as active as an IRC channel during a typical W3C meeting, but quite respectable nonetheless.
All in all, the local organizers at the Maryland Institute for Technology in the Humanities, and the program committee, are to be congratulated. Good job!

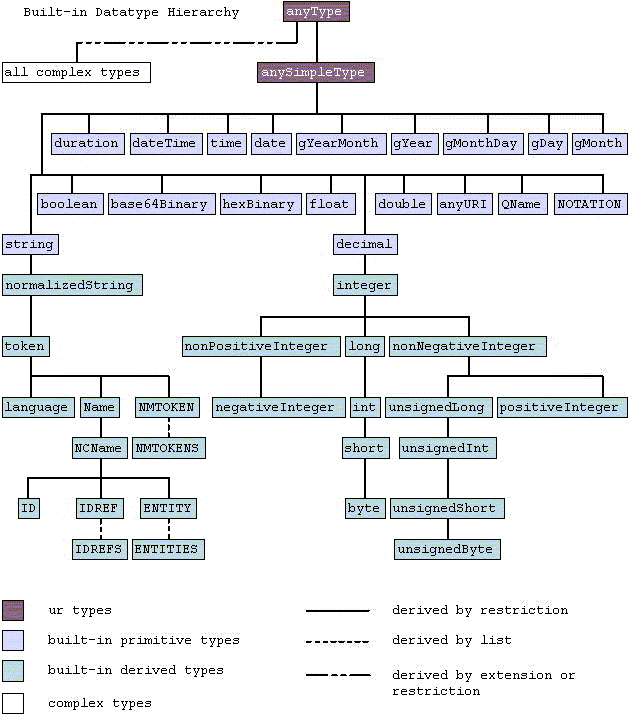 has simple color-coding to distinguish various classes of datatypes (what are now called the special datatypes, the primitives, and the other built-ins).
has simple color-coding to distinguish various classes of datatypes (what are now called the special datatypes, the primitives, and the other built-ins). which means you can try to ensure that the distinctions in your diagrams are visible also to readers with those forms of vision.
which means you can try to ensure that the distinctions in your diagrams are visible also to readers with those forms of vision.