[17 June 2009]
For some years now I have thought that the development of specs at places like W3C would benefit from the application of formal methods. Examples from the past few years illustrate (a) that I’m not alone in this thought, and (b) that it’s difficult to persuade a WG as a whole to adopt formal methods. Some WGs have published documents with formalizations of their spec in Z or in Gentzen calculus or in some other notation, but as far as I can tell most members of those WGs did not read those documents, let alone understand them, participate actively in their drafting and revision, or use the formalism as a way of working on or thinking about the design of the main spec. (And if I have understood what most proponents of formal methods have in mind, it’s really the last idea that some people regard as the main goal.) In most WGs I’ve been in, even the maintenance of a BNF in the spec, or the formal definition of an XML vocabulary, ends up being handled by a small minority of the group.
Part of the problem is the cost/benefit analysis. Most people in WGs don’t have any real grasp of or skill with any tool in the formal-methods toolbox.
[Enrique nudged my elbow here and said “Speak for yourself!” “Oh, I do,” I said. I use Alloy and enjoy it, but my command of Alloy is very weak compared to my command of most of the programming languages I use. And ACL2? Otter? HOL? “Ha,” muttered Enrique. “In your dreams.”]
And many formal tools look rather forbidding at first glance. And second glance.
[“How about, tenth glance?” said Enrique. “You have, what, ten books on Z on your shelf —” [yep, I just counted] “— quick, what does an arrow with a double head, no tail, and a cross mean?” “Er,” I said. “Come on, smart guy! Partial function? Total function? Total injection? Partial injection? Fuel injection? Which?” “Oh, hush.” (For the record, double head, no tail, and cross mean it’s a partial surjection. “Surjection?” asked Enrique. “What’s that?” “I can’t tell you; it’s a secret.” “A secret?” “I mean, look it up yourself.”)]
So a WG perceives a real cost, including a possibly steep learning curve and the real chance of appearing ignorant and foolish in front of colleagues. Alloy does its best to address this problem with (a) a non-forbidding syntax and (b) some chances of very fast payoff, so the learning curve is really not so steep. But it’s still a learning curve.
And the benefit? What benefits will accrue if my WG uses formal methods?
This is one place where I think formal methods proponents could do better. They always show you nifty uses of the tool to prove correctness of a design; it might be more persuasive if they showed you (a) a design plausible enough to make you say “yeah, that looks all right” and then (b) a failure to prove it correct, because of a flaw in the design, followed by (c) a fix and (d) a proof of correctness for the repaired design.
Here, too, Alloy does a good job: Daniel Jackson’s book includes the claim “Transitive closure is not axiomatizable in first-order logic”, with an exercise that involves first trying to axiomatize transitive closure in Alloy [which is first-order] and then using Alloy to find the flaw. “Now execute the command, examine the counterexample, and explain what the bug is. The official definition of UML 1.0 had this problem.” I’d like more examples like that!
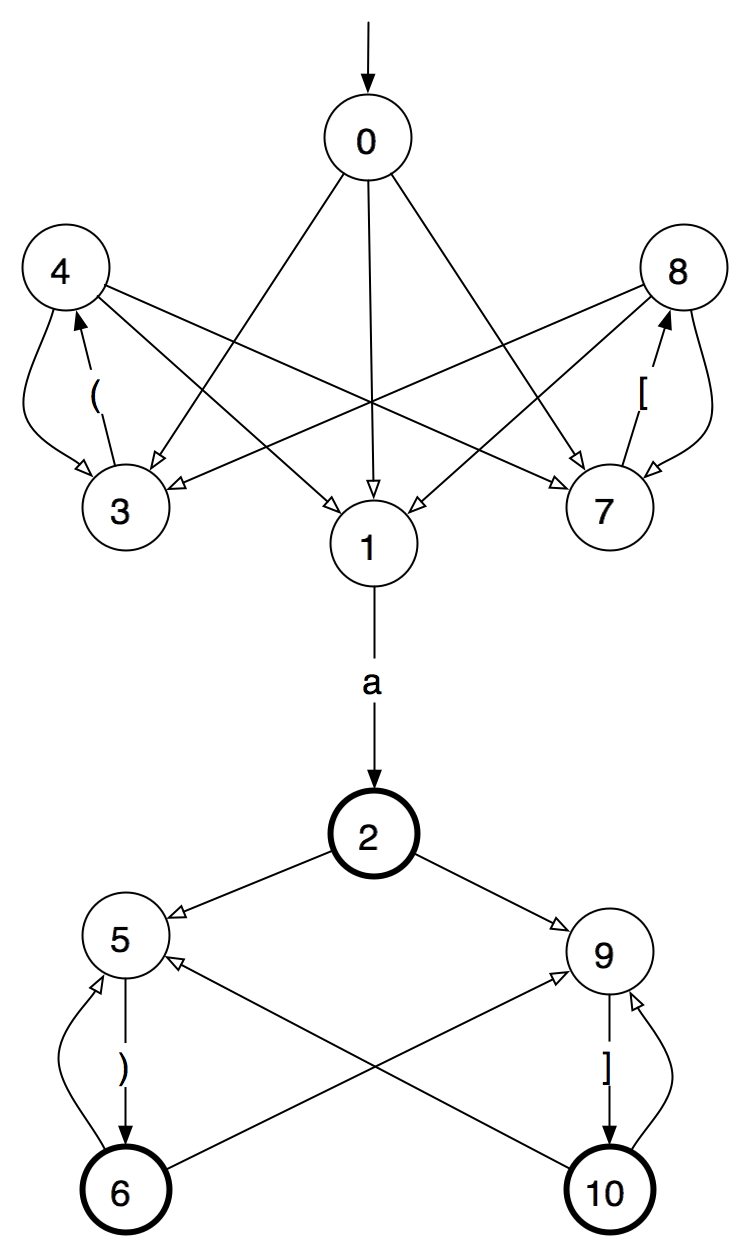
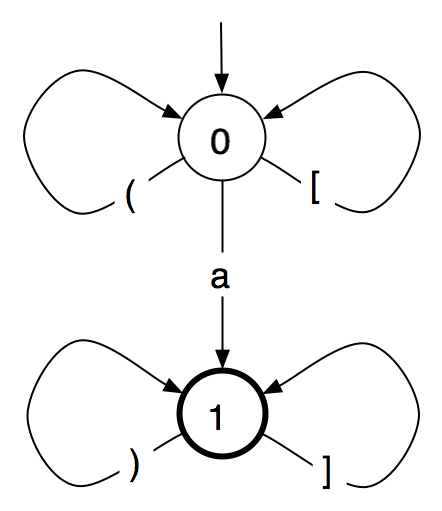
This morning I found myself once more wishing, for a very specific reason, that I had a good formal model of XSD 1.1. It might or might not persuade an entire WG, but it certainly illustrates the kind of situation where I think WGs might find formal methods to their advantage.
What happened is that Tony Coates raised an issue against XSD 1.1 relating to all-groups and named model groups. The details are not important for this discussion, but the upshot is simple: (1) I think Tony has identified a real and unintended flaw in XSD, (2) I think there is a relatively straightforward fix for the flaw, and (3) I am deeply frightened by the prospect of changing the spec to include that fix now, at this stage of its development. Why? Because I can see too clearly the possibility that in making what looks like a straightforward change we might break something else which depends on what we are changing but which we overlook.
[“You wouldn’t be speaking from experience here, would you?” sneered Enrique, digging his elbow hard into my ribs. Let’s just say that here are several corrections to XSD 1.0 which themselves introduced errors. And yes, I’m embarrassed by them. But it’s not just XSD: the phenomenon is also familiar from programming. “Yeah, yeah,” said Enrique. “Spread the blame. It’s not so bad, because everybody else does it, too? Haven’t you ever heard of the Categorical Imperative?” “I told you to hush! If you can’t be quiet, you’ll have to wait outside.”]
When you get to the point where you don’t want to fix a problem because you’re afraid you’ll just break something else, then you are well on the way to paralysis.
For software, one answer to incipient paralysis is to have a good suite of regression tests. Make the change, run the regression tests, and if all the tests pass, you can feel more confident that you didn’t break things.
The reason I am wishing, today, that I had a good formal model of XSD is that formal models can serve as a kind of regression test suite for prose specs. You have a model, you’ve proven that the spec has this and that property, and that operation X on example Y produces result Z. Now you’re considering a change to the design. Make the corresponding change to the model, and check: does it still have this and that property? Does X(Y) still evaluate to Z? Mechanized systems can make it much easier to check that specified properties of a design are stable in the face of a given change. In Alloy, I find it helpful to re-check all assertions after a significant change to the model (or at least the assertions I think might be affected); Alloy makes that easy. In ACL2, similarly, you can have a set of theorems with proof scripts (including a theorem that proves that the value of X(Y) is Z) and re-run them automatically after changes.
I begin to suspect that a key advantage of formal methods is not just being able to prove that a design has certain properties, but being able to re-prove that the design has those properties, again and again, each time you revise it. So you can make sure that changing this little bit over here didn’t suddenly cause a catastrophic failure in that bit over there.
As Matt Kaufmann, Panagiotis Manolios, and J. Strother Moore put it in the introduction to Computer-aided reasoning: ACL2 case studies ([n.p.: n.p.], 2002), describing a project at Motorola:
Because the design was under constant evolution during the period, the formal models were also under constant evolution and “the” equivalence theorem [that is, a key result in establishing that the microcode worked correctly] was proved many times. This highlights the advantage of developing general proof strategies…. It also highlights the utility of having a good inference engine: minor changes in the theorem being proved do not necessarily disrupt the proof replay.
If formal methods can help us design robust specs, they will be a huge help. But they can be helpful even in working with brittle specs, the kind where changing one thing here can easily break something over there. When we work with such a spec, formal methods can help ensure that we know at once if a change breaks something, so we can avoid making that change in the normative version of the spec. (I’m pretty sure that this was one advantage of the work the CICS group at IBM’s Hursley Laboratory did when they specified parts of CICS in Z. It will have made it a bit easier to contemplate the possibility of changes to the interface if you could prove that the changes would retain the properties you cared most about keeping.)
Of course, if you use formal methods a lot, you can hope that you will learn how to make your designs more robust and cleaner. That’s part of the selling proposition for Alloy, at least. But even for those of us whose designs are sometimes, ah, not as robust as we would like, a formalization of an existing design can be a help in maintenance.